 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkywork UniPic 3.0: Unified Multi-Image Composition via Sequence Modeling
Jan 22, 2026The recent surge in popularity of Nano-Banana and Seedream 4.0 underscores the community's strong interest in multi-image composition tasks. Compared to single-image editing, multi-image composition presents significantly greater challenges in terms of consistency and quality, yet existing models have not disclosed specific methodological details for achieving high-quality fusion. Through statistical analysis, we identify Human-Object Interaction (HOI) as the most sought-after category by the community. We therefore systematically analyze and implement a state-of-the-art solution for multi-image composition with a primary focus on HOI-centric tasks. We present Skywork UniPic 3.0, a unified multimodal framework that integrates single-image editing and multi-image composition. Our model supports an arbitrary (1~6) number and resolution of input images, as well as arbitrary output resolutions (within a total pixel budget of 1024x1024). To address the challenges of multi-image composition, we design a comprehensive data collection, filtering, and synthesis pipeline, achieving strong performance with only 700K high-quality training samples. Furthermore, we introduce a novel training paradigm that formulates multi-image composition as a sequence-modeling problem, transforming conditional generation into unified sequence synthesis. To accelerate inference, we integrate trajectory mapping and distribution matching into the post-training stage, enabling the model to produce high-fidelity samples in just 8 steps and achieve a 12.5x speedup over standard synthesis sampling. Skywork UniPic 3.0 achieves state-of-the-art performance on single-image editing benchmark and surpasses both Nano-Banana and Seedream 4.0 on multi-image composition benchmark, thereby validating the effectiveness of our data pipeline and training paradigm. Code, models and dataset are publicly available.
Skywork UniPic 2.0: Building Kontext Model with Online RL for Unified Multimodal Model
Sep 04, 2025

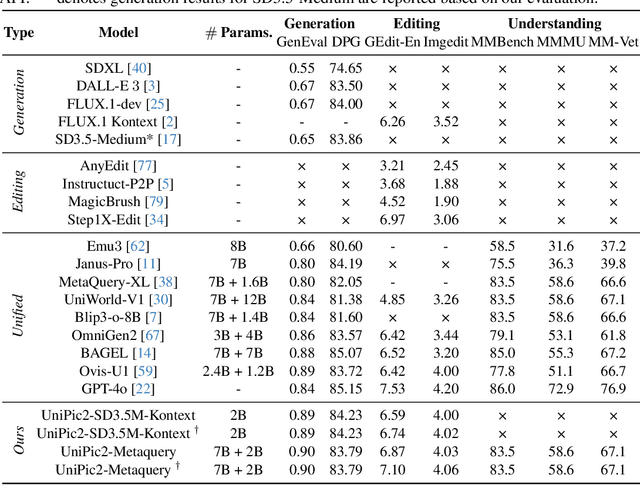
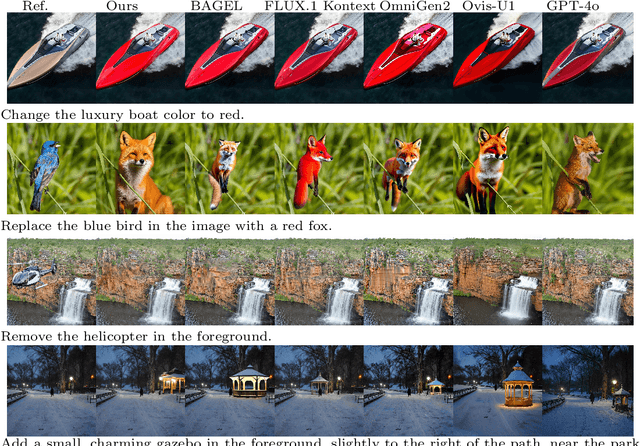
Recent advances in multimodal models have demonstrated impressive capabilities in unified image generation and editing. However, many prominent open-source models prioritize scaling model parameters over optimizing training strategies, limiting their efficiency and performance. In this work, we present UniPic2-SD3.5M-Kontext, a 2B-parameter DiT model based on SD3.5-Medium, which achieves state-of-the-art image generation and editing while extending seamlessly into a unified multimodal framework. Our approach begins with architectural modifications to SD3.5-Medium and large-scale pre-training on high-quality data, enabling joint text-to-image generation and editing capabilities. To enhance instruction following and editing consistency, we propose a novel Progressive Dual-Task Reinforcement strategy (PDTR), which effectively strengthens both tasks in a staged manner. We empirically validate that the reinforcement phases for different tasks are mutually beneficial and do not induce negative interference. After pre-training and reinforcement strategies, UniPic2-SD3.5M-Kontext demonstrates stronger image generation and editing capabilities than models with significantly larger generation parameters-including BAGEL (7B) and Flux-Kontext (12B). Furthermore, following the MetaQuery, we connect the UniPic2-SD3.5M-Kontext and Qwen2.5-VL-7B via a connector and perform joint training to launch a unified multimodal model UniPic2-Metaquery. UniPic2-Metaquery integrates understanding, generation, and editing, achieving top-tier performance across diverse tasks with a simple and scalable training paradigm. This consistently validates the effectiveness and generalizability of our proposed training paradigm, which we formalize as Skywork UniPic 2.0.
Matrix-3D: Omnidirectional Explorable 3D World Generation
Aug 11, 2025Explorable 3D world generation from a single image or text prompt forms a cornerstone of spatial intelligence. Recent works utilize video model to achieve wide-scope and generalizable 3D world generation. However, existing approaches often suffer from a limited scope in the generated scenes. In this work, we propose Matrix-3D, a framework that utilize panoramic representation for wide-coverage omnidirectional explorable 3D world generation that combines conditional video generation and panoramic 3D reconstruction. We first train a trajectory-guided panoramic video diffusion model that employs scene mesh renders as condition, to enable high-quality and geometrically consistent scene video generation. To lift the panorama scene video to 3D world, we propose two separate methods: (1) a feed-forward large panorama reconstruction model for rapid 3D scene reconstruction and (2) an optimization-based pipeline for accurate and detailed 3D scene reconstruction. To facilitate effective training, we also introduce the Matrix-Pano dataset, the first large-scale synthetic collection comprising 116K high-quality static panoramic video sequences with depth and trajectory annotations. Extensive experiments demonstrate that our proposed framework achieves state-of-the-art performance in panoramic video generation and 3D world generation. See more in https://matrix-3d.github.io.
MGSR: 2D/3D Mutual-boosted Gaussian Splatting for High-fidelity Surface Reconstruction under Various Light Conditions
Mar 07, 2025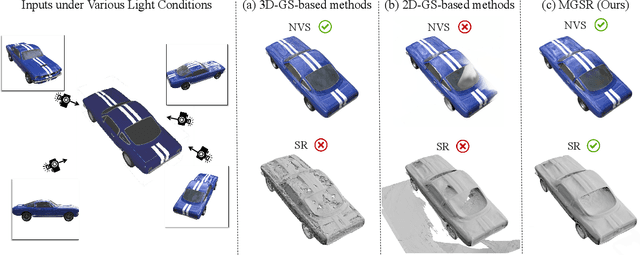
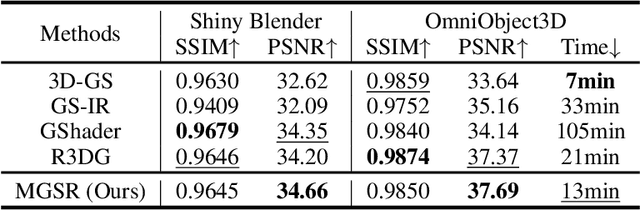
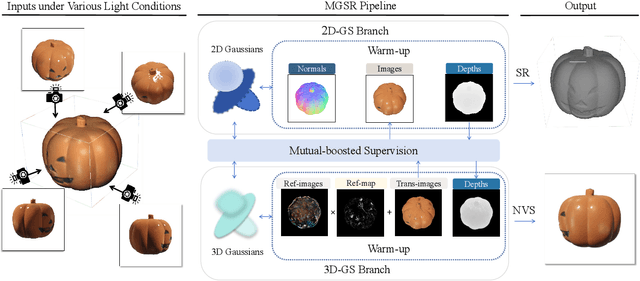

Novel view synthesis (NVS) and surface reconstruction (SR) are essential tasks in 3D Gaussian Splatting (3D-GS). Despite recent progress, these tasks are often addressed independently, with GS-based rendering methods struggling under diverse light conditions and failing to produce accurate surfaces, while GS-based reconstruction methods frequently compromise rendering quality. This raises a central question: must rendering and reconstruction always involve a trade-off? To address this, we propose MGSR, a 2D/3D Mutual-boosted Gaussian splatting for Surface Reconstruction that enhances both rendering quality and 3D reconstruction accuracy. MGSR introduces two branches--one based on 2D-GS and the other on 3D-GS. The 2D-GS branch excels in surface reconstruction, providing precise geometry information to the 3D-GS branch. Leveraging this geometry, the 3D-GS branch employs a geometry-guided illumination decomposition module that captures reflected and transmitted components, enabling realistic rendering under varied light conditions. Using the transmitted component as supervision, the 2D-GS branch also achieves high-fidelity surface reconstruction. Throughout the optimization process, the 2D-GS and 3D-GS branches undergo alternating optimization, providing mutual supervision. Prior to this, each branch completes an independent warm-up phase, with an early stopping strategy implemented to reduce computational costs. We evaluate MGSR on a diverse set of synthetic and real-world datasets, at both object and scene levels, demonstrating strong performance in rendering and surface reconstruction.
Topology-Aware Latent Diffusion for 3D Shape Generation
Jan 31, 2024We introduce a new generative model that combines latent diffusion with persistent homology to create 3D shapes with high diversity, with a special emphasis on their topological characteristics. Our method involves representing 3D shapes as implicit fields, then employing persistent homology to extract topological features, including Betti numbers and persistence diagrams. The shape generation process consists of two steps. Initially, we employ a transformer-based autoencoding module to embed the implicit representation of each 3D shape into a set of latent vectors. Subsequently, we navigate through the learned latent space via a diffusion model. By strategically incorporating topological features into the diffusion process, our generative module is able to produce a richer variety of 3D shapes with different topological structures. Furthermore, our framework is flexible, supporting generation tasks constrained by a variety of inputs, including sparse and partial point clouds, as well as sketches. By modifying the persistence diagrams, we can alter the topology of the shapes generated from these input modalities.
Robust Geometry and Reflectance Disentanglement for 3D Face Reconstruction from Sparse-view Images
Dec 11, 2023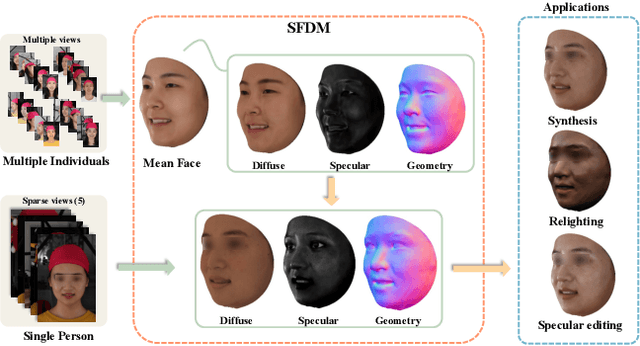
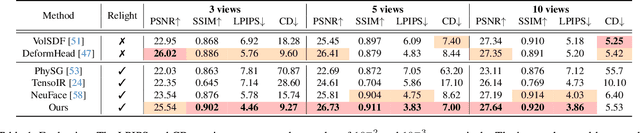
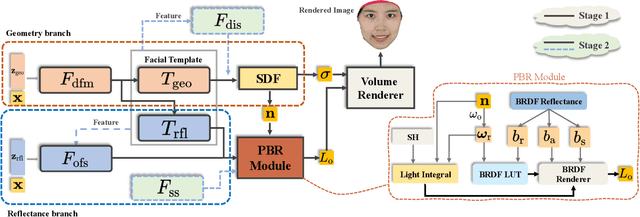
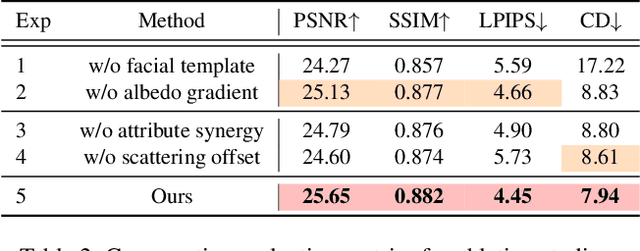
This paper presents a novel two-stage approach for reconstructing human faces from sparse-view images, a task made challenging by the unique geometry and complex skin reflectance of each individual. Our method focuses on decomposing key facial attributes, including geometry, diffuse reflectance, and specular reflectance, from ambient light. Initially, we create a general facial template from a diverse collection of individual faces, capturing essential geometric and reflectance characteristics. Guided by this template, we refine each specific face model in the second stage, which further considers the interaction between geometry and reflectance, as well as the subsurface scattering effects on facial skin. Our method enables the reconstruction of high-quality facial representations from as few as three images, offering improved geometric accuracy and reflectance detail. Through comprehensive evaluations and comparisons, our method demonstrates superiority over existing techniques. Our method effectively disentangles geometry and reflectance components, leading to enhanced quality in synthesizing new views and opening up possibilities for applications such as relighting and reflectance editing. We will make the code publicly available.
Identity-Obscured Neural Radiance Fields: Privacy-Preserving 3D Facial Reconstruction
Dec 07, 2023



Neural radiance fields (NeRF) typically require a complete set of images taken from multiple camera perspectives to accurately reconstruct geometric details. However, this approach raise significant privacy concerns in the context of facial reconstruction. The critical need for privacy protection often leads invidividuals to be reluctant in sharing their facial images, due to fears of potential misuse or security risks. Addressing these concerns, we propose a method that leverages privacy-preserving images for reconstructing 3D head geometry within the NeRF framework. Our method stands apart from traditional facial reconstruction techniques as it does not depend on RGB information from images containing sensitive facial data. Instead, it effectively generates plausible facial geometry using a series of identity-obscured inputs, thereby protecting facial privacy.
Bi-directional Deformation for Parameterization of Neural Implicit Surfaces
Oct 09, 2023The growing capabilities of neural rendering have increased the demand for new techniques that enable the intuitive editing of 3D objects, particularly when they are represented as neural implicit surfaces. In this paper, we present a novel neural algorithm to parameterize neural implicit surfaces to simple parametric domains, such as spheres, cubes or polycubes, where 3D radiance field can be represented as a 2D field, thereby facilitating visualization and various editing tasks. Technically, our method computes a bi-directional deformation between 3D objects and their chosen parametric domains, eliminating the need for any prior information. We adopt a forward mapping of points on the zero level set of the 3D object to a parametric domain, followed by a backward mapping through inverse deformation. To ensure the map is bijective, we employ a cycle loss while optimizing the smoothness of both deformations. Additionally, we leverage a Laplacian regularizer to effectively control angle distortion and offer the flexibility to choose from a range of parametric domains for managing area distortion. Designed for compatibility, our framework integrates seamlessly with existing neural rendering pipelines, taking multi-view images as input to reconstruct 3D geometry and compute the corresponding texture map. We also introduce a simple yet effective technique for intrinsic radiance decomposition, facilitating both view-independent material editing and view-dependent shading editing. Our method allows for the immediate rendering of edited textures through volume rendering, without the need for network re-training. Moreover, our approach supports the co-parameterization of multiple objects and enables texture transfer between them. We demonstrate the effectiveness of our method on images of human heads and man-made objects. We will make the source code publicly available.
Deformable Model Driven Neural Rendering for High-fidelity 3D Reconstruction of Human Heads Under Low-View Settings
Mar 24, 2023
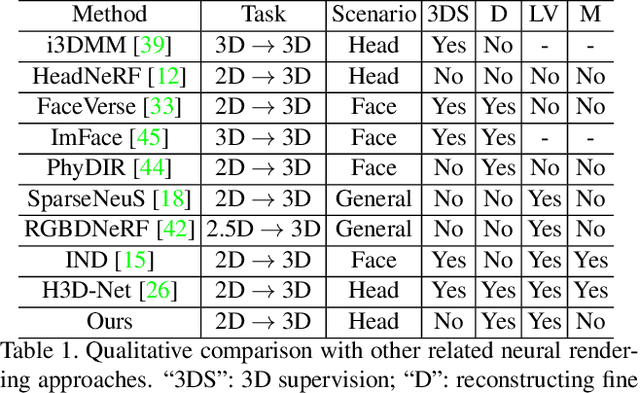
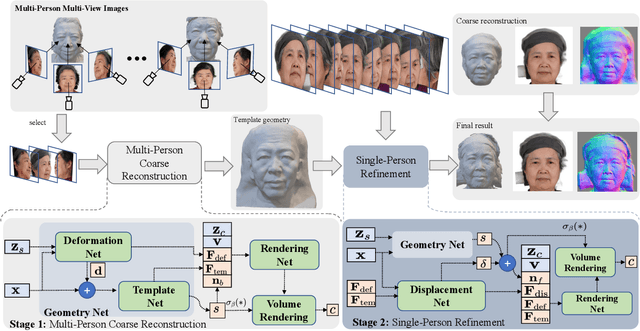

We propose a robust method for learning neural implicit functions that can reconstruct 3D human heads with high-fidelity geometry from low-view inputs. We represent 3D human heads as the zero level-set of a composed signed distance field that consists of a smooth template, a non-rigid deformation, and a high-frequency displacement field. The template represents identity-independent and expression-neutral features, which is trained on multiple individuals, along with the deformation network. The displacement field encodes identity-dependent geometric details, trained for each specific individual. We train our network in two stages using a coarse-to-fine strategy without 3D supervision. Our experiments demonstrate that the geometry decomposition and two-stage training make our method robust and our model outperforms existing methods in terms of reconstruction accuracy and novel view synthesis under low-view settings. Additionally, the pre-trained template serves a good initialization for our model to adapt to unseen individuals.