 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderwater360: Reconstructing Underwater Scenes from Panoramic Images with Omnidirectional Gaussian Splatting
May 26, 2026Underwater scene reconstruction is essential for immersive exploration of aquatic environments, yet remains challenging due to complex participating-media effects such as absorption and scattering, as well as the limited field of view (FoV) of conventional cameras. Although combining panoramic imaging with 3D Gaussian Splatting (3DGS) offers a promising direction for photorealistic underwater rendering, traditional 3DGS struggles with both spherical projection distortion and underwater medium degradation. In this paper, we propose \textbf{Underwater360}, a physics-informed omnidirectional 3DGS framework for underwater panoramic scene reconstruction. First, we introduce an Omnidirectional Gaussian Splatting module that performs ray casting directly in spherical camera space instead of relying on 2D projection approximations, thereby reducing geometric distortions under 360$^\circ$ FoV. Second, we design a physics-based appearance-medium modeling architecture with pose-conditioned appearance embeddings to explicitly decouple intrinsic scene radiance from depth-dependent backscatter and attenuation, enabling physically grounded scene appearance restoration. Finally, we establish a new panoramic underwater benchmark dataset containing both synthetic and real-world scenes. Extensive experiments demonstrate that Underwater360 achieves superior performance in underwater novel view synthesis and scene appearance restoration, delivering improved rendering quality and cross-view consistency in complex underwater environments. The code and datasets are released at https://github.com/SwcK423/Underwater360
PolycubeNet: A Dual-latent Diffusion Model for Polycube-Based Hexahedral Mesh Generation
May 19, 2026Hexahedral meshes are widely used in simulation pipelines, yet automatic generation remains challenging for complex CAD geometries. Polycube-based hexahedral meshing is a representative approach due to its regular, parameterization-friendly structure, but existing polycube construction methods often rely on intricate surface segmentation and local heuristics, which can produce artifacts or fail on difficult shapes. In this paper, we propose an end-to-end framework for polycube generation based on conditional diffusion models. Given an input geometry represented as a point cloud, our method directly produces a corresponding polycube point cloud, eliminating the need for explicit surface segmentation or predefined polycube templates. At the core of our approach is a dual-latent conditional diffusion architecture that confines computationally expensive self-attention operations to a fixed-capacity, low-dimensional latent space. This design effectively decouples computational complexity from the resolution of both the input geometry and the output polycube, thereby avoiding the quadratic cost typical of point cloud self-attention mechanisms while supporting flexible input and output resolutions. To obtain a hexahedral mesh, the generated polycube is aligned to the input shape via rigid and non-rigid point cloud registration to establish surface correspondence, followed by a polycube-to-hex pipeline. We additionally create and release a paired dataset of CAD meshes and their corresponding polycube meshes, together with the core implementation of our model. Experiments show that PolycubeNet generalizes to complex CAD models with arbitrary genus and produces high-quality polycube structures within seconds, improving robustness and efficiency over prior learning-based approaches.
Superpixel-Based Image Segmentation Using Squared 2-Wasserstein Distances
Jan 22, 2026We present an efficient method for image segmentation in the presence of strong inhomogeneities. The approach can be interpreted as a two-level clustering procedure: pixels are first grouped into superpixels via a linear least-squares assignment problem, which can be viewed as a special case of a discrete optimal transport (OT) problem, and these superpixels are subsequently greedily merged into object-level segments using the squared 2-Wasserstein distance between their empirical distributions. In contrast to conventional superpixel merging strategies based on mean-color distances, our framework employs a distributional OT distance, yielding a mathematically unified formulation across both clustering levels. Numerical experiments demonstrate that this perspective leads to improved segmentation accuracy on challenging images while retaining high computational efficiency.
A Survey of AI Methods for Geometry Preparation and Mesh Generation in Engineering Simulation
Dec 16, 2025Artificial intelligence is beginning to ease long-standing bottlenecks in the CAD-to-mesh pipeline. This survey reviews recent advances where machine learning aids part classification, mesh quality prediction, and defeaturing. We explore methods that improve unstructured and block-structured meshing, support volumetric parameterizations, and accelerate parallel mesh generation. We also examine emerging tools for scripting automation, including reinforcement learning and large language models. Across these efforts, AI acts as an assistive technology, extending the capabilities of traditional geometry and meshing tools. The survey highlights representative methods, practical deployments, and key research challenges that will shape the next generation of data-driven meshing workflows.
OT-ALD: Aligning Latent Distributions with Optimal Transport for Accelerated Image-to-Image Translation
Nov 14, 2025The Dual Diffusion Implicit Bridge (DDIB) is an emerging image-to-image (I2I) translation method that preserves cycle consistency while achieving strong flexibility. It links two independently trained diffusion models (DMs) in the source and target domains by first adding noise to a source image to obtain a latent code, then denoising it in the target domain to generate the translated image. However, this method faces two key challenges: (1) low translation efficiency, and (2) translation trajectory deviations caused by mismatched latent distributions. To address these issues, we propose a novel I2I translation framework, OT-ALD, grounded in optimal transport (OT) theory, which retains the strengths of DDIB-based approach. Specifically, we compute an OT map from the latent distribution of the source domain to that of the target domain, and use the mapped distribution as the starting point for the reverse diffusion process in the target domain. Our error analysis confirms that OT-ALD eliminates latent distribution mismatches. Moreover, OT-ALD effectively balances faster image translation with improved image quality. Experiments on four translation tasks across three high-resolution datasets show that OT-ALD improves sampling efficiency by 20.29% and reduces the FID score by 2.6 on average compared to the top-performing baseline models.
Robotic Manipulation via Imitation Learning: Taxonomy, Evolution, Benchmark, and Challenges
Aug 24, 2025



Robotic Manipulation (RM) is central to the advancement of autonomous robots, enabling them to interact with and manipulate objects in real-world environments. This survey focuses on RM methodologies that leverage imitation learning, a powerful technique that allows robots to learn complex manipulation skills by mimicking human demonstrations. We identify and analyze the most influential studies in this domain, selected based on community impact and intrinsic quality. For each paper, we provide a structured summary, covering the research purpose, technical implementation, hierarchical classification, input formats, key priors, strengths and limitations, and citation metrics. Additionally, we trace the chronological development of imitation learning techniques within RM policy (RMP), offering a timeline of key technological advancements. Where available, we report benchmark results and perform quantitative evaluations to compare existing methods. By synthesizing these insights, this review provides a comprehensive resource for researchers and practitioners, highlighting both the state of the art and the challenges that lie ahead in the field of robotic manipulation through imitation learning.
Point2Quad: Generating Quad Meshes from Point Clouds via Face Prediction
Apr 28, 2025Quad meshes are essential in geometric modeling and computational mechanics. Although learning-based methods for triangle mesh demonstrate considerable advancements, quad mesh generation remains less explored due to the challenge of ensuring coplanarity, convexity, and quad-only meshes. In this paper, we present Point2Quad, the first learning-based method for quad-only mesh generation from point clouds. The key idea is learning to identify quad mesh with fused pointwise and facewise features. Specifically, Point2Quad begins with a k-NN-based candidate generation considering the coplanarity and squareness. Then, two encoders are followed to extract geometric and topological features that address the challenge of quad-related constraints, especially by combining in-depth quadrilaterals-specific characteristics. Subsequently, the extracted features are fused to train the classifier with a designed compound loss. The final results are derived after the refinement by a quad-specific post-processing. Extensive experiments on both clear and noise data demonstrate the effectiveness and superiority of Point2Quad, compared to baseline methods under comprehensive metrics.
Diff-CL: A Novel Cross Pseudo-Supervision Method for Semi-supervised Medical Image Segmentation
Mar 12, 2025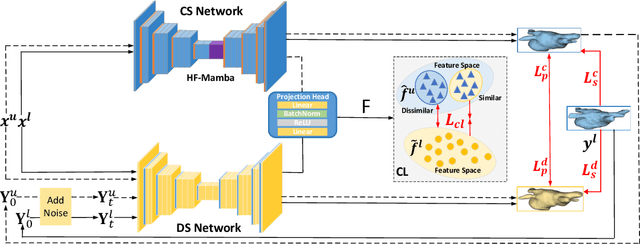

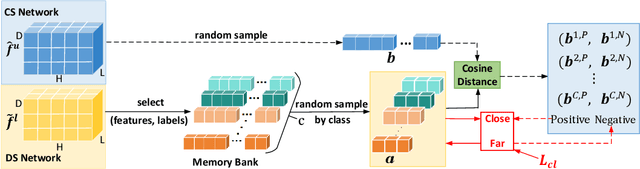

Semi-supervised learning utilizes insights from unlabeled data to improve model generalization, thereby reducing reliance on large labeled datasets. Most existing studies focus on limited samples and fail to capture the overall data distribution. We contend that combining distributional information with detailed information is crucial for achieving more robust and accurate segmentation results. On the one hand, with its robust generative capabilities, diffusion models (DM) learn data distribution effectively. However, it struggles with fine detail capture, leading to generated images with misleading details. Combining DM with convolutional neural networks (CNNs) enables the former to learn data distribution while the latter corrects fine details. While capturing complete high-frequency details by CNNs requires substantial computational resources and is susceptible to local noise. On the other hand, given that both labeled and unlabeled data come from the same distribution, we believe that regions in unlabeled data similar to overall class semantics to labeled data are likely to belong to the same class, while regions with minimal similarity are less likely to. This work introduces a semi-supervised medical image segmentation framework from the distribution perspective (Diff-CL). Firstly, we propose a cross-pseudo-supervision learning mechanism between diffusion and convolution segmentation networks. Secondly, we design a high-frequency mamba module to capture boundary and detail information globally. Finally, we apply contrastive learning for label propagation from labeled to unlabeled data. Our method achieves state-of-the-art (SOTA) performance across three datasets, including left atrium, brain tumor, and NIH pancreas datasets.
Solving Prior Distribution Mismatch in Diffusion Models via Optimal Transport
Oct 17, 2024


In recent years, the knowledge surrounding diffusion models(DMs) has grown significantly, though several theoretical gaps remain. Particularly noteworthy is prior error, defined as the discrepancy between the termination distribution of the forward process and the initial distribution of the reverse process. To address these deficiencies, this paper explores the deeper relationship between optimal transport(OT) theory and DMs with discrete initial distribution. Specifically, we demonstrate that the two stages of DMs fundamentally involve computing time-dependent OT. However, unavoidable prior error result in deviation during the reverse process under quadratic transport cost. By proving that as the diffusion termination time increases, the probability flow exponentially converges to the gradient of the solution to the classical Monge-Amp\`ere equation, we establish a vital link between these fields. Therefore, static OT emerges as the most intrinsic single-step method for bridging this theoretical potential gap. Additionally, we apply these insights to accelerate sampling in both unconditional and conditional generation scenarios. Experimental results across multiple image datasets validate the effectiveness of our approach.
HOTS3D: Hyper-Spherical Optimal Transport for Semantic Alignment of Text-to-3D Generation
Jul 19, 2024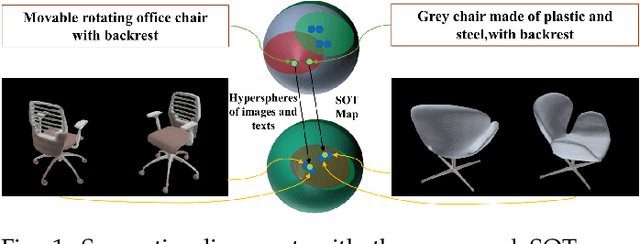
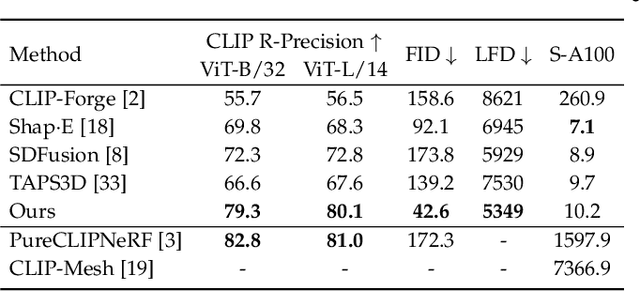
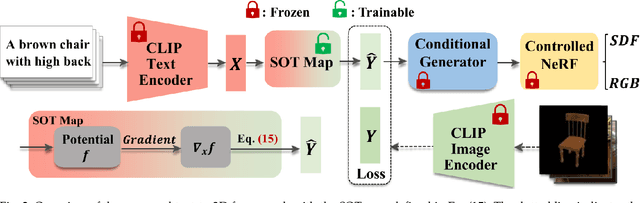
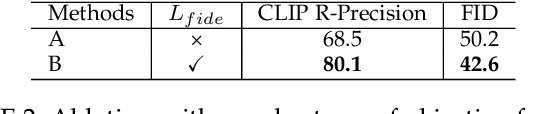
Recent CLIP-guided 3D generation methods have achieved promising results but struggle with generating faithful 3D shapes that conform with input text due to the gap between text and image embeddings. To this end, this paper proposes HOTS3D which makes the first attempt to effectively bridge this gap by aligning text features to the image features with spherical optimal transport (SOT). However, in high-dimensional situations, solving the SOT remains a challenge. To obtain the SOT map for high-dimensional features obtained from CLIP encoding of two modalities, we mathematically formulate and derive the solution based on Villani's theorem, which can directly align two hyper-sphere distributions without manifold exponential maps. Furthermore, we implement it by leveraging input convex neural networks (ICNNs) for the optimal Kantorovich potential. With the optimally mapped features, a diffusion-based generator and a Nerf-based decoder are subsequently utilized to transform them into 3D shapes. Extensive qualitative and qualitative comparisons with state-of-the-arts demonstrate the superiority of the proposed HOTS3D for 3D shape generation, especially on the consistency with text semantics.