 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRT-Splatting: Joint Reflection-Transmission Modeling with Gaussian Splatting
May 18, 20263D Gaussian Splatting (3DGS) enables real-time novel view synthesis with high visual quality. However, existing methods struggle with semi-transparent specular surfaces that exhibit both complex reflections and clear transmission, often producing blurry reflections or overly occluded transmission. To address this, we present RT-Splatting, a framework that disentangles each Gaussian's geometric occupancy from its optical opacity. This factorization yields a unified surface-volume scene representation with a single set of Gaussian primitives. Our hybrid renderer interprets this representation both as a surface to capture high-frequency reflections and as a volume to preserve clear transmission. To mitigate the ambiguity in jointly optimizing reflection and transmission, we introduce Specular-Aware Gradient Gating, which suppresses misleading gradients from highly specular regions into the transmission branch, effectively reducing distracting floaters. Experiments on challenging semi-transparent scenes show that RT-Splatting achieves state-of-the-art performance, delivering high-fidelity reflections and clear transmission with real-time rendering. Moreover, our factorization naturally enables flexible scene editing. The project page is available at https://sjj118.github.io/RT-Splatting.
Smoothly Differentiable and Efficiently Vectorizable Contact Manifold Generation
Feb 23, 2026Simulating rigid-body dynamics with contact in a fast, massively vectorizable, and smoothly differentiable manner is highly desirable in robotics. An important bottleneck faced by existing differentiable simulation frameworks is contact manifold generation: representing the volume of intersection between two colliding geometries via a discrete set of properly distributed contact points. A major factor contributing to this bottleneck is that the related routines of commonly used robotics simulators were not designed with vectorization and differentiability as a primary concern, and thus rely on logic and control flow that hinder these goals. We instead propose a framework designed from the ground up with these goals in mind, by trying to strike a middle ground between: i) convex primitive based approaches used by common robotics simulators (efficient but not differentiable), and ii) mollified vertex-face and edge-edge unsigned distance-based approaches used by barrier methods (differentiable but inefficient). Concretely, we propose: i) a representative set of smooth analytical signed distance primitives to implement vertex-face collisions, and ii) a novel differentiable edge-edge collision routine that can provide signed distances and signed contact normals. The proposed framework is evaluated via a set of didactic experiments and benchmarked against the collision detection routine of the well-established Mujoco XLA framework, where we observe a significant speedup. Supplementary videos can be found at https://github.com/bekeronur/contax, where a reference implementation in JAX will also be made available at the conclusion of the review process.
CVeDRL: An Efficient Code Verifier via Difficulty-aware Reinforcement Learning
Jan 30, 2026Code verifiers play a critical role in post-verification for LLM-based code generation, yet existing supervised fine-tuning methods suffer from data scarcity, high failure rates, and poor inference efficiency. While reinforcement learning (RL) offers a promising alternative by optimizing models through execution-driven rewards without labeled supervision, our preliminary results show that naive RL with only functionality rewards fails to generate effective unit tests for difficult branches and samples. We first theoretically analyze showing that branch coverage, sample difficulty, syntactic and functional correctness can be jointly modeled as RL rewards, where optimizing these signals can improve the reliability of unit-test-based verification. Guided by this analysis, we design syntax- and functionality-aware rewards and further propose branch- and sample-difficulty--aware RL using exponential reward shaping and static analysis metrics. With this formulation, CVeDRL achieves state-of-the-art performance with only 0.6B parameters, yielding up to 28.97% higher pass rate and 15.08% higher branch coverage than GPT-3.5, while delivering over $20\times$ faster inference than competitive baselines. Code is available at https://github.com/LIGHTCHASER1/CVeDRL.git
vLinear: A Powerful Linear Model for Multivariate Time Series Forecasting
Jan 20, 2026In this paper, we present \textbf{vLinear}, an effective yet efficient \textbf{linear}-based multivariate time series forecaster featuring two components: the \textbf{v}ecTrans module and the WFMLoss objective. Many state-of-the-art forecasters rely on self-attention or its variants to capture multivariate correlations, typically incurring $\mathcal{O}(N^2)$ computational complexity with respect to the number of variates $N$. To address this, we propose vecTrans, a lightweight module that utilizes a learnable vector to model multivariate correlations, reducing the complexity to $\mathcal{O}(N)$. Notably, vecTrans can be seamlessly integrated into Transformer-based forecasters, delivering up to 5$\times$ inference speedups and consistent performance gains. Furthermore, we introduce WFMLoss (Weighted Flow Matching Loss) as the objective. In contrast to typical \textbf{velocity-oriented} flow matching objectives, we demonstrate that a \textbf{final-series-oriented} formulation yields significantly superior forecasting accuracy. WFMLoss also incorporates path- and horizon-weighted strategies to focus learning on more reliable paths and horizons. Empirically, vLinear achieves state-of-the-art performance across 22 benchmarks and 124 forecasting settings. Moreover, WFMLoss serves as an effective plug-and-play objective, consistently improving existing forecasters. The code is available at https://anonymous.4open.science/r/vLinear.
Staged Voxel-Level Deep Reinforcement Learning for 3D Medical Image Segmentation with Noisy Annotations
Jan 07, 2026Deep learning has achieved significant advancements in medical image segmentation. Currently, obtaining accurate segmentation outcomes is critically reliant on large-scale datasets with high-quality annotations. However, noisy annotations are frequently encountered owing to the complex morphological structures of organs in medical images and variations among different annotators, which can substantially limit the efficacy of segmentation models. Motivated by the fact that medical imaging annotator can correct labeling errors during segmentation based on prior knowledge, we propose an end-to-end Staged Voxel-Level Deep Reinforcement Learning (SVL-DRL) framework for robust medical image segmentation under noisy annotations. This framework employs a dynamic iterative update strategy to automatically mitigate the impact of erroneous labels without requiring manual intervention. The key advancements of SVL-DRL over existing works include: i) formulating noisy annotations as a voxel-dependent problem and addressing it through a novel staged reinforcement learning framework which guarantees robust model convergence; ii) incorporating a voxel-level asynchronous advantage actor-critic (vA3C) module that conceptualizes each voxel as an autonomous agent, which allows each agent to dynamically refine its own state representation during training, thereby directly mitigating the influence of erroneous labels; iii) designing a novel action space for the agents, along with a composite reward function that strategically combines the Dice value and a spatial continuity metric to significantly boost segmentation accuracy while maintain semantic integrity. Experiments on three public medical image datasets demonstrates State-of-The-Art (SoTA) performance under various experimental settings, with an average improvement of over 3\% in both Dice and IoU scores.
REACT-LLM: A Benchmark for Evaluating LLM Integration with Causal Features in Clinical Prognostic Tasks
Nov 13, 2025Large Language Models (LLMs) and causal learning each hold strong potential for clinical decision making (CDM). However, their synergy remains poorly understood, largely due to the lack of systematic benchmarks evaluating their integration in clinical risk prediction. In real-world healthcare, identifying features with causal influence on outcomes is crucial for actionable and trustworthy predictions. While recent work highlights LLMs' emerging causal reasoning abilities, there lacks comprehensive benchmarks to assess their causal learning and performance informed by causal features in clinical risk prediction. To address this, we introduce REACT-LLM, a benchmark designed to evaluate whether combining LLMs with causal features can enhance clinical prognostic performance and potentially outperform traditional machine learning (ML) methods. Unlike existing LLM-clinical benchmarks that often focus on a limited set of outcomes, REACT-LLM evaluates 7 clinical outcomes across 2 real-world datasets, comparing 15 prominent LLMs, 6 traditional ML models, and 3 causal discovery (CD) algorithms. Our findings indicate that while LLMs perform reasonably in clinical prognostics, they have not yet outperformed traditional ML models. Integrating causal features derived from CD algorithms into LLMs offers limited performance gains, primarily due to the strict assumptions of many CD methods, which are often violated in complex clinical data. While the direct integration yields limited improvement, our benchmark reveals a more promising synergy.
Fast $k$-means clustering in Riemannian manifolds via Fréchet maps: Applications to large-dimensional SPD matrices
Nov 12, 2025We introduce a novel, efficient framework for clustering data on high-dimensional, non-Euclidean manifolds that overcomes the computational challenges associated with standard intrinsic methods. The key innovation is the use of the $p$-Fréchet map $F^p : \mathcal{M} \to \mathbb{R}^\ell$ -- defined on a generic metric space $\mathcal{M}$ -- which embeds the manifold data into a lower-dimensional Euclidean space $\mathbb{R}^\ell$ using a set of reference points $\{r_i\}_{i=1}^\ell$, $r_i \in \mathcal{M}$. Once embedded, we can efficiently and accurately apply standard Euclidean clustering techniques such as k-means. We rigorously analyze the mathematical properties of $F^p$ in the Euclidean space and the challenging manifold of $n \times n$ symmetric positive definite matrices $\mathit{SPD}(n)$. Extensive numerical experiments using synthetic and real $\mathit{SPD}(n)$ data demonstrate significant performance gains: our method reduces runtime by up to two orders of magnitude compared to intrinsic manifold-based approaches, all while maintaining high clustering accuracy, including scenarios where existing alternative methods struggle or fail.
OLinear: A Linear Model for Time Series Forecasting in Orthogonally Transformed Domain
May 14, 2025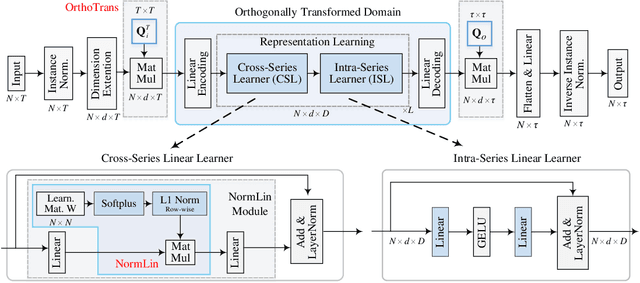
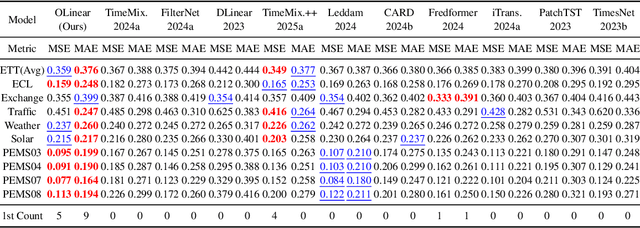
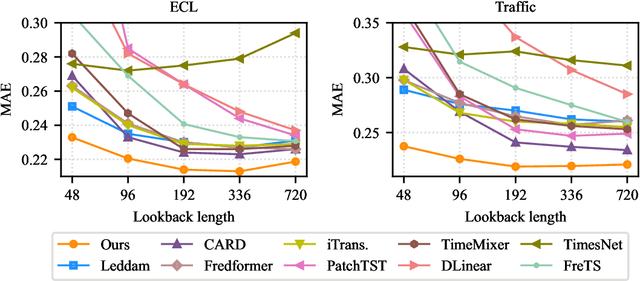
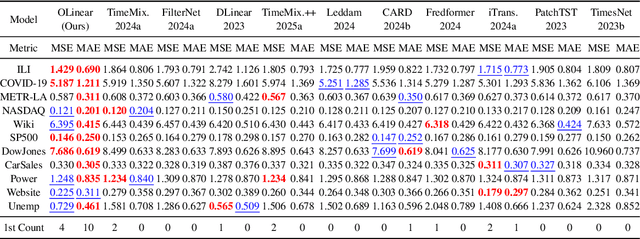
This paper presents $\mathbf{OLinear}$, a $\mathbf{linear}$-based multivariate time series forecasting model that operates in an $\mathbf{o}$rthogonally transformed domain. Recent forecasting models typically adopt the temporal forecast (TF) paradigm, which directly encode and decode time series in the time domain. However, the entangled step-wise dependencies in series data can hinder the performance of TF. To address this, some forecasters conduct encoding and decoding in the transformed domain using fixed, dataset-independent bases (e.g., sine and cosine signals in the Fourier transform). In contrast, we utilize $\mathbf{OrthoTrans}$, a data-adaptive transformation based on an orthogonal matrix that diagonalizes the series' temporal Pearson correlation matrix. This approach enables more effective encoding and decoding in the decorrelated feature domain and can serve as a plug-in module to enhance existing forecasters. To enhance the representation learning for multivariate time series, we introduce a customized linear layer, $\mathbf{NormLin}$, which employs a normalized weight matrix to capture multivariate dependencies. Empirically, the NormLin module shows a surprising performance advantage over multi-head self-attention, while requiring nearly half the FLOPs. Extensive experiments on 24 benchmarks and 140 forecasting tasks demonstrate that OLinear consistently achieves state-of-the-art performance with high efficiency. Notably, as a plug-in replacement for self-attention, the NormLin module consistently enhances Transformer-based forecasters. The code and datasets are available at https://anonymous.4open.science/r/OLinear
SFi-Former: Sparse Flow Induced Attention for Graph Transformer
Apr 29, 2025Graph Transformers (GTs) have demonstrated superior performance compared to traditional message-passing graph neural networks in many studies, especially in processing graph data with long-range dependencies. However, GTs tend to suffer from weak inductive bias, overfitting and over-globalizing problems due to the dense attention. In this paper, we introduce SFi-attention, a novel attention mechanism designed to learn sparse pattern by minimizing an energy function based on network flows with l1-norm regularization, to relieve those issues caused by dense attention. Furthermore, SFi-Former is accordingly devised which can leverage the sparse attention pattern of SFi-attention to generate sparse network flows beyond adjacency matrix of graph data. Specifically, SFi-Former aggregates features selectively from other nodes through flexible adaptation of the sparse attention, leading to a more robust model. We validate our SFi-Former on various graph datasets, especially those graph data exhibiting long-range dependencies. Experimental results show that our SFi-Former obtains competitive performance on GNN Benchmark datasets and SOTA performance on LongRange Graph Benchmark (LRGB) datasets. Additionally, our model gives rise to smaller generalization gaps, which indicates that it is less prone to over-fitting. Click here for codes.
JTreeformer: Graph-Transformer via Latent-Diffusion Model for Molecular Generation
Apr 29, 2025The discovery of new molecules based on the original chemical molecule distributions is of great importance in medicine. The graph transformer, with its advantages of high performance and scalability compared to traditional graph networks, has been widely explored in recent research for applications of graph structures. However, current transformer-based graph decoders struggle to effectively utilize graph information, which limits their capacity to leverage only sequences of nodes rather than the complex topological structures of molecule graphs. This paper focuses on building a graph transformer-based framework for molecular generation, which we call \textbf{JTreeformer} as it transforms graph generation into junction tree generation. It combines GCN parallel with multi-head attention as the encoder. It integrates a directed acyclic GCN into a graph-based Transformer to serve as a decoder, which can iteratively synthesize the entire molecule by leveraging information from the partially constructed molecular structure at each step. In addition, a diffusion model is inserted in the latent space generated by the encoder, to enhance the efficiency and effectiveness of sampling further. The empirical results demonstrate that our novel framework outperforms existing molecule generation methods, thus offering a promising tool to advance drug discovery (https://anonymous.4open.science/r/JTreeformer-C74C).