 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLAM3R: Real-Time Dense Scene Reconstruction from Monocular RGB Videos
Dec 12, 2024In this paper, we introduce \textbf{SLAM3R}, a novel and effective monocular RGB SLAM system for real-time and high-quality dense 3D reconstruction. SLAM3R provides an end-to-end solution by seamlessly integrating local 3D reconstruction and global coordinate registration through feed-forward neural networks. Given an input video, the system first converts it into overlapping clips using a sliding window mechanism. Unlike traditional pose optimization-based methods, SLAM3R directly regresses 3D pointmaps from RGB images in each window and progressively aligns and deforms these local pointmaps to create a globally consistent scene reconstruction - all without explicitly solving any camera parameters. Experiments across datasets consistently show that SLAM3R achieves state-of-the-art reconstruction accuracy and completeness while maintaining real-time performance at 20+ FPS. Code and weights at: \url{https://github.com/PKU-VCL-3DV/SLAM3R}.
Reloc3r: Large-Scale Training of Relative Camera Pose Regression for Generalizable, Fast, and Accurate Visual Localization
Dec 11, 2024



Visual localization aims to determine the camera pose of a query image relative to a database of posed images. In recent years, deep neural networks that directly regress camera poses have gained popularity due to their fast inference capabilities. However, existing methods struggle to either generalize well to new scenes or provide accurate camera pose estimates. To address these issues, we present \textbf{Reloc3r}, a simple yet effective visual localization framework. It consists of an elegantly designed relative pose regression network, and a minimalist motion averaging module for absolute pose estimation. Trained on approximately 8 million posed image pairs, Reloc3r achieves surprisingly good performance and generalization ability. We conduct extensive experiments on 6 public datasets, consistently demonstrating the effectiveness and efficiency of the proposed method. It provides high-quality camera pose estimates in real time and generalizes to novel scenes. Code, weights, and data at: \url{https://github.com/ffrivera0/reloc3r}.
InfoNorm: Mutual Information Shaping of Normals for Sparse-View Reconstruction
Jul 17, 2024



3D surface reconstruction from multi-view images is essential for scene understanding and interaction. However, complex indoor scenes pose challenges such as ambiguity due to limited observations. Recent implicit surface representations, such as Neural Radiance Fields (NeRFs) and signed distance functions (SDFs), employ various geometric priors to resolve the lack of observed information. Nevertheless, their performance heavily depends on the quality of the pre-trained geometry estimation models. To ease such dependence, we propose regularizing the geometric modeling by explicitly encouraging the mutual information among surface normals of highly correlated scene points. In this way, the geometry learning process is modulated by the second-order correlations from noisy (first-order) geometric priors, thus eliminating the bias due to poor generalization. Additionally, we introduce a simple yet effective scheme that utilizes semantic and geometric features to identify correlated points, enhancing their mutual information accordingly. The proposed technique can serve as a plugin for SDF-based neural surface representations. Our experiments demonstrate the effectiveness of the proposed in improving the surface reconstruction quality of major states of the arts. Our code is available at: \url{https://github.com/Muliphein/InfoNorm}.
SG-NeRF: Neural Surface Reconstruction with Scene Graph Optimization
Jul 17, 2024
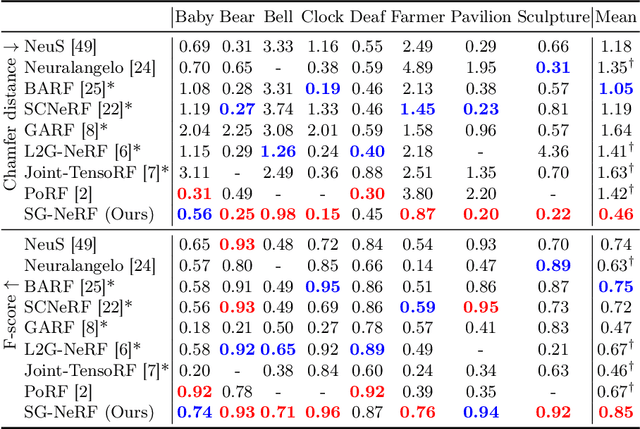


3D surface reconstruction from images is essential for numerous applications. Recently, Neural Radiance Fields (NeRFs) have emerged as a promising framework for 3D modeling. However, NeRFs require accurate camera poses as input, and existing methods struggle to handle significantly noisy pose estimates (i.e., outliers), which are commonly encountered in real-world scenarios. To tackle this challenge, we present a novel approach that optimizes radiance fields with scene graphs to mitigate the influence of outlier poses. Our method incorporates an adaptive inlier-outlier confidence estimation scheme based on scene graphs, emphasizing images of high compatibility with the neighborhood and consistency in the rendering quality. We also introduce an effective intersection-over-union (IoU) loss to optimize the camera pose and surface geometry, together with a coarse-to-fine strategy to facilitate the training. Furthermore, we propose a new dataset containing typical outlier poses for a detailed evaluation. Experimental results on various datasets consistently demonstrate the effectiveness and superiority of our method over existing approaches, showcasing its robustness in handling outliers and producing high-quality 3D reconstructions. Our code and data are available at: \url{https://github.com/Iris-cyy/SG-NeRF}.
Lazy Visual Localization via Motion Averaging
Jul 19, 2023



Visual (re)localization is critical for various applications in computer vision and robotics. Its goal is to estimate the 6 degrees of freedom (DoF) camera pose for each query image, based on a set of posed database images. Currently, all leading solutions are structure-based that either explicitly construct 3D metric maps from the database with structure-from-motion, or implicitly encode the 3D information with scene coordinate regression models. On the contrary, visual localization without reconstructing the scene in 3D offers clear benefits. It makes deployment more convenient by reducing database pre-processing time, releasing storage requirements, and remaining unaffected by imperfect reconstruction, etc. In this technical report, we demonstrate that it is possible to achieve high localization accuracy without reconstructing the scene from the database. The key to achieving this owes to a tailored motion averaging over database-query pairs. Experiments show that our visual localization proposal, LazyLoc, achieves comparable performance against state-of-the-art structure-based methods. Furthermore, we showcase the versatility of LazyLoc, which can be easily extended to handle complex configurations such as multi-query co-localization and camera rigs.
Visual Localization via Few-Shot Scene Region Classification
Aug 14, 2022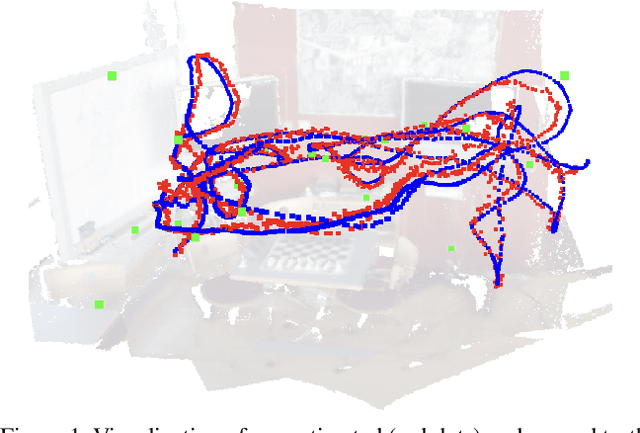
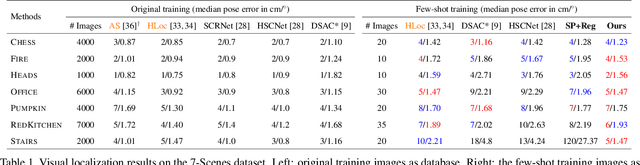

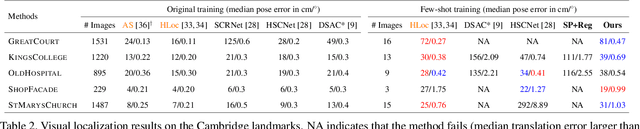
Visual (re)localization addresses the problem of estimating the 6-DoF (Degree of Freedom) camera pose of a query image captured in a known scene, which is a key building block of many computer vision and robotics applications. Recent advances in structure-based localization solve this problem by memorizing the mapping from image pixels to scene coordinates with neural networks to build 2D-3D correspondences for camera pose optimization. However, such memorization requires training by amounts of posed images in each scene, which is heavy and inefficient. On the contrary, few-shot images are usually sufficient to cover the main regions of a scene for a human operator to perform visual localization. In this paper, we propose a scene region classification approach to achieve fast and effective scene memorization with few-shot images. Our insight is leveraging a) pre-learned feature extractor, b) scene region classifier, and c) meta-learning strategy to accelerate training while mitigating overfitting. We evaluate our method on both indoor and outdoor benchmarks. The experiments validate the effectiveness of our method in the few-shot setting, and the training time is significantly reduced to only a few minutes. Code available at: \url{https://github.com/siyandong/SRC}
Multi-Robot Active Mapping via Neural Bipartite Graph Matching
Apr 01, 2022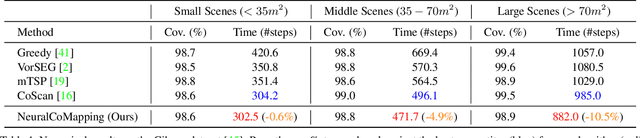
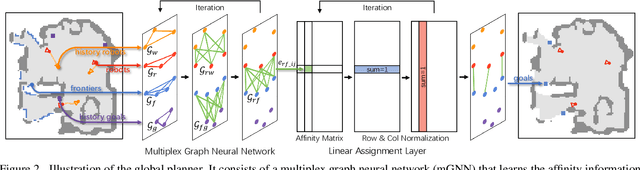
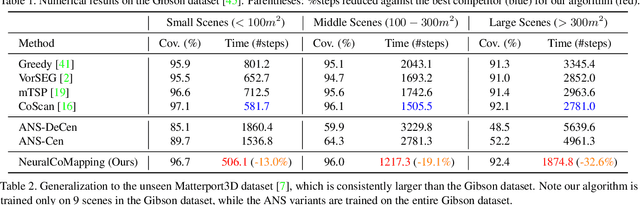
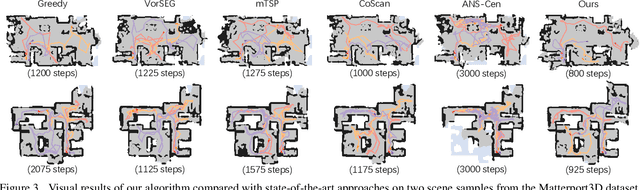
We study the problem of multi-robot active mapping, which aims for complete scene map construction in minimum time steps. The key to this problem lies in the goal position estimation to enable more efficient robot movements. Previous approaches either choose the frontier as the goal position via a myopic solution that hinders the time efficiency, or maximize the long-term value via reinforcement learning to directly regress the goal position, but does not guarantee the complete map construction. In this paper, we propose a novel algorithm, namely NeuralCoMapping, which takes advantage of both approaches. We reduce the problem to bipartite graph matching, which establishes the node correspondences between two graphs, denoting robots and frontiers. We introduce a multiplex graph neural network (mGNN) that learns the neural distance to fill the affinity matrix for more effective graph matching. We optimize the mGNN with a differentiable linear assignment layer by maximizing the long-term values that favor time efficiency and map completeness via reinforcement learning. We compare our algorithm with several state-of-the-art multi-robot active mapping approaches and adapted reinforcement-learning baselines. Experimental results demonstrate the superior performance and exceptional generalization ability of our algorithm on various indoor scenes and unseen number of robots, when only trained with 9 indoor scenes.
Robust Neural Routing Through Space Partitions for Camera Relocalization in Dynamic Indoor Environments
Dec 08, 2020
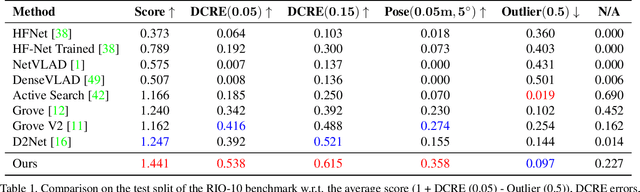
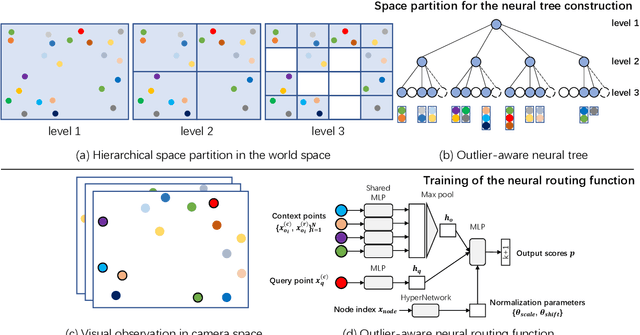

Localizing the camera in a known indoor environment is a key building block for scene mapping, robot navigation, AR, etc. Recent advances estimate the camera pose via optimization over the 2D/3D-3D correspondences established between the coordinates in 2D/3D camera space and 3D world space. Such a mapping is estimated with either a convolution neural network or a decision tree using only the static input image sequence, which makes these approaches vulnerable to dynamic indoor environments that are quite common yet challenging in the real world. To address the aforementioned issues, in this paper, we propose a novel outlier-aware neural tree which bridges the two worlds, deep learning and decision tree approaches. It builds on three important blocks; (a) a hierarchical space partition over the indoor scene to construct the decision tree; (b) a neural routing function, implemented as a deep classification network, employed for better 3D scene understanding; and (c) an outlier rejection module used to filter out dynamic points during the hierarchical routing process. Our proposed algorithm is evaluated on the RIO-10 benchmark developed for camera relocalization in dynamic indoor environment. It achieves robust neural routing through space partitions and outperforms the state-of-the-art approaches by around 30\% on camera pose accuracy, while running comparably fast for evaluation.
Active Visual Localization in Partially Calibrated Environments
Dec 08, 2020
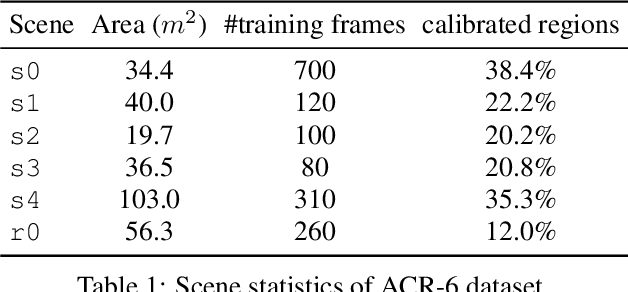
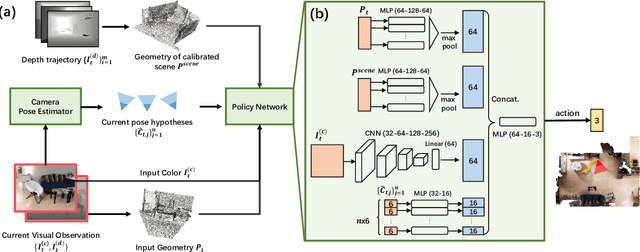

Humans can robustly localize themselves without a map after they get lost following prominent visual cues or landmarks. In this work, we aim at endowing autonomous agents the same ability. Such ability is important in robotics applications yet very challenging when an agent is exposed to partially calibrated environments, where camera images with accurate 6 Degree-of-Freedom pose labels only cover part of the scene. To address the above challenge, we explore using Reinforcement Learning to search for a policy to generate intelligent motions so as to actively localize the agent given visual information in partially calibrated environments. Our core contribution is to formulate the active visual localization problem as a Partially Observable Markov Decision Process and propose an algorithmic framework based on Deep Reinforcement Learning to solve it. We further propose an indoor scene dataset ACR-6, which consists of both synthetic and real data and simulates challenging scenarios for active visual localization. We benchmark our algorithm against handcrafted baselines for localization and demonstrate that our approach significantly outperforms them on localization success rate.
Decoupling Features and Coordinates for Few-shot RGB Relocalization
Nov 26, 2019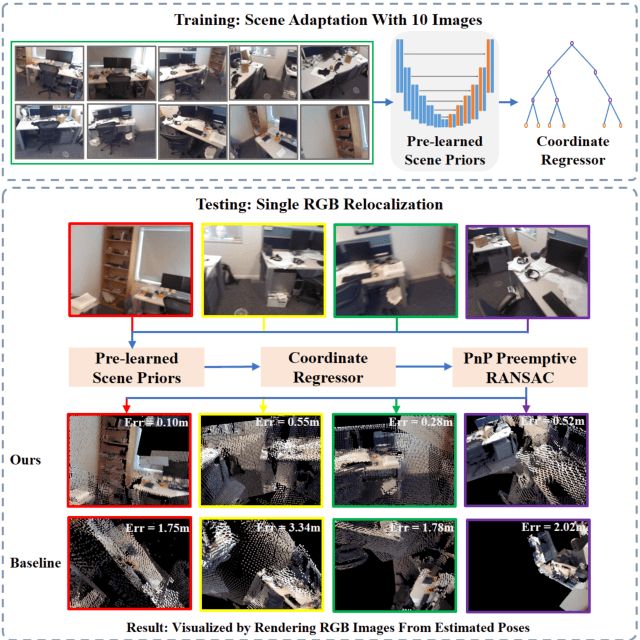
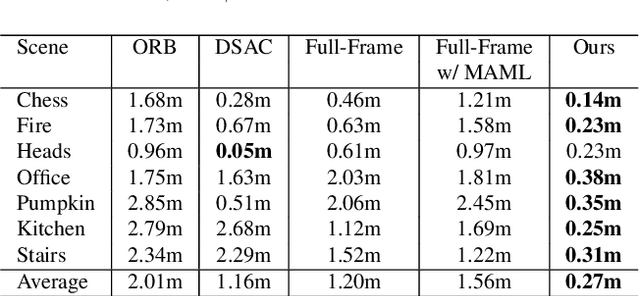
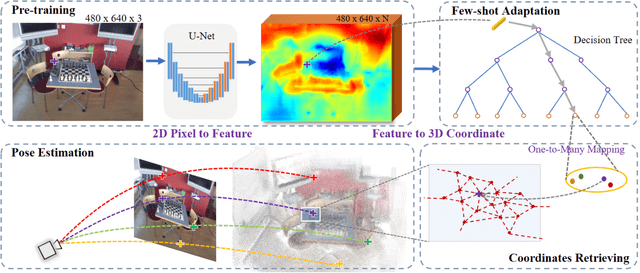
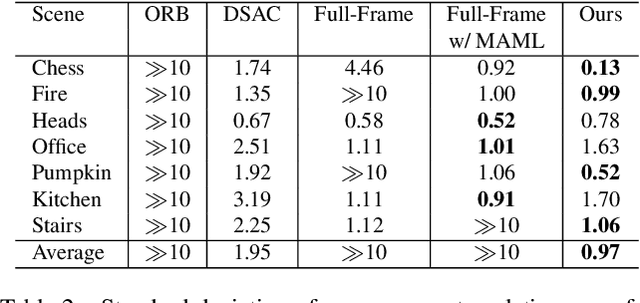
Cross-scene model adaption is a crucial feature for camera relocalization applied in real scenarios. It is preferable that a pre-learned model can be quickly deployed in a novel scene with as little training as possible. The existing state-of-the-art approaches, however, can hardly support few-shot scene adaption due to the entangling of image feature extraction and 3D coordinate regression, which requires a large-scale of training data. To address this issue, inspired by how humans relocalize, we approach camera relocalization with a decoupled solution where feature extraction, coordinate regression and pose estimation are performed separately. Our key insight is that robust and discriminative image features used for coordinate regression should be learned by removing the distracting factor of camera views, because coordinates in the world reference frame are obviously independent of local views. In particular, we employ a deep neural network to learn view-factorized pixel-wise features using several training scenes. Given a new scene, we train a view-dependent per-pixel 3D coordinate regressor while keeping the feature extractor fixed. Such a decoupled design allows us to adapt the entire model to novel scene and achieve accurate camera pose estimation with only few-shot training samples and two orders of magnitude less training time than the state-of-the-arts.