 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding NTK Variance in Implicit Neural Representations
Dec 17, 2025Implicit Neural Representations (INRs) often converge slowly and struggle to recover high-frequency details due to spectral bias. While prior work links this behavior to the Neural Tangent Kernel (NTK), how specific architectural choices affect NTK conditioning remains unclear. We show that many INR mechanisms can be understood through their impact on a small set of pairwise similarity factors and scaling terms that jointly determine NTK eigenvalue variance. For standard coordinate MLPs, limited input-feature interactions induce large eigenvalue dispersion and poor conditioning. We derive closed-form variance decompositions for common INR components and show that positional encoding reshapes input similarity, spherical normalization reduces variance via layerwise scaling, and Hadamard modulation introduces additional similarity factors strictly below one, yielding multiplicative variance reduction. This unified view explains how diverse INR architectures mitigate spectral bias by improving NTK conditioning. Experiments across multiple tasks confirm the predicted variance reductions and demonstrate faster, more stable convergence with improved reconstruction quality.
Visual Localization via Few-Shot Scene Region Classification
Aug 14, 2022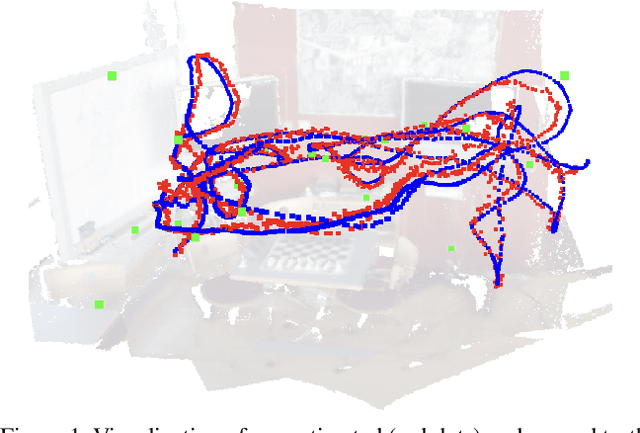
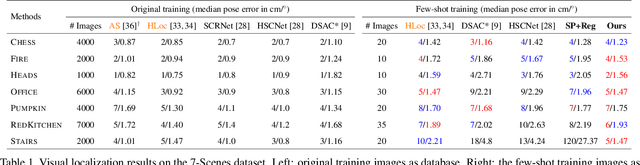

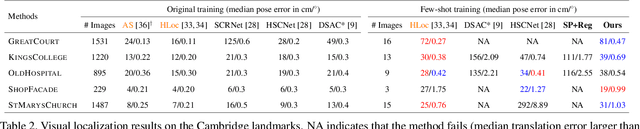
Visual (re)localization addresses the problem of estimating the 6-DoF (Degree of Freedom) camera pose of a query image captured in a known scene, which is a key building block of many computer vision and robotics applications. Recent advances in structure-based localization solve this problem by memorizing the mapping from image pixels to scene coordinates with neural networks to build 2D-3D correspondences for camera pose optimization. However, such memorization requires training by amounts of posed images in each scene, which is heavy and inefficient. On the contrary, few-shot images are usually sufficient to cover the main regions of a scene for a human operator to perform visual localization. In this paper, we propose a scene region classification approach to achieve fast and effective scene memorization with few-shot images. Our insight is leveraging a) pre-learned feature extractor, b) scene region classifier, and c) meta-learning strategy to accelerate training while mitigating overfitting. We evaluate our method on both indoor and outdoor benchmarks. The experiments validate the effectiveness of our method in the few-shot setting, and the training time is significantly reduced to only a few minutes. Code available at: \url{https://github.com/siyandong/SRC}
Filtering In Neural Implicit Functions
Feb 06, 2022



Neural implicit functions are highly effective for representing many kinds of data, including images and 3D shapes. However, the implicit functions learned by neural networks usually include over-smoothed patches or noisy artifacts into the results if the data has many scales of details or a wide range of frequencies. Adapting the result containing both noise and over-smoothed regions usually suffers from either over smoothing or noisy issues. To overcome this challenge, we propose a new framework, coined FINN, that integrates a filtering module into the neural network to perform data generation while filtering artifacts. The filtering module has a smoothing operator that acts on the intermediate results of the network and a recovering operator that brings distinct details from the input back to the regions overly smoothed. The proposed method significantly alleviates over smoothing or noisy issues. We demonstrate the advantage of the FINN on the image regression task, considering both real-world and synthetic images, and showcases significant improvement on both quantitative and qualitative results compared to state-of-the-art methods. Moreover, FINN yields better performance in both convergence speed and network stability. Source code is available at https://github.com/yixin26/FINN.
Neural Implicit 3D Shapes from Single Images with Spatial Patterns
Jun 06, 2021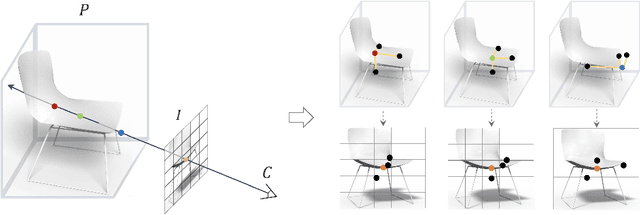
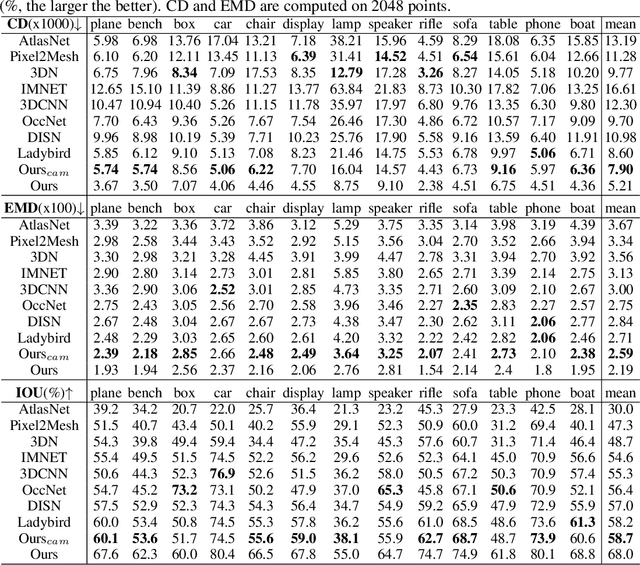
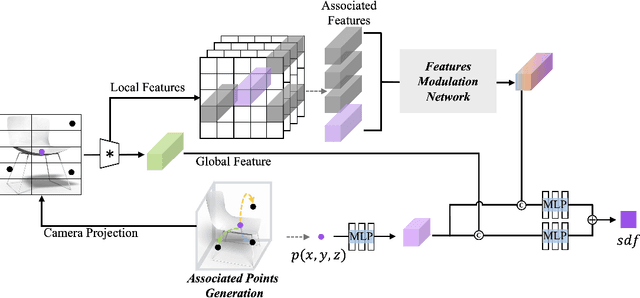
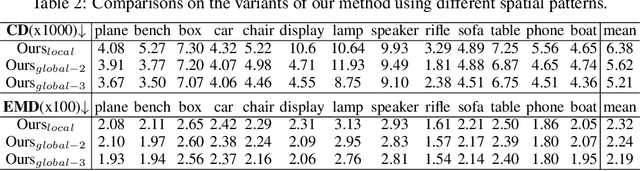
3D shape reconstruction from a single image has been a long-standing problem in computer vision. The problem is ill-posed and highly challenging due to the information loss and occlusion that occurred during the imagery capture. In contrast to previous methods that learn holistic shape priors, we propose a method to learn spatial pattern priors for inferring the invisible regions of the underlying shape, wherein each 3D sample in the implicit shape representation is associated with a set of points generated by hand-crafted 3D mappings, along with their local image features. The proposed spatial pattern is significantly more informative and has distinctive descriptions on both visible and occluded locations. Most importantly, the key to our work is the ubiquitousness of the spatial patterns across shapes, which enables reasoning invisible parts of the underlying objects and thus greatly mitigates the occlusion issue. We devise a neural network that integrates spatial pattern representations and demonstrate the superiority of the proposed method on widely used metrics.
Multimodal Shape Completion via Conditional Generative Adversarial Networks
Mar 18, 2020



Several deep learning methods have been proposed for completing partial data from shape acquisition setups, i.e., filling the regions that were missing in the shape. These methods, however, only complete the partial shape with a single output, ignoring the ambiguity when reasoning the missing geometry. Hence, we pose a multi-modal shape completion problem, in which we seek to complete the partial shape with multiple outputs by learning a one-to-many mapping. We develop the first multimodal shape completion method that completes the partial shape via conditional generative modeling, without requiring paired training data. Our approach distills the ambiguity by conditioning the completion on a learned multimodal distribution of possible results. We extensively evaluate the approach on several datasets that contain varying forms of shape incompleteness, and compare among several baseline methods and variants of our methods qualitatively and quantitatively, demonstrating the merit of our method in completing partial shapes with both diversity and quality.
Decoupling Features and Coordinates for Few-shot RGB Relocalization
Nov 26, 2019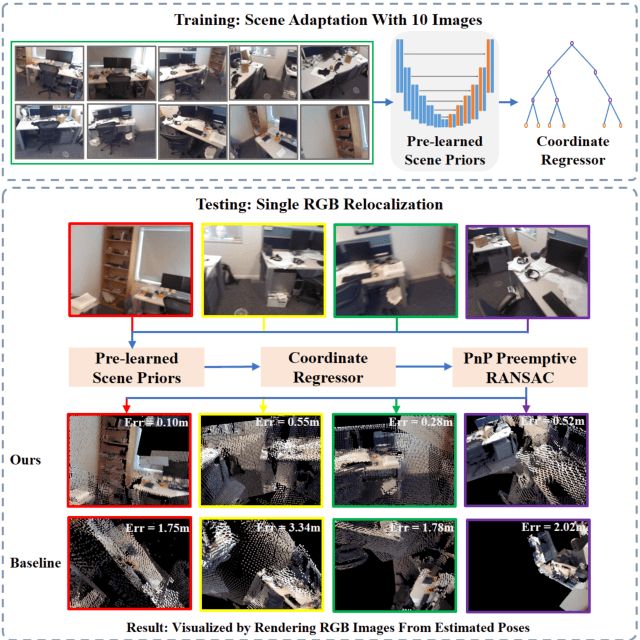
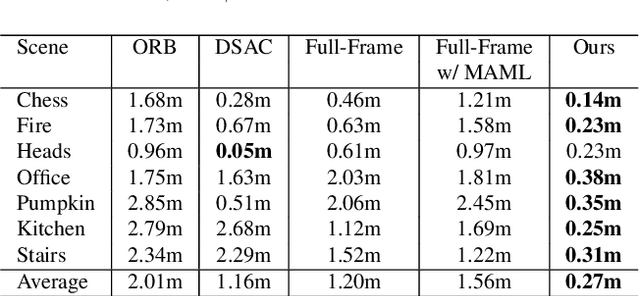
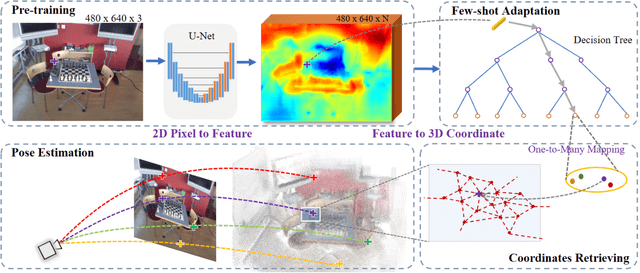
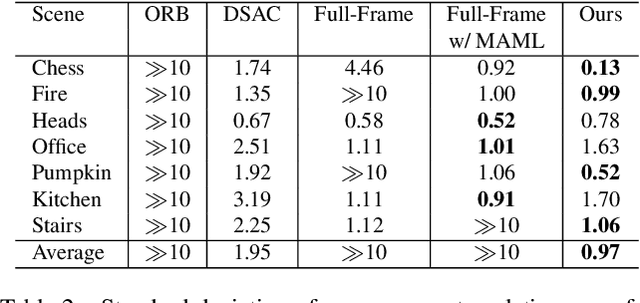
Cross-scene model adaption is a crucial feature for camera relocalization applied in real scenarios. It is preferable that a pre-learned model can be quickly deployed in a novel scene with as little training as possible. The existing state-of-the-art approaches, however, can hardly support few-shot scene adaption due to the entangling of image feature extraction and 3D coordinate regression, which requires a large-scale of training data. To address this issue, inspired by how humans relocalize, we approach camera relocalization with a decoupled solution where feature extraction, coordinate regression and pose estimation are performed separately. Our key insight is that robust and discriminative image features used for coordinate regression should be learned by removing the distracting factor of camera views, because coordinates in the world reference frame are obviously independent of local views. In particular, we employ a deep neural network to learn view-factorized pixel-wise features using several training scenes. Given a new scene, we train a view-dependent per-pixel 3D coordinate regressor while keeping the feature extractor fixed. Such a decoupled design allows us to adapt the entire model to novel scene and achieve accurate camera pose estimation with only few-shot training samples and two orders of magnitude less training time than the state-of-the-arts.
PQ-NET: A Generative Part Seq2Seq Network for 3D Shapes
Nov 25, 2019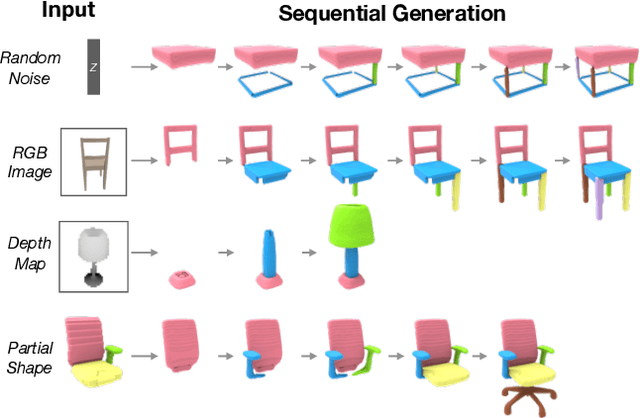



We introduce PQ-NET, a deep neural network which represents and generates 3D shapes via sequential part assembly. The input to our network is a 3D shape segmented into parts, where each part is first encoded into a feature representation using a part autoencoder. The core component of PQ-NET is a sequence-to-sequence or Seq2Seq autoencoder which encodes a sequence of part features into a latent vector of fixed size, and the decoder reconstructs the 3D shape, one part at a time, resulting in a sequential assembly. The latent space formed by the Seq2Seq encoder encodes both part structure and fine part geometry. The decoder can be adapted to perform several generative tasks including shape autoencoding, interpolation, novel shape generation, and single-view 3D reconstruction, where the generated shapes are all composed of meaningful parts.