 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQMBench: A Research Level Benchmark for Quantum Materials Research
Dec 19, 2025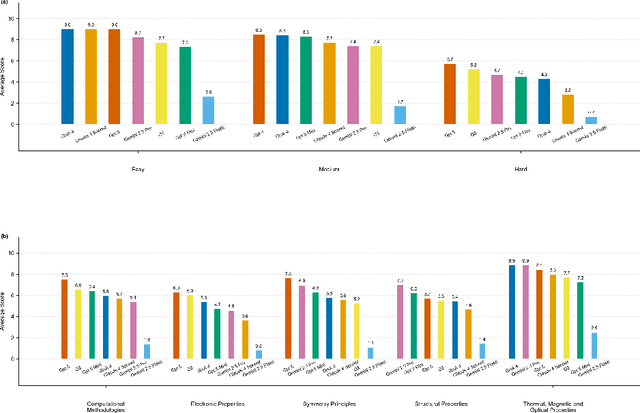

We introduce QMBench, a comprehensive benchmark designed to evaluate the capability of large language model agents in quantum materials research. This specialized benchmark assesses the model's ability to apply condensed matter physics knowledge and computational techniques such as density functional theory to solve research problems in quantum materials science. QMBench encompasses different domains of the quantum material research, including structural properties, electronic properties, thermodynamic and other properties, symmetry principle and computational methodologies. By providing a standardized evaluation framework, QMBench aims to accelerate the development of an AI scientist capable of making creative contributions to quantum materials research. We expect QMBench to be developed and constantly improved by the research community.
Universal Sleep Decoder: Aligning awake and sleep neural representation across subjects
Sep 28, 2023



Decoding memory content from brain activity during sleep has long been a goal in neuroscience. While spontaneous reactivation of memories during sleep in rodents is known to support memory consolidation and offline learning, capturing memory replay in humans is challenging due to the absence of well-annotated sleep datasets and the substantial differences in neural patterns between wakefulness and sleep. To address these challenges, we designed a novel cognitive neuroscience experiment and collected a comprehensive, well-annotated electroencephalography (EEG) dataset from 52 subjects during both wakefulness and sleep. Leveraging this benchmark dataset, we developed the Universal Sleep Decoder (USD) to align neural representations between wakefulness and sleep across subjects. Our model achieves up to 16.6% top-1 zero-shot accuracy on unseen subjects, comparable to decoding performances using individual sleep data. Furthermore, fine-tuning USD on test subjects enhances decoding accuracy to 25.9% top-1 accuracy, a substantial improvement over the baseline chance of 6.7%. Model comparison and ablation analyses reveal that our design choices, including the use of (i) an additional contrastive objective to integrate awake and sleep neural signals and (ii) the pretrain-finetune paradigm to incorporate different subjects, significantly contribute to these performances. Collectively, our findings and methodologies represent a significant advancement in the field of sleep decoding.
Self-Conditioned Generative Adversarial Networks for Image Editing
Feb 08, 2022Generative Adversarial Networks (GANs) are susceptible to bias, learned from either the unbalanced data, or through mode collapse. The networks focus on the core of the data distribution, leaving the tails - or the edges of the distribution - behind. We argue that this bias is responsible not only for fairness concerns, but that it plays a key role in the collapse of latent-traversal editing methods when deviating away from the distribution's core. Building on this observation, we outline a method for mitigating generative bias through a self-conditioning process, where distances in the latent-space of a pre-trained generator are used to provide initial labels for the data. By fine-tuning the generator on a re-sampled distribution drawn from these self-labeled data, we force the generator to better contend with rare semantic attributes and enable more realistic generation of these properties. We compare our models to a wide range of latent editing methods, and show that by alleviating the bias they achieve finer semantic control and better identity preservation through a wider range of transformations. Our code and models will be available at https://github.com/yzliu567/sc-gan
Neural Implicit 3D Shapes from Single Images with Spatial Patterns
Jun 06, 2021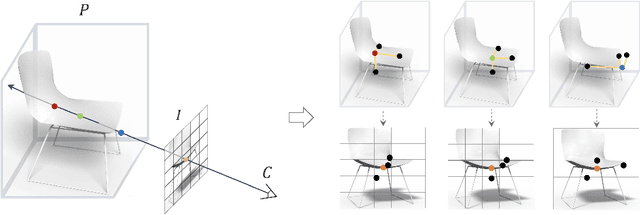
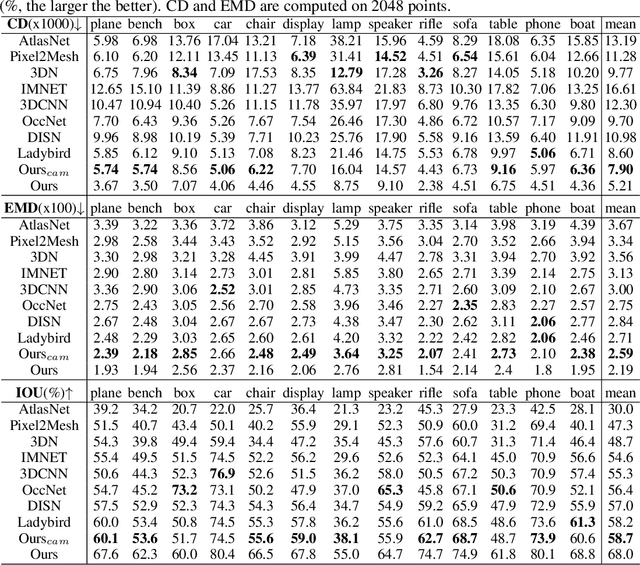
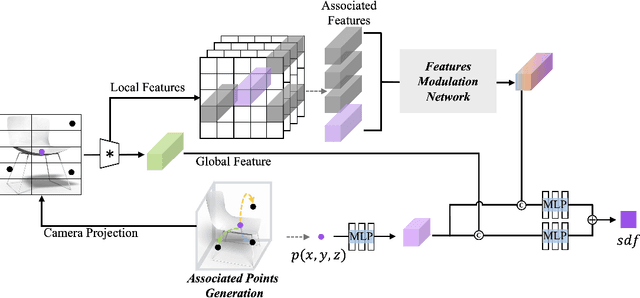
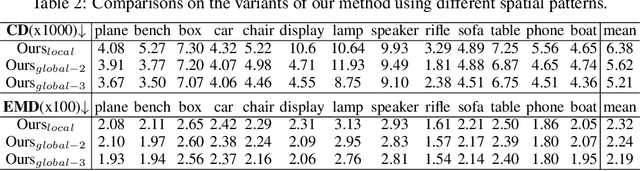
3D shape reconstruction from a single image has been a long-standing problem in computer vision. The problem is ill-posed and highly challenging due to the information loss and occlusion that occurred during the imagery capture. In contrast to previous methods that learn holistic shape priors, we propose a method to learn spatial pattern priors for inferring the invisible regions of the underlying shape, wherein each 3D sample in the implicit shape representation is associated with a set of points generated by hand-crafted 3D mappings, along with their local image features. The proposed spatial pattern is significantly more informative and has distinctive descriptions on both visible and occluded locations. Most importantly, the key to our work is the ubiquitousness of the spatial patterns across shapes, which enables reasoning invisible parts of the underlying objects and thus greatly mitigates the occlusion issue. We devise a neural network that integrates spatial pattern representations and demonstrate the superiority of the proposed method on widely used metrics.