 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCARLoS: Retrieval via Concise Assessment Representation of LoRAs at Scale
Dec 09, 2025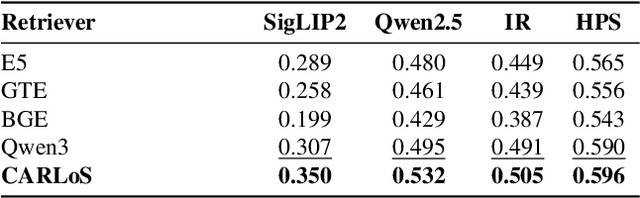
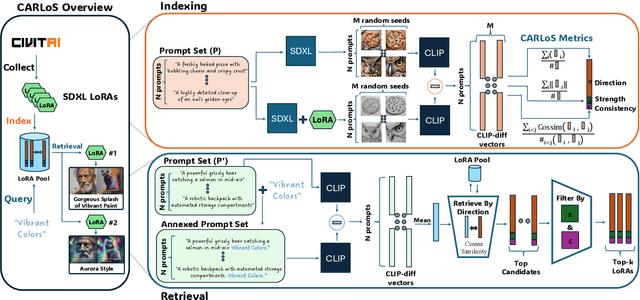
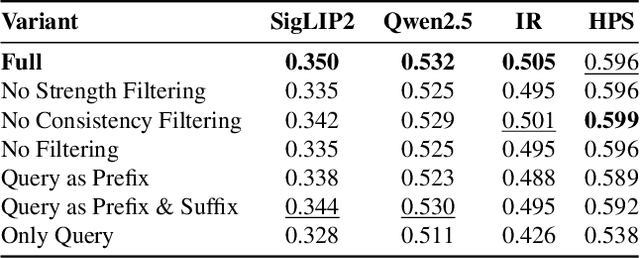

The rapid proliferation of generative components, such as LoRAs, has created a vast but unstructured ecosystem. Existing discovery methods depend on unreliable user descriptions or biased popularity metrics, hindering usability. We present CARLoS, a large-scale framework for characterizing LoRAs without requiring additional metadata. Analyzing over 650 LoRAs, we employ them in image generation over a variety of prompts and seeds, as a credible way to assess their behavior. Using CLIP embeddings and their difference to a base-model generation, we concisely define a three-part representation: Directions, defining semantic shift; Strength, quantifying the significance of the effect; and Consistency, quantifying how stable the effect is. Using these representations, we develop an efficient retrieval framework that semantically matches textual queries to relevant LoRAs while filtering overly strong or unstable ones, outperforming textual baselines in automated and human evaluations. While retrieval is our primary focus, the same representation also supports analyses linking Strength and Consistency to legal notions of substantiality and volition, key considerations in copyright, positioning CARLoS as a practical system with broader relevance for LoRA analysis.
Count The Notes: Histogram-Based Supervision for Automatic Music Transcription
Nov 18, 2025Automatic Music Transcription (AMT) converts audio recordings into symbolic musical representations. Training deep neural networks (DNNs) for AMT typically requires strongly aligned training pairs with precise frame-level annotations. Since creating such datasets is costly and impractical for many musical contexts, weakly aligned approaches using segment-level annotations have gained traction. However, existing methods often rely on Dynamic Time Warping (DTW) or soft alignment loss functions, both of which still require local semantic correspondences, making them error-prone and computationally expensive. In this article, we introduce CountEM, a novel AMT framework that eliminates the need for explicit local alignment by leveraging note event histograms as supervision, enabling lighter computations and greater flexibility. Using an Expectation-Maximization (EM) approach, CountEM iteratively refines predictions based solely on note occurrence counts, significantly reducing annotation efforts while maintaining high transcription accuracy. Experiments on piano, guitar, and multi-instrument datasets demonstrate that CountEM matches or surpasses existing weakly supervised methods, improving AMT's robustness, scalability, and efficiency. Our project page is available at https://yoni-yaffe.github.io/count-the-notes.
Attention (as Discrete-Time Markov) Chains
Jul 23, 2025We introduce a new interpretation of the attention matrix as a discrete-time Markov chain. Our interpretation sheds light on common operations involving attention scores such as selection, summation, and averaging in a unified framework. It further extends them by considering indirect attention, propagated through the Markov chain, as opposed to previous studies that only model immediate effects. Our main observation is that tokens corresponding to semantically similar regions form a set of metastable states, where the attention clusters, while noisy attention scores tend to disperse. Metastable states and their prevalence can be easily computed through simple matrix multiplication and eigenanalysis, respectively. Using these lightweight tools, we demonstrate state-of-the-art zero-shot segmentation. Lastly, we define TokenRank -- the steady state vector of the Markov chain, which measures global token importance. We demonstrate that using it brings improvements in unconditional image generation. We believe our framework offers a fresh view of how tokens are being attended in modern visual transformers.
HOIDiNi: Human-Object Interaction through Diffusion Noise Optimization
Jun 18, 2025We present HOIDiNi, a text-driven diffusion framework for synthesizing realistic and plausible human-object interaction (HOI). HOI generation is extremely challenging since it induces strict contact accuracies alongside a diverse motion manifold. While current literature trades off between realism and physical correctness, HOIDiNi optimizes directly in the noise space of a pretrained diffusion model using Diffusion Noise Optimization (DNO), achieving both. This is made feasible thanks to our observation that the problem can be separated into two phases: an object-centric phase, primarily making discrete choices of hand-object contact locations, and a human-centric phase that refines the full-body motion to realize this blueprint. This structured approach allows for precise hand-object contact without compromising motion naturalness. Quantitative, qualitative, and subjective evaluations on the GRAB dataset alone clearly indicate HOIDiNi outperforms prior works and baselines in contact accuracy, physical validity, and overall quality. Our results demonstrate the ability to generate complex, controllable interactions, including grasping, placing, and full-body coordination, driven solely by textual prompts. https://hoidini.github.io.
Dance Like a Chicken: Low-Rank Stylization for Human Motion Diffusion
Mar 25, 2025Text-to-motion generative models span a wide range of 3D human actions but struggle with nuanced stylistic attributes such as a "Chicken" style. Due to the scarcity of style-specific data, existing approaches pull the generative prior towards a reference style, which often results in out-of-distribution low quality generations. In this work, we introduce LoRA-MDM, a lightweight framework for motion stylization that generalizes to complex actions while maintaining editability. Our key insight is that adapting the generative prior to include the style, while preserving its overall distribution, is more effective than modifying each individual motion during generation. Building on this idea, LoRA-MDM learns to adapt the prior to include the reference style using only a few samples. The style can then be used in the context of different textual prompts for generation. The low-rank adaptation shifts the motion manifold in a semantically meaningful way, enabling realistic style infusion even for actions not present in the reference samples. Moreover, preserving the distribution structure enables advanced operations such as style blending and motion editing. We compare LoRA-MDM to state-of-the-art stylized motion generation methods and demonstrate a favorable balance between text fidelity and style consistency.
AnyTop: Character Animation Diffusion with Any Topology
Feb 24, 2025Generating motion for arbitrary skeletons is a longstanding challenge in computer graphics, remaining largely unexplored due to the scarcity of diverse datasets and the irregular nature of the data. In this work, we introduce AnyTop, a diffusion model that generates motions for diverse characters with distinct motion dynamics, using only their skeletal structure as input. Our work features a transformer-based denoising network, tailored for arbitrary skeleton learning, integrating topology information into the traditional attention mechanism. Additionally, by incorporating textual joint descriptions into the latent feature representation, AnyTop learns semantic correspondences between joints across diverse skeletons. Our evaluation demonstrates that AnyTop generalizes well, even with as few as three training examples per topology, and can produce motions for unseen skeletons as well. Furthermore, our model's latent space is highly informative, enabling downstream tasks such as joint correspondence, temporal segmentation and motion editing. Our webpage, https://anytop2025.github.io/Anytop-page, includes links to videos and code.
ImageRAG: Dynamic Image Retrieval for Reference-Guided Image Generation
Feb 13, 2025


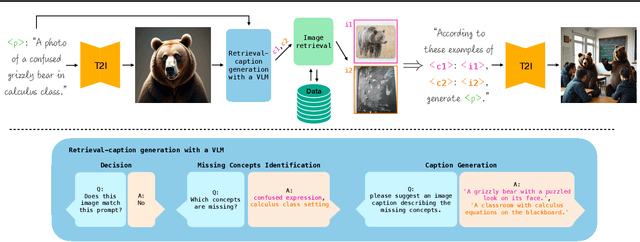
Diffusion models enable high-quality and diverse visual content synthesis. However, they struggle to generate rare or unseen concepts. To address this challenge, we explore the usage of Retrieval-Augmented Generation (RAG) with image generation models. We propose ImageRAG, a method that dynamically retrieves relevant images based on a given text prompt, and uses them as context to guide the generation process. Prior approaches that used retrieved images to improve generation, trained models specifically for retrieval-based generation. In contrast, ImageRAG leverages the capabilities of existing image conditioning models, and does not require RAG-specific training. Our approach is highly adaptable and can be applied across different model types, showing significant improvement in generating rare and fine-grained concepts using different base models. Our project page is available at: https://rotem-shalev.github.io/ImageRAG
Instant3dit: Multiview Inpainting for Fast Editing of 3D Objects
Nov 30, 2024We propose a generative technique to edit 3D shapes, represented as meshes, NeRFs, or Gaussian Splats, in approximately 3 seconds, without the need for running an SDS type of optimization. Our key insight is to cast 3D editing as a multiview image inpainting problem, as this representation is generic and can be mapped back to any 3D representation using the bank of available Large Reconstruction Models. We explore different fine-tuning strategies to obtain both multiview generation and inpainting capabilities within the same diffusion model. In particular, the design of the inpainting mask is an important factor of training an inpainting model, and we propose several masking strategies to mimic the types of edits a user would perform on a 3D shape. Our approach takes 3D generative editing from hours to seconds and produces higher-quality results compared to previous works.
CLoSD: Closing the Loop between Simulation and Diffusion for multi-task character control
Oct 04, 2024



Motion diffusion models and Reinforcement Learning (RL) based control for physics-based simulations have complementary strengths for human motion generation. The former is capable of generating a wide variety of motions, adhering to intuitive control such as text, while the latter offers physically plausible motion and direct interaction with the environment. In this work, we present a method that combines their respective strengths. CLoSD is a text-driven RL physics-based controller, guided by diffusion generation for various tasks. Our key insight is that motion diffusion can serve as an on-the-fly universal planner for a robust RL controller. To this end, CLoSD maintains a closed-loop interaction between two modules -- a Diffusion Planner (DiP), and a tracking controller. DiP is a fast-responding autoregressive diffusion model, controlled by textual prompts and target locations, and the controller is a simple and robust motion imitator that continuously receives motion plans from DiP and provides feedback from the environment. CLoSD is capable of seamlessly performing a sequence of different tasks, including navigation to a goal location, striking an object with a hand or foot as specified in a text prompt, sitting down, and getting up. https://guytevet.github.io/CLoSD-page/
ComfyGen: Prompt-Adaptive Workflows for Text-to-Image Generation
Oct 02, 2024



The practical use of text-to-image generation has evolved from simple, monolithic models to complex workflows that combine multiple specialized components. While workflow-based approaches can lead to improved image quality, crafting effective workflows requires significant expertise, owing to the large number of available components, their complex inter-dependence, and their dependence on the generation prompt. Here, we introduce the novel task of prompt-adaptive workflow generation, where the goal is to automatically tailor a workflow to each user prompt. We propose two LLM-based approaches to tackle this task: a tuning-based method that learns from user-preference data, and a training-free method that uses the LLM to select existing flows. Both approaches lead to improved image quality when compared to monolithic models or generic, prompt-independent workflows. Our work shows that prompt-dependent flow prediction offers a new pathway to improving text-to-image generation quality, complementing existing research directions in the field.