 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVControl: Efficient Framework for Training Audio-Visual Controls
Mar 25, 2026Controlling video and audio generation requires diverse modalities, from depth and pose to camera trajectories and audio transformations, yet existing approaches either train a single monolithic model for a fixed set of controls or introduce costly architectural changes for each new modality. We introduce AVControl, a lightweight, extendable framework built on LTX-2, a joint audio-visual foundation model, where each control modality is trained as a separate LoRA on a parallel canvas that provides the reference signal as additional tokens in the attention layers, requiring no architectural changes beyond the LoRA adapters themselves. We show that simply extending image-based in-context methods to video fails for structural control, and that our parallel canvas approach resolves this. On the VACE Benchmark, we outperform all evaluated baselines on depth- and pose-guided generation, inpainting, and outpainting, and show competitive results on camera control and audio-visual benchmarks. Our framework supports a diverse set of independently trained modalities: spatially-aligned controls such as depth, pose, and edges, camera trajectory with intrinsics, sparse motion control, video editing, and, to our knowledge, the first modular audio-visual controls for a joint generation model. Our method is both compute- and data-efficient: each modality requires only a small dataset and converges within a few hundred to a few thousand training steps, a fraction of the budget of monolithic alternatives. We publicly release our code and trained LoRA checkpoints.
JUST-DUB-IT: Video Dubbing via Joint Audio-Visual Diffusion
Jan 29, 2026Audio-Visual Foundation Models, which are pretrained to jointly generate sound and visual content, have recently shown an unprecedented ability to model multi-modal generation and editing, opening new opportunities for downstream tasks. Among these tasks, video dubbing could greatly benefit from such priors, yet most existing solutions still rely on complex, task-specific pipelines that struggle in real-world settings. In this work, we introduce a single-model approach that adapts a foundational audio-video diffusion model for video-to-video dubbing via a lightweight LoRA. The LoRA enables the model to condition on an input audio-video while jointly generating translated audio and synchronized facial motion. To train this LoRA, we leverage the generative model itself to synthesize paired multilingual videos of the same speaker. Specifically, we generate multilingual videos with language switches within a single clip, and then inpaint the face and audio in each half to match the language of the other half. By leveraging the rich generative prior of the audio-visual model, our approach preserves speaker identity and lip synchronization while remaining robust to complex motion and real-world dynamics. We demonstrate that our approach produces high-quality dubbed videos with improved visual fidelity, lip synchronization, and robustness compared to existing dubbing pipelines.
CAFA: a Controllable Automatic Foley Artist
Apr 15, 2025Foley is a key element in video production, refers to the process of adding an audio signal to a silent video while ensuring semantic and temporal alignment. In recent years, the rise of personalized content creation and advancements in automatic video-to-audio models have increased the demand for greater user control in the process. One possible approach is to incorporate text to guide audio generation. While supported by existing methods, challenges remain in ensuring compatibility between modalities, particularly when the text introduces additional information or contradicts the sounds naturally inferred from the visuals. In this work, we introduce CAFA (Controllable Automatic Foley Artist) a video-and-text-to-audio model that generates semantically and temporally aligned audio for a given video, guided by text input. CAFA is built upon a text-to-audio model and integrates video information through a modality adapter mechanism. By incorporating text, users can refine semantic details and introduce creative variations, guiding the audio synthesis beyond the expected video contextual cues. Experiments show that besides its superior quality in terms of semantic alignment and audio-visual synchronization the proposed method enable high textual controllability as demonstrated in subjective and objective evaluations.
Controllable Automatic Foley Artist
Apr 09, 2025Foley is a key element in video production, refers to the process of adding an audio signal to a silent video while ensuring semantic and temporal alignment. In recent years, the rise of personalized content creation and advancements in automatic video-to-audio models have increased the demand for greater user control in the process. One possible approach is to incorporate text to guide audio generation. While supported by existing methods, challenges remain in ensuring compatibility between modalities, particularly when the text introduces additional information or contradicts the sounds naturally inferred from the visuals. In this work, we introduce CAFA (Controllable Automatic Foley Artist) a video-and-text-to-audio model that generates semantically and temporally aligned audio for a given video, guided by text input. CAFA is built upon a text-to-audio model and integrates video information through a modality adapter mechanism. By incorporating text, users can refine semantic details and introduce creative variations, guiding the audio synthesis beyond the expected video contextual cues. Experiments show that besides its superior quality in terms of semantic alignment and audio-visual synchronization the proposed method enable high textual controllability as demonstrated in subjective and objective evaluations.
V-LASIK: Consistent Glasses-Removal from Videos Using Synthetic Data
Jun 20, 2024Diffusion-based generative models have recently shown remarkable image and video editing capabilities. However, local video editing, particularly removal of small attributes like glasses, remains a challenge. Existing methods either alter the videos excessively, generate unrealistic artifacts, or fail to perform the requested edit consistently throughout the video. In this work, we focus on consistent and identity-preserving removal of glasses in videos, using it as a case study for consistent local attribute removal in videos. Due to the lack of paired data, we adopt a weakly supervised approach and generate synthetic imperfect data, using an adjusted pretrained diffusion model. We show that despite data imperfection, by learning from our generated data and leveraging the prior of pretrained diffusion models, our model is able to perform the desired edit consistently while preserving the original video content. Furthermore, we exemplify the generalization ability of our method to other local video editing tasks by applying it successfully to facial sticker-removal. Our approach demonstrates significant improvement over existing methods, showcasing the potential of leveraging synthetic data and strong video priors for local video editing tasks.
Diffusing Colors: Image Colorization with Text Guided Diffusion
Dec 07, 2023



The colorization of grayscale images is a complex and subjective task with significant challenges. Despite recent progress in employing large-scale datasets with deep neural networks, difficulties with controllability and visual quality persist. To tackle these issues, we present a novel image colorization framework that utilizes image diffusion techniques with granular text prompts. This integration not only produces colorization outputs that are semantically appropriate but also greatly improves the level of control users have over the colorization process. Our method provides a balance between automation and control, outperforming existing techniques in terms of visual quality and semantic coherence. We leverage a pretrained generative Diffusion Model, and show that we can finetune it for the colorization task without losing its generative power or attention to text prompts. Moreover, we present a novel CLIP-based ranking model that evaluates color vividness, enabling automatic selection of the most suitable level of vividness based on the specific scene semantics. Our approach holds potential particularly for color enhancement and historical image colorization.
Temporally stable video segmentation without video annotations
Oct 17, 2021
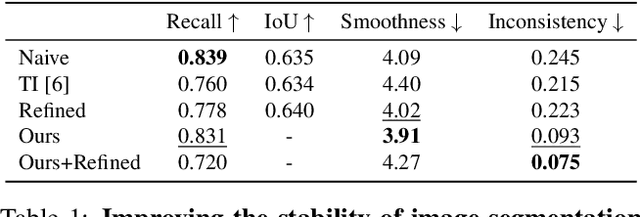
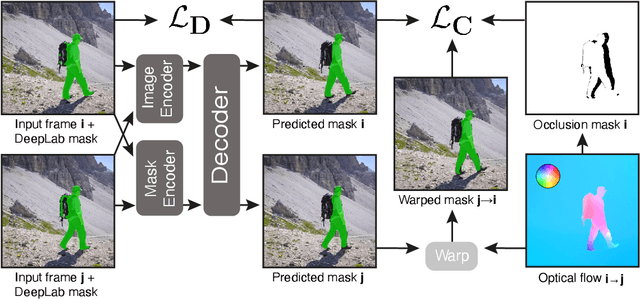
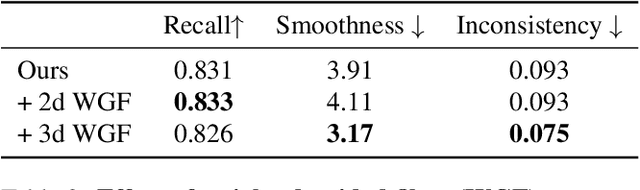
Temporally consistent dense video annotations are scarce and hard to collect. In contrast, image segmentation datasets (and pre-trained models) are ubiquitous, and easier to label for any novel task. In this paper, we introduce a method to adapt still image segmentation models to video in an unsupervised manner, by using an optical flow-based consistency measure. To ensure that the inferred segmented videos appear more stable in practice, we verify that the consistency measure is well correlated with human judgement via a user study. Training a new multi-input multi-output decoder using this measure as a loss, together with a technique for refining current image segmentation datasets and a temporal weighted-guided filter, we observe stability improvements in the generated segmented videos with minimal loss of accuracy.
Endless Loops: Detecting and Animating Periodic Patterns in Still Images
May 19, 2021
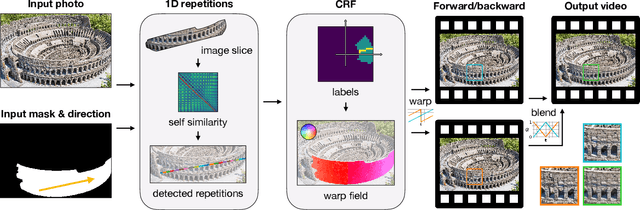

We present an algorithm for producing a seamless animated loop from a single image. The algorithm detects periodic structures, such as the windows of a building or the steps of a staircase, and generates a non-trivial displacement vector field that maps each segment of the structure onto a neighboring segment along a user- or auto-selected main direction of motion. This displacement field is used, together with suitable temporal and spatial smoothing, to warp the image and produce the frames of a continuous animation loop. Our cinemagraphs are created in under a second on a mobile device. Over 140,000 users downloaded our app and exported over 350,000 cinemagraphs. Moreover, we conducted two user studies that show that users prefer our method for creating surreal and structured cinemagraphs compared to more manual approaches and compared to previous methods.
* SIGGRAPH 2021. Project page: https://pub.res.lightricks.com/endless-loops/ . Video: https://youtu.be/8ZYUvxWuD2Y
Clear Skies Ahead: Towards Real-Time Automatic Sky Replacement in Video
Mar 06, 2019



Digital videos such as those captured by a smartphone often exhibit exposure inconsistencies, a poorly exposed sky, or simply suffer from an uninteresting or plain looking sky. Professionals may edit these videos using advanced and time-consuming tools unavailable to most users, to replace the sky with a more expressive or imaginative sky. In this work, we propose an algorithm for automatic replacement of the sky region in a video with a different sky, providing nonprofessional users with a simple yet efficient tool to seamlessly replace the sky. The method is fast, achieving close to real-time performance on mobile devices and the user's involvement can remain as limited as simply selecting the replacement sky.
Neural separation of observed and unobserved distributions
Nov 30, 2018



Separating mixed distributions is a long standing challenge for machine learning and signal processing. Applications include: single-channel multi-speaker separation (cocktail party problem), singing voice separation and separating reflections from images. Most current methods either rely on making strong assumptions on the source distributions (e.g. sparsity, low rank, repetitiveness) or rely on having training samples of each source in the mixture. In this work, we tackle the scenario of extracting an unobserved distribution additively mixed with a signal from an observed (arbitrary) distribution. We introduce a new method: Neural Egg Separation - an iterative method that learns to separate the known distribution from progressively finer estimates of the unknown distribution. In some settings, Neural Egg Separation is initialization sensitive, we therefore introduce GLO Masking which ensures a good initialization. Extensive experiments show that our method outperforms current methods that use the same level of supervision and often achieves similar performance to full supervision.