 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAFA: a Controllable Automatic Foley Artist
Apr 15, 2025Foley is a key element in video production, refers to the process of adding an audio signal to a silent video while ensuring semantic and temporal alignment. In recent years, the rise of personalized content creation and advancements in automatic video-to-audio models have increased the demand for greater user control in the process. One possible approach is to incorporate text to guide audio generation. While supported by existing methods, challenges remain in ensuring compatibility between modalities, particularly when the text introduces additional information or contradicts the sounds naturally inferred from the visuals. In this work, we introduce CAFA (Controllable Automatic Foley Artist) a video-and-text-to-audio model that generates semantically and temporally aligned audio for a given video, guided by text input. CAFA is built upon a text-to-audio model and integrates video information through a modality adapter mechanism. By incorporating text, users can refine semantic details and introduce creative variations, guiding the audio synthesis beyond the expected video contextual cues. Experiments show that besides its superior quality in terms of semantic alignment and audio-visual synchronization the proposed method enable high textual controllability as demonstrated in subjective and objective evaluations.
Controllable Automatic Foley Artist
Apr 09, 2025Foley is a key element in video production, refers to the process of adding an audio signal to a silent video while ensuring semantic and temporal alignment. In recent years, the rise of personalized content creation and advancements in automatic video-to-audio models have increased the demand for greater user control in the process. One possible approach is to incorporate text to guide audio generation. While supported by existing methods, challenges remain in ensuring compatibility between modalities, particularly when the text introduces additional information or contradicts the sounds naturally inferred from the visuals. In this work, we introduce CAFA (Controllable Automatic Foley Artist) a video-and-text-to-audio model that generates semantically and temporally aligned audio for a given video, guided by text input. CAFA is built upon a text-to-audio model and integrates video information through a modality adapter mechanism. By incorporating text, users can refine semantic details and introduce creative variations, guiding the audio synthesis beyond the expected video contextual cues. Experiments show that besides its superior quality in terms of semantic alignment and audio-visual synchronization the proposed method enable high textual controllability as demonstrated in subjective and objective evaluations.
Stereo Magnification with Multi-Layer Images
Jan 13, 2022
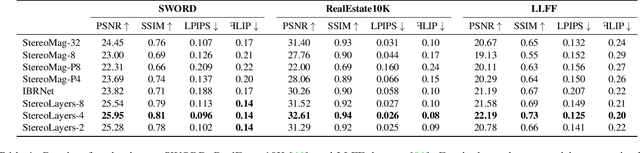

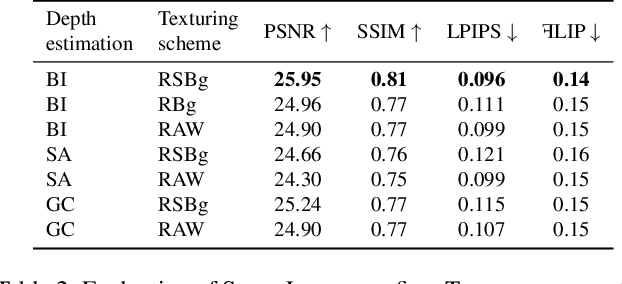
Representing scenes with multiple semi-transparent colored layers has been a popular and successful choice for real-time novel view synthesis. Existing approaches infer colors and transparency values over regularly-spaced layers of planar or spherical shape. In this work, we introduce a new view synthesis approach based on multiple semi-transparent layers with scene-adapted geometry. Our approach infers such representations from stereo pairs in two stages. The first stage infers the geometry of a small number of data-adaptive layers from a given pair of views. The second stage infers the color and the transparency values for these layers producing the final representation for novel view synthesis. Importantly, both stages are connected through a differentiable renderer and are trained in an end-to-end manner. In the experiments, we demonstrate the advantage of the proposed approach over the use of regularly-spaced layers with no adaptation to scene geometry. Despite being orders of magnitude faster during rendering, our approach also outperforms a recently proposed IBRNet system based on implicit geometry representation. See results at https://samsunglabs.github.io/StereoLayers .
Image Generators with Conditionally-Independent Pixel Synthesis
Nov 27, 2020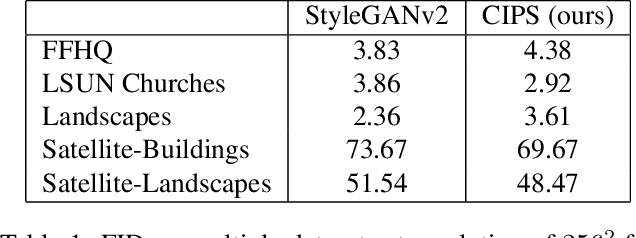
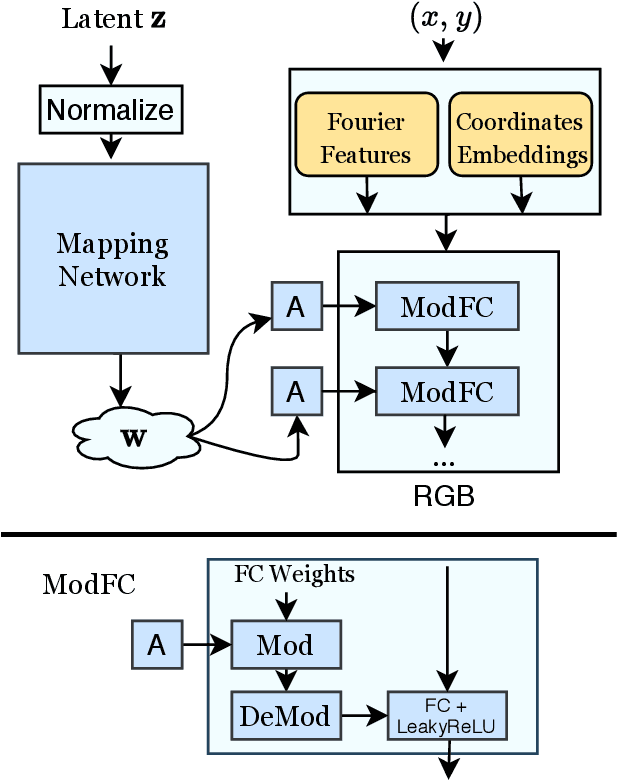
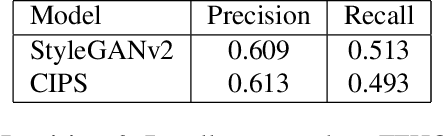
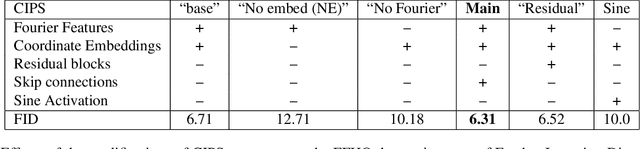
Existing image generator networks rely heavily on spatial convolutions and, optionally, self-attention blocks in order to gradually synthesize images in a coarse-to-fine manner. Here, we present a new architecture for image generators, where the color value at each pixel is computed independently given the value of a random latent vector and the coordinate of that pixel. No spatial convolutions or similar operations that propagate information across pixels are involved during the synthesis. We analyze the modeling capabilities of such generators when trained in an adversarial fashion, and observe the new generators to achieve similar generation quality to state-of-the-art convolutional generators. We also investigate several interesting properties unique to the new architecture.
High-Resolution Daytime Translation Without Domain Labels
Mar 23, 2020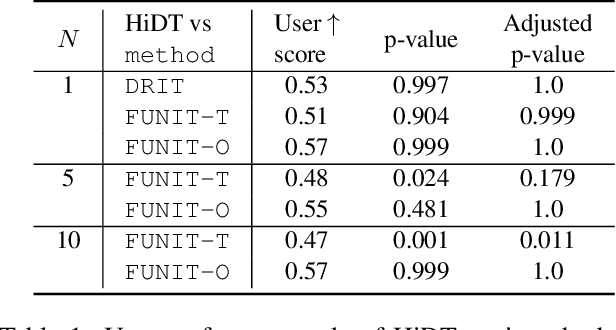
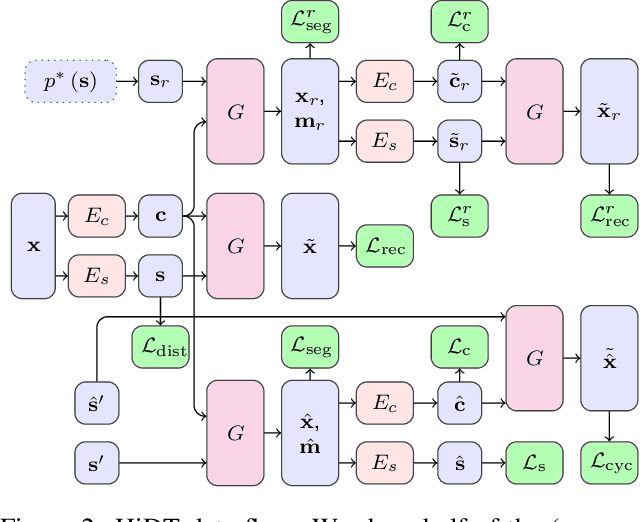
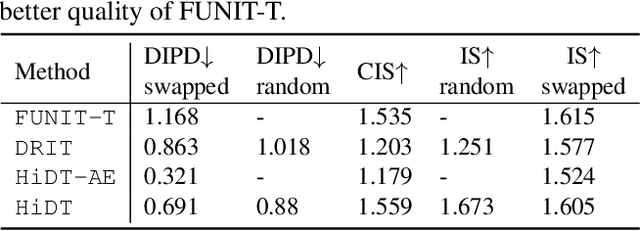
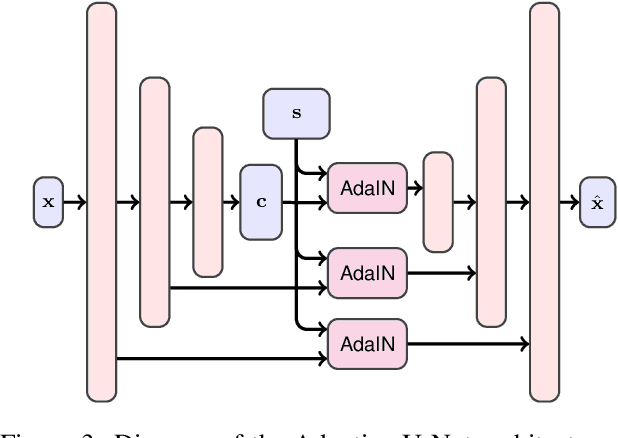
Modeling daytime changes in high resolution photographs, e.g., re-rendering the same scene under different illuminations typical for day, night, or dawn, is a challenging image manipulation task. We present the high-resolution daytime translation (HiDT) model for this task. HiDT combines a generative image-to-image model and a new upsampling scheme that allows to apply image translation at high resolution. The model demonstrates competitive results in terms of both commonly used GAN metrics and human evaluation. Importantly, this good performance comes as a result of training on a dataset of still landscape images with no daytime labels available. Our results are available at https://saic-mdal.github.io/HiDT/.
Learning State Representations in Complex Systems with Multimodal Data
Nov 30, 2018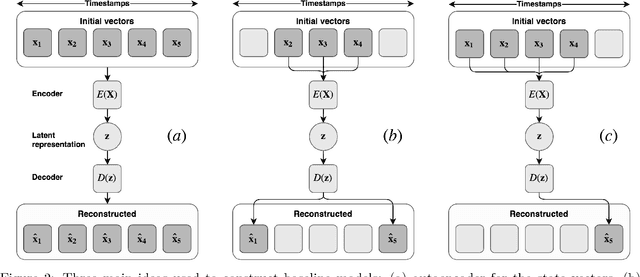

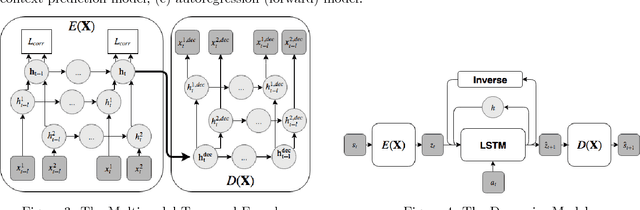
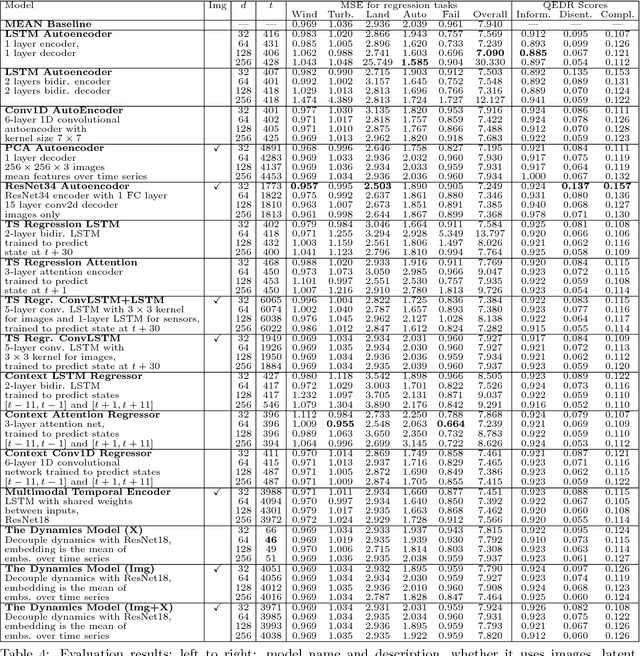
Representation learning becomes especially important for complex systems with multimodal data sources such as cameras or sensors. Recent advances in reinforcement learning and optimal control make it possible to design control algorithms on these latent representations, but the field still lacks a large-scale standard dataset for unified comparison. In this work, we present a large-scale dataset and evaluation framework for representation learning for the complex task of landing an airplane. We implement and compare several approaches to representation learning on this dataset in terms of the quality of simple supervised learning tasks and disentanglement scores. The resulting representations can be used for further tasks such as anomaly detection, optimal control, model-based reinforcement learning, and other applications.
Label Denoising with Large Ensembles of Heterogeneous Neural Networks
Sep 12, 2018
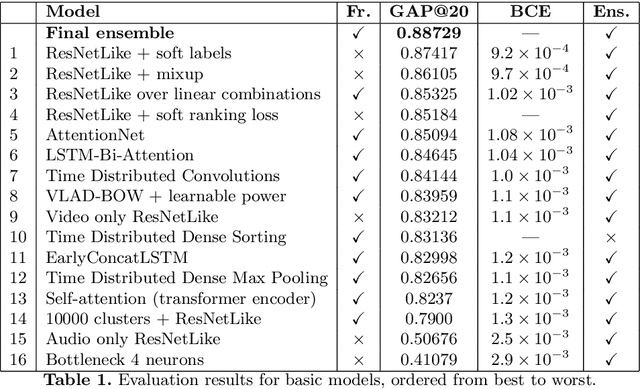
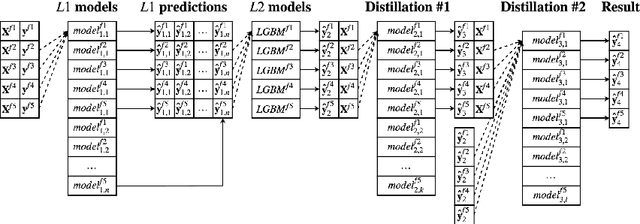
Despite recent advances in computer vision based on various convolutional architectures, video understanding remains an important challenge. In this work, we present and discuss a top solution for the large-scale video classification (labeling) problem introduced as a Kaggle competition based on the YouTube-8M dataset. We show and compare different approaches to preprocessing, data augmentation, model architectures, and model combination. Our final model is based on a large ensemble of video- and frame-level models but fits into rather limiting hardware constraints. We apply an approach based on knowledge distillation to deal with noisy labels in the original dataset and the recently developed mixup technique to improve the basic models.