 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandling Delay in Real-Time Reinforcement Learning
Mar 30, 2025Real-time reinforcement learning (RL) introduces several challenges. First, policies are constrained to a fixed number of actions per second due to hardware limitations. Second, the environment may change while the network is still computing an action, leading to observational delay. The first issue can partly be addressed with pipelining, leading to higher throughput and potentially better policies. However, the second issue remains: if each neuron operates in parallel with an execution time of $\tau$, an $N$-layer feed-forward network experiences observation delay of $\tau N$. Reducing the number of layers can decrease this delay, but at the cost of the network's expressivity. In this work, we explore the trade-off between minimizing delay and network's expressivity. We present a theoretically motivated solution that leverages temporal skip connections combined with history-augmented observations. We evaluate several architectures and show that those incorporating temporal skip connections achieve strong performance across various neuron execution times, reinforcement learning algorithms, and environments, including four Mujoco tasks and all MinAtar games. Moreover, we demonstrate parallel neuron computation can accelerate inference by 6-350% on standard hardware. Our investigation into temporal skip connections and parallel computations paves the way for more efficient RL agents in real-time setting.
Thinker: Learning to Plan and Act
Jul 27, 2023We propose the Thinker algorithm, a novel approach that enables reinforcement learning agents to autonomously interact with and utilize a learned world model. The Thinker algorithm wraps the environment with a world model and introduces new actions designed for interacting with the world model. These model-interaction actions enable agents to perform planning by proposing alternative plans to the world model before selecting a final action to execute in the environment. This approach eliminates the need for hand-crafted planning algorithms by enabling the agent to learn how to plan autonomously and allows for easy interpretation of the agent's plan with visualization. We demonstrate the algorithm's effectiveness through experimental results in the game of Sokoban and the Atari 2600 benchmark, where the Thinker algorithm achieves state-of-the-art performance and competitive results, respectively. Visualizations of agents trained with the Thinker algorithm demonstrate that they have learned to plan effectively with the world model to select better actions. The algorithm's generality opens a new research direction on how a world model can be used in reinforcement learning and how planning can be seamlessly integrated into an agent's decision-making process.
Embedded Ensembles: Infinite Width Limit and Operating Regimes
Feb 24, 2022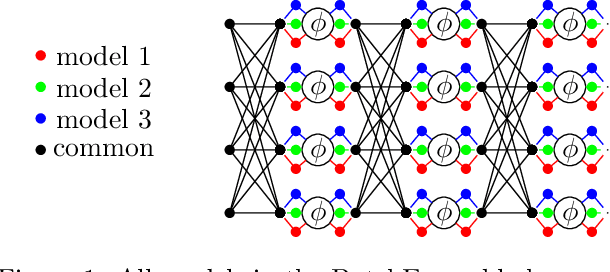
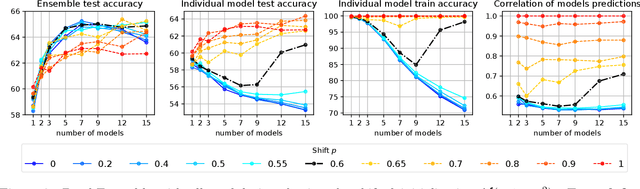
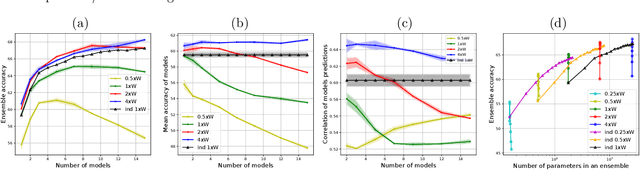
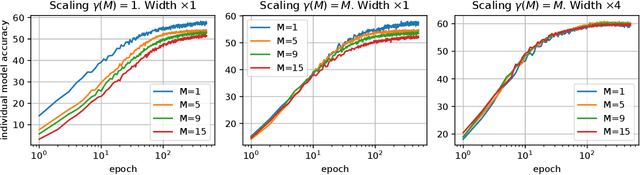
A memory efficient approach to ensembling neural networks is to share most weights among the ensembled models by means of a single reference network. We refer to this strategy as Embedded Ensembling (EE); its particular examples are BatchEnsembles and Monte-Carlo dropout ensembles. In this paper we perform a systematic theoretical and empirical analysis of embedded ensembles with different number of models. Theoretically, we use a Neural-Tangent-Kernel-based approach to derive the wide network limit of the gradient descent dynamics. In this limit, we identify two ensemble regimes - independent and collective - depending on the architecture and initialization strategy of ensemble models. We prove that in the independent regime the embedded ensemble behaves as an ensemble of independent models. We confirm our theoretical prediction with a wide range of experiments with finite networks, and further study empirically various effects such as transition between the two regimes, scaling of ensemble performance with the network width and number of models, and dependence of performance on a number of architecture and hyperparameter choices.
Image Generators with Conditionally-Independent Pixel Synthesis
Nov 27, 2020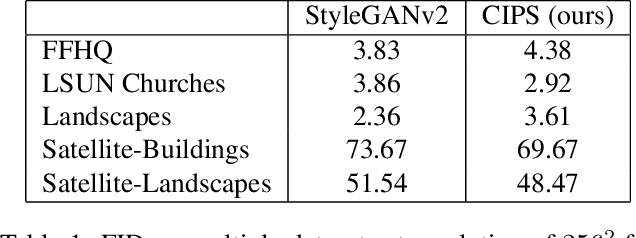
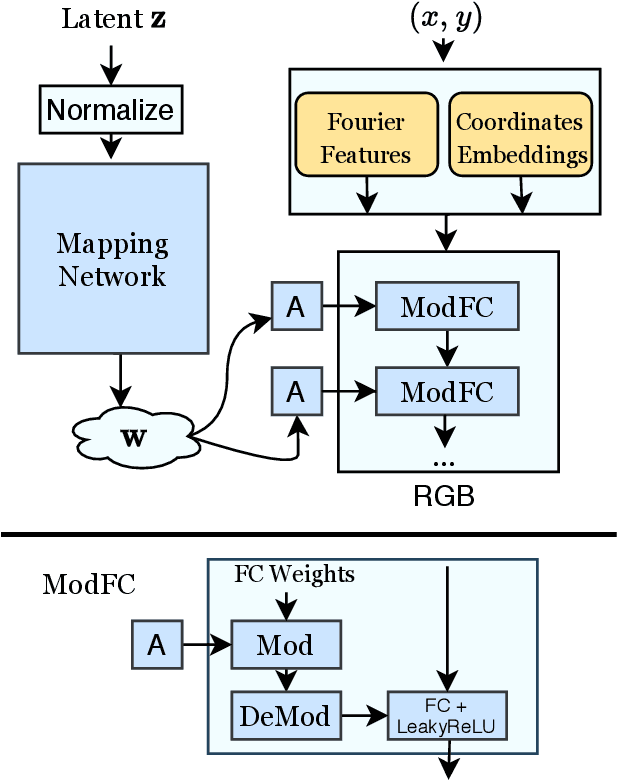
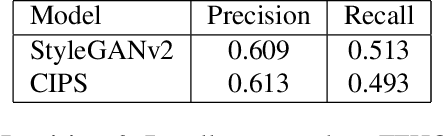
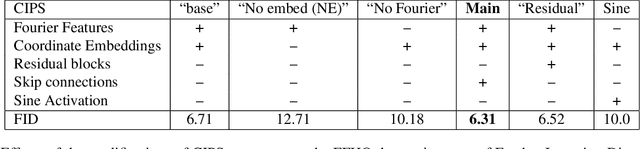
Existing image generator networks rely heavily on spatial convolutions and, optionally, self-attention blocks in order to gradually synthesize images in a coarse-to-fine manner. Here, we present a new architecture for image generators, where the color value at each pixel is computed independently given the value of a random latent vector and the coordinate of that pixel. No spatial convolutions or similar operations that propagate information across pixels are involved during the synthesis. We analyze the modeling capabilities of such generators when trained in an adversarial fashion, and observe the new generators to achieve similar generation quality to state-of-the-art convolutional generators. We also investigate several interesting properties unique to the new architecture.
Low-loss connection of weight vectors: distribution-based approaches
Aug 03, 2020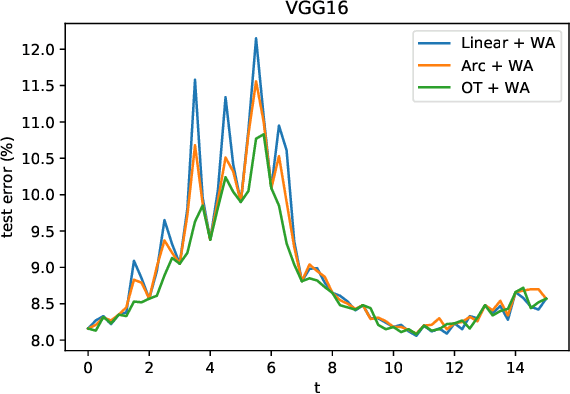

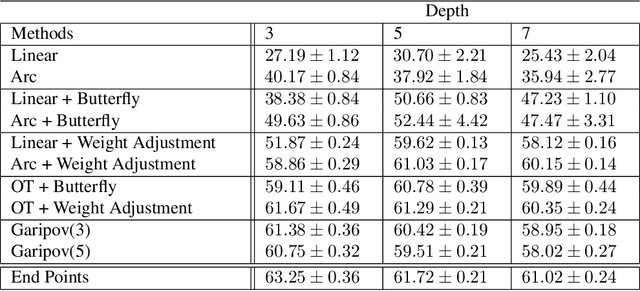
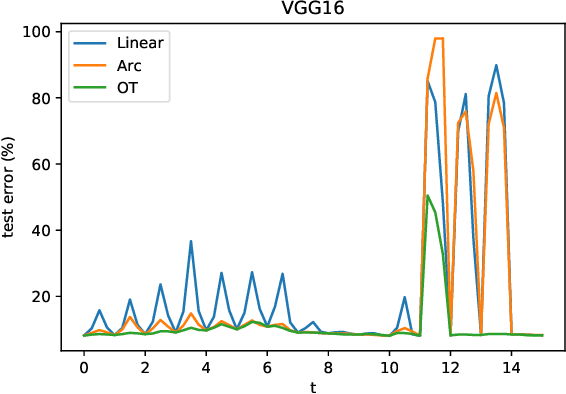
Recent research shows that sublevel sets of the loss surfaces of overparameterized networks are connected, exactly or approximately. We describe and compare experimentally a panel of methods used to connect two low-loss points by a low-loss curve on this surface. Our methods vary in accuracy and complexity. Most of our methods are based on "macroscopic" distributional assumptions, and some are insensitive to the detailed properties of the points to be connected. Some methods require a prior training of a "global connection model" which can then be applied to any pair of points. The accuracy of the method generally correlates with its complexity and sensitivity to the endpoint detail.
High-Resolution Daytime Translation Without Domain Labels
Mar 23, 2020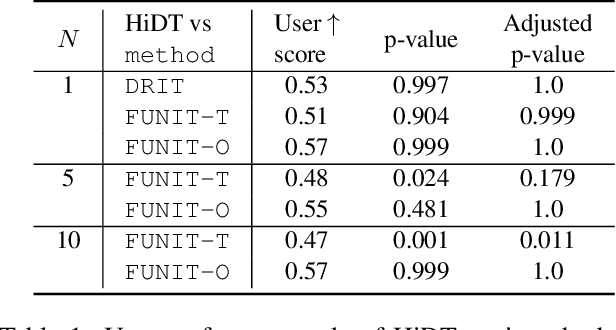
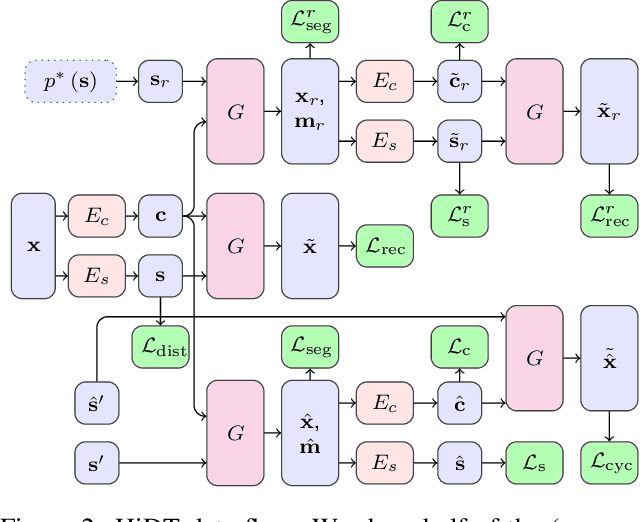
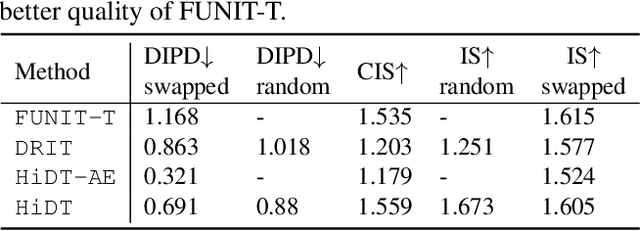
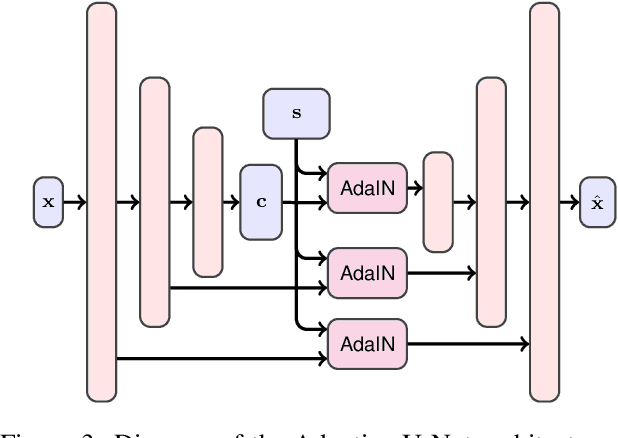
Modeling daytime changes in high resolution photographs, e.g., re-rendering the same scene under different illuminations typical for day, night, or dawn, is a challenging image manipulation task. We present the high-resolution daytime translation (HiDT) model for this task. HiDT combines a generative image-to-image model and a new upsampling scheme that allows to apply image translation at high resolution. The model demonstrates competitive results in terms of both commonly used GAN metrics and human evaluation. Importantly, this good performance comes as a result of training on a dataset of still landscape images with no daytime labels available. Our results are available at https://saic-mdal.github.io/HiDT/.