 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Conformal Prediction for Improving Factuality of Generations by Large Language Models
Apr 15, 2026Large language models (LLMs) are prone to generating factually incorrect outputs. Recent work has applied conformal prediction to provide uncertainty estimates and statistical guarantees for the factuality of LLM generations. However, existing approaches are typically not prompt-adaptive, limiting their ability to capture input-dependent variability. As a result, they may filter out too few items (leading to over-coverage) or too many (under-coverage) for a given task or prompt. We propose an adaptive conformal prediction approach that extends conformal score transformation methods to LLMs, with applications to long-form generation and multiple-choice question answering. This enables prompt-dependent calibration, retaining marginal coverage guarantees while improving conditional coverage. In addition, the approach naturally supports selective prediction, allowing unreliable claims or answer choices to be filtered out in downstream applications. We evaluate our approach on multiple white-box models across diverse domains and show that it significantly outperforms existing baselines in terms of conditional coverage.
Why Don't You Know? Evaluating the Impact of Uncertainty Sources on Uncertainty Quantification in LLMs
Apr 12, 2026As Large Language Models (LLMs) are increasingly deployed in real-world applications, reliable uncertainty quantification (UQ) becomes critical for safe and effective use. Most existing UQ approaches for language models aim to produce a single confidence score -- for example, estimating the probability that a model's answer is correct. However, uncertainty in natural language tasks arises from multiple distinct sources, including model knowledge gaps, output variability, and input ambiguity, which have different implications for system behavior and user interaction. In this work, we study how the source of uncertainty impacts the behavior and effectiveness of existing UQ methods. To enable controlled analysis, we introduce a new dataset that explicitly categorizes uncertainty sources, allowing systematic evaluation of UQ performance under each condition. Our experiments reveal that while many UQ methods perform well when uncertainty stems solely from model knowledge limitations, their performance degrades or becomes misleading when other sources are introduced. These findings highlight the need for uncertainty-aware methods that explicitly account for the source of uncertainty in large language models.
ReDAct: Uncertainty-Aware Deferral for LLM Agents
Apr 08, 2026Recently, LLM-based agents have become increasingly popular across many applications, including complex sequential decision-making problems. However, they inherit the tendency of LLMs to hallucinate, leading to incorrect decisions. In sequential settings, even a single mistake can irreversibly degrade the trajectory, making hallucinations an even bigger problem. Although larger LLMs hallucinate less, they incur a significantly higher per-token cost. In this paper, we address this tradeoff by proposing ReDAct (Reason-Defer-Act). In ReDAct, an agent is equipped with two LLMs: a small, cheap model used by default, and a large, more reliable but expensive model. When the predictive uncertainty of the small model exceeds a calibrated threshold, the decision is deferred to the large model. We evaluate our approach in text-based embodied environments such as ALFWorld and MiniGrid and show that deferring only about 15% of decisions to the large model can match the quality of using it exclusively, while significantly reducing inference costs.
IDLM: Inverse-distilled Diffusion Language Models
Feb 22, 2026Diffusion Language Models (DLMs) have recently achieved strong results in text generation. However, their multi-step sampling leads to slow inference, limiting practical use. To address this, we extend Inverse Distillation, a technique originally developed to accelerate continuous diffusion models, to the discrete setting. Nonetheless, this extension introduces both theoretical and practical challenges. From a theoretical perspective, the inverse distillation objective lacks uniqueness guarantees, which may lead to suboptimal solutions. From a practical standpoint, backpropagation in the discrete space is non-trivial and often unstable. To overcome these challenges, we first provide a theoretical result demonstrating that our inverse formulation admits a unique solution, thereby ensuring valid optimization. We then introduce gradient-stable relaxations to support effective training. As a result, experiments on multiple DLMs show that our method, Inverse-distilled Diffusion Language Models (IDLM), reduces the number of inference steps by 4x-64x, while preserving the teacher model's entropy and generative perplexity.
Don't Throw Away Your Beams: Improving Consistency-based Uncertainties in LLMs via Beam Search
Dec 10, 2025Consistency-based methods have emerged as an effective approach to uncertainty quantification (UQ) in large language models. These methods typically rely on several generations obtained via multinomial sampling, measuring their agreement level. However, in short-form QA, multinomial sampling is prone to producing duplicates due to peaked distributions, and its stochasticity introduces considerable variance in uncertainty estimates across runs. We introduce a new family of methods that employ beam search to generate candidates for consistency-based UQ, yielding improved performance and reduced variance compared to multinomial sampling. We also provide a theoretical lower bound on the beam set probability mass under which beam search achieves a smaller error than multinomial sampling. We empirically evaluate our approach on six QA datasets and find that its consistent improvements over multinomial sampling lead to state-of-the-art UQ performance.
Uncertainty Quantification for Regression using Proper Scoring Rules
Sep 30, 2025
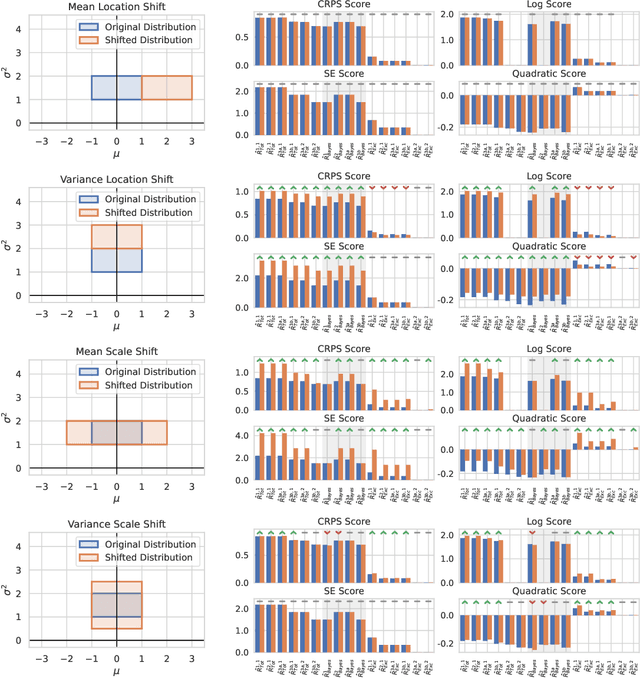


Quantifying uncertainty of machine learning model predictions is essential for reliable decision-making, especially in safety-critical applications. Recently, uncertainty quantification (UQ) theory has advanced significantly, building on a firm basis of learning with proper scoring rules. However, these advances were focused on classification, while extending these ideas to regression remains challenging. In this work, we introduce a unified UQ framework for regression based on proper scoring rules, such as CRPS, logarithmic, squared error, and quadratic scores. We derive closed-form expressions for the resulting uncertainty measures under practical parametric assumptions and show how to estimate them using ensembles of models. In particular, the derived uncertainty measures naturally decompose into aleatoric and epistemic components. The framework recovers popular regression UQ measures based on predictive variance and differential entropy. Our broad evaluation on synthetic and real-world regression datasets provides guidance for selecting reliable UQ measures.
Who to Trust? Aggregating Client Knowledge in Logit-Based Federated Learning
Sep 18, 2025

Federated learning (FL) usually shares model weights or gradients, which is costly for large models. Logit-based FL reduces this cost by sharing only logits computed on a public proxy dataset. However, aggregating information from heterogeneous clients is still challenging. This paper studies this problem, introduces and compares three logit aggregation methods: simple averaging, uncertainty-weighted averaging, and a learned meta-aggregator. Evaluated on MNIST and CIFAR-10, these methods reduce communication overhead, improve robustness under non-IID data, and achieve accuracy competitive with centralized training.
Faithfulness-Aware Uncertainty Quantification for Fact-Checking the Output of Retrieval Augmented Generation
May 28, 2025Large Language Models (LLMs) enhanced with external knowledge retrieval, an approach known as Retrieval-Augmented Generation (RAG), have shown strong performance in open-domain question answering. However, RAG systems remain susceptible to hallucinations: factually incorrect outputs that may arise either from inconsistencies in the model's internal knowledge or incorrect use of the retrieved context. Existing approaches often conflate factuality with faithfulness to the retrieved context, misclassifying factually correct statements as hallucinations if they are not directly supported by the retrieval. In this paper, we introduce FRANQ (Faithfulness-based Retrieval Augmented UNcertainty Quantification), a novel method for hallucination detection in RAG outputs. FRANQ applies different Uncertainty Quantification (UQ) techniques to estimate factuality based on whether a statement is faithful to the retrieved context or not. To evaluate FRANQ and other UQ techniques for RAG, we present a new long-form Question Answering (QA) dataset annotated for both factuality and faithfulness, combining automated labeling with manual validation of challenging examples. Extensive experiments on long- and short-form QA across multiple datasets and LLMs show that FRANQ achieves more accurate detection of factual errors in RAG-generated responses compared to existing methods.
Uncertainty-Aware Attention Heads: Efficient Unsupervised Uncertainty Quantification for LLMs
May 26, 2025Large language models (LLMs) exhibit impressive fluency, but often produce critical errors known as "hallucinations". Uncertainty quantification (UQ) methods are a promising tool for coping with this fundamental shortcoming. Yet, existing UQ methods face challenges such as high computational overhead or reliance on supervised learning. Here, we aim to bridge this gap. In particular, we propose RAUQ (Recurrent Attention-based Uncertainty Quantification), an unsupervised approach that leverages intrinsic attention patterns in transformers to detect hallucinations efficiently. By analyzing attention weights, we identified a peculiar pattern: drops in attention to preceding tokens are systematically observed during incorrect generations for certain "uncertainty-aware" heads. RAUQ automatically selects such heads, recurrently aggregates their attention weights and token-level confidences, and computes sequence-level uncertainty scores in a single forward pass. Experiments across 4 LLMs and 12 question answering, summarization, and translation tasks demonstrate that RAUQ yields excellent results, outperforming state-of-the-art UQ methods using minimal computational overhead (<1% latency). Moreover, it requires no task-specific labels and no careful hyperparameter tuning, offering plug-and-play real-time hallucination detection in white-box LLMs.
UNCERTAINTY-LINE: Length-Invariant Estimation of Uncertainty for Large Language Models
May 25, 2025Large Language Models (LLMs) have become indispensable tools across various applications, making it more important than ever to ensure the quality and the trustworthiness of their outputs. This has led to growing interest in uncertainty quantification (UQ) methods for assessing the reliability of LLM outputs. Many existing UQ techniques rely on token probabilities, which inadvertently introduces a bias with respect to the length of the output. While some methods attempt to account for this, we demonstrate that such biases persist even in length-normalized approaches. To address the problem, here we propose UNCERTAINTY-LINE: (Length-INvariant Estimation), a simple debiasing procedure that regresses uncertainty scores on output length and uses the residuals as corrected, length-invariant estimates. Our method is post-hoc, model-agnostic, and applicable to a range of UQ measures. Through extensive evaluation on machine translation, summarization, and question-answering tasks, we demonstrate that UNCERTAINTY-LINE: consistently improves over even nominally length-normalized UQ methods uncertainty estimates across multiple metrics and models.