 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Improving Pretraining: using post-trained models to pretrain better models
Jan 29, 2026Ensuring safety, factuality and overall quality in the generations of large language models is a critical challenge, especially as these models are increasingly deployed in real-world applications. The prevailing approach to addressing these issues involves collecting expensive, carefully curated datasets and applying multiple stages of fine-tuning and alignment. However, even this complex pipeline cannot guarantee the correction of patterns learned during pretraining. Therefore, addressing these issues during pretraining is crucial, as it shapes a model's core behaviors and prevents unsafe or hallucinated outputs from becoming deeply embedded. To tackle this issue, we introduce a new pretraining method that streams documents and uses reinforcement learning (RL) to improve the next K generated tokens at each step. A strong, post-trained model judges candidate generations -- including model rollouts, the original suffix, and a rewritten suffix -- for quality, safety, and factuality. Early in training, the process relies on the original and rewritten suffixes; as the model improves, RL rewards high-quality rollouts. This approach builds higher quality, safer, and more factual models from the ground up. In experiments, our method gives 36.2% and 18.5% relative improvements over standard pretraining in terms of factuality and safety, and up to 86.3% win rate improvements in overall generation quality.
Faithfulness-Aware Uncertainty Quantification for Fact-Checking the Output of Retrieval Augmented Generation
May 28, 2025Large Language Models (LLMs) enhanced with external knowledge retrieval, an approach known as Retrieval-Augmented Generation (RAG), have shown strong performance in open-domain question answering. However, RAG systems remain susceptible to hallucinations: factually incorrect outputs that may arise either from inconsistencies in the model's internal knowledge or incorrect use of the retrieved context. Existing approaches often conflate factuality with faithfulness to the retrieved context, misclassifying factually correct statements as hallucinations if they are not directly supported by the retrieval. In this paper, we introduce FRANQ (Faithfulness-based Retrieval Augmented UNcertainty Quantification), a novel method for hallucination detection in RAG outputs. FRANQ applies different Uncertainty Quantification (UQ) techniques to estimate factuality based on whether a statement is faithful to the retrieved context or not. To evaluate FRANQ and other UQ techniques for RAG, we present a new long-form Question Answering (QA) dataset annotated for both factuality and faithfulness, combining automated labeling with manual validation of challenging examples. Extensive experiments on long- and short-form QA across multiple datasets and LLMs show that FRANQ achieves more accurate detection of factual errors in RAG-generated responses compared to existing methods.
Diverse Preference Optimization
Jan 31, 2025



Post-training of language models, either through reinforcement learning, preference optimization or supervised finetuning, tends to sharpen the output probability distribution and reduce the diversity of generated responses. This is particularly a problem for creative generative tasks where varied responses are desired. In this work we introduce Diverse Preference Optimization (DivPO), an optimization method which learns to generate much more diverse responses than standard pipelines, while maintaining the quality of the generations. In DivPO, preference pairs are selected by first considering a pool of responses, and a measure of diversity among them, and selecting chosen examples as being more rare but high quality, while rejected examples are more common, but low quality. DivPO results in generating 45.6% more diverse persona attributes, and an 74.6% increase in story diversity, while maintaining similar win rates as standard baselines.
Adaptive Decoding via Latent Preference Optimization
Nov 14, 2024



During language model decoding, it is known that using higher temperature sampling gives more creative responses, while lower temperatures are more factually accurate. However, such models are commonly applied to general instruction following, which involves both creative and fact seeking tasks, using a single fixed temperature across all examples and tokens. In this work, we introduce Adaptive Decoding, a layer added to the model to select the sampling temperature dynamically at inference time, at either the token or example level, in order to optimize performance. To learn its parameters we introduce Latent Preference Optimization (LPO) a general approach to train discrete latent variables such as choices of temperature. Our method outperforms all fixed decoding temperatures across a range of tasks that require different temperatures, including UltraFeedback, Creative Story Writing, and GSM8K.
Towards Aligning Language Models with Textual Feedback
Jul 24, 2024We present ALT (ALignment with Textual feedback), an approach that aligns language models with user preferences expressed in text. We argue that text offers greater expressiveness, enabling users to provide richer feedback than simple comparative preferences and this richer feedback can lead to more efficient and effective alignment. ALT aligns the model by conditioning its generation on the textual feedback. Our method relies solely on language modeling techniques and requires minimal hyper-parameter tuning, though it still presents the main benefits of RL-based alignment algorithms and can effectively learn from textual feedback. We explore the efficacy and efficiency of textual feedback across different tasks such as toxicity reduction, summarization, and dialog response generation. We find that ALT outperforms PPO for the task of toxicity reduction while being able to match its performance on summarization with only 20% of the samples. We also explore how ALT can be used with feedback provided by an existing LLM where we explore an LLM providing constrained and unconstrained textual feedback. We also outline future directions to align models with natural language feedback.
Implicit Personalization in Language Models: A Systematic Study
May 23, 2024
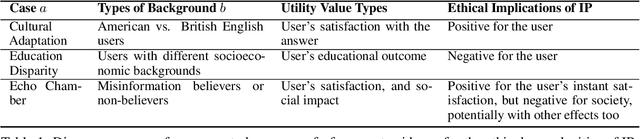
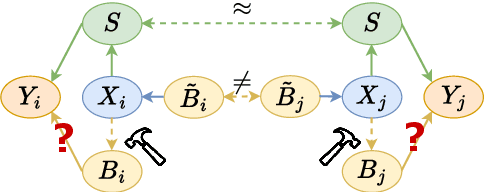

Implicit Personalization (IP) is a phenomenon of language models inferring a user's background from the implicit cues in the input prompts and tailoring the response based on this inference. While previous work has touched upon various instances of this problem, there lacks a unified framework to study this behavior. This work systematically studies IP through a rigorous mathematical formulation, a multi-perspective moral reasoning framework, and a set of case studies. Our theoretical foundation for IP relies on a structural causal model and introduces a novel method, indirect intervention, to estimate the causal effect of a mediator variable that cannot be directly intervened upon. Beyond the technical approach, we also introduce a set of moral reasoning principles based on three schools of moral philosophy to study when IP may or may not be ethically appropriate. Equipped with both mathematical and ethical insights, we present three diverse case studies illustrating the varied nature of the IP problem and offer recommendations for future research. Our code and data are at https://github.com/jiarui-liu/IP.
A Diachronic Perspective on User Trust in AI under Uncertainty
Oct 20, 2023



In a human-AI collaboration, users build a mental model of the AI system based on its reliability and how it presents its decision, e.g. its presentation of system confidence and an explanation of the output. Modern NLP systems are often uncalibrated, resulting in confidently incorrect predictions that undermine user trust. In order to build trustworthy AI, we must understand how user trust is developed and how it can be regained after potential trust-eroding events. We study the evolution of user trust in response to these trust-eroding events using a betting game. We find that even a few incorrect instances with inaccurate confidence estimates damage user trust and performance, with very slow recovery. We also show that this degradation in trust reduces the success of human-AI collaboration and that different types of miscalibration -- unconfidently correct and confidently incorrect -- have different negative effects on user trust. Our findings highlight the importance of calibration in user-facing AI applications and shed light on what aspects help users decide whether to trust the AI system.
Chain-of-Verification Reduces Hallucination in Large Language Models
Sep 25, 2023



Generation of plausible yet incorrect factual information, termed hallucination, is an unsolved issue in large language models. We study the ability of language models to deliberate on the responses they give in order to correct their mistakes. We develop the Chain-of-Verification (CoVe) method whereby the model first (i) drafts an initial response; then (ii) plans verification questions to fact-check its draft; (iii) answers those questions independently so the answers are not biased by other responses; and (iv) generates its final verified response. In experiments, we show CoVe decreases hallucinations across a variety of tasks, from list-based questions from Wikidata, closed book MultiSpanQA and longform text generation.
Variational Classification
May 17, 2023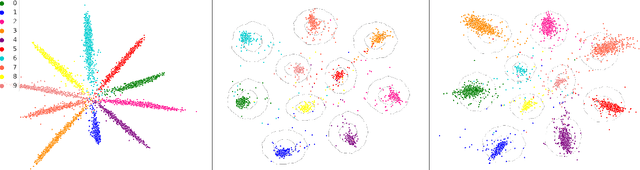

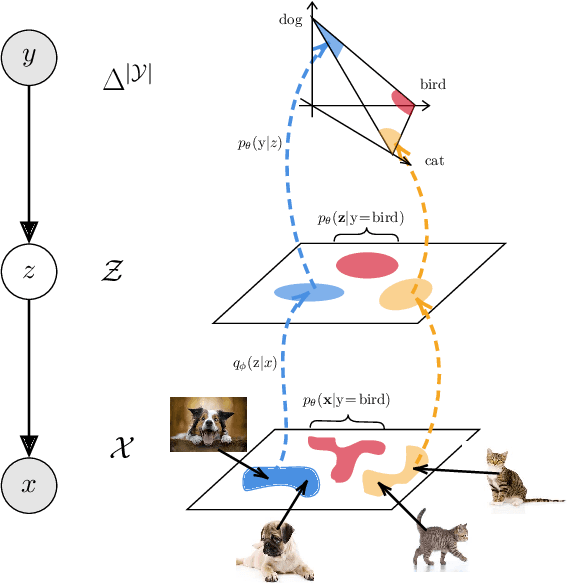

We present a novel extension of the traditional neural network approach to classification tasks, referred to as variational classification (VC). By incorporating latent variable modeling, akin to the relationship between variational autoencoders and traditional autoencoders, we derive a training objective based on the evidence lower bound (ELBO), optimized using an adversarial approach. Our VC model allows for more flexibility in design choices, in particular class-conditional latent priors, in place of the implicit assumptions made in off-the-shelf softmax classifiers. Empirical evaluation on image and text classification datasets demonstrates the effectiveness of our approach in terms of maintaining prediction accuracy while improving other desirable properties such as calibration and adversarial robustness, even when applied to out-of-domain data.
Extracting Victim Counts from Text
Feb 23, 2023


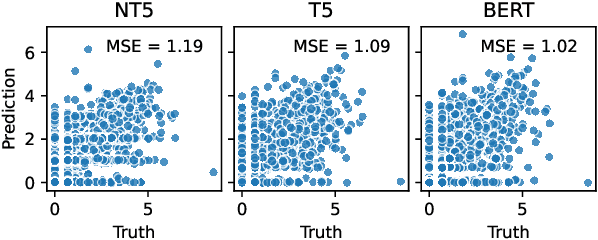
Decision-makers in the humanitarian sector rely on timely and exact information during crisis events. Knowing how many civilians were injured during an earthquake is vital to allocate aids properly. Information about such victim counts is often only available within full-text event descriptions from newspapers and other reports. Extracting numbers from text is challenging: numbers have different formats and may require numeric reasoning. This renders purely string matching-based approaches insufficient. As a consequence, fine-grained counts of injured, displaced, or abused victims beyond fatalities are often not extracted and remain unseen. We cast victim count extraction as a question answering (QA) task with a regression or classification objective. We compare regex, dependency parsing, semantic role labeling-based approaches, and advanced text-to-text models. Beyond model accuracy, we analyze extraction reliability and robustness which are key for this sensitive task. In particular, we discuss model calibration and investigate few-shot and out-of-distribution performance. Ultimately, we make a comprehensive recommendation on which model to select for different desiderata and data domains. Our work is among the first to apply numeracy-focused large language models in a real-world use case with a positive impact.