 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving LoRA with Variational Learning
Jun 17, 2025Bayesian methods have recently been used to improve LoRA finetuning and, although they improve calibration, their effect on other metrics (such as accuracy) is marginal and can sometimes even be detrimental. Moreover, Bayesian methods also increase computational overheads and require additional tricks for them to work well. Here, we fix these issues by using a recently proposed variational algorithm called IVON. We show that IVON is easy to implement and has similar costs to AdamW, and yet it can also drastically improve many metrics by using a simple posterior pruning technique. We present extensive results on billion-scale LLMs (Llama and Qwen series) going way beyond the scale of existing applications of IVON. For example, we finetune a Llama-3.2-3B model on a set of commonsense reasoning tasks and improve accuracy over AdamW by 1.3% and reduce ECE by 5.4%, outperforming AdamW and other recent Bayesian methods like Laplace-LoRA and BLoB. Overall, our results show that variational learning with IVON can effectively improve LoRA finetuning.
From Problem-Solving to Teaching Problem-Solving: Aligning LLMs with Pedagogy using Reinforcement Learning
May 21, 2025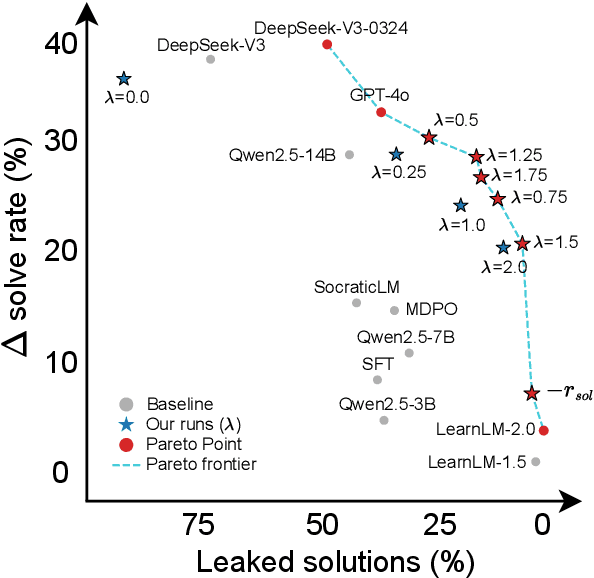
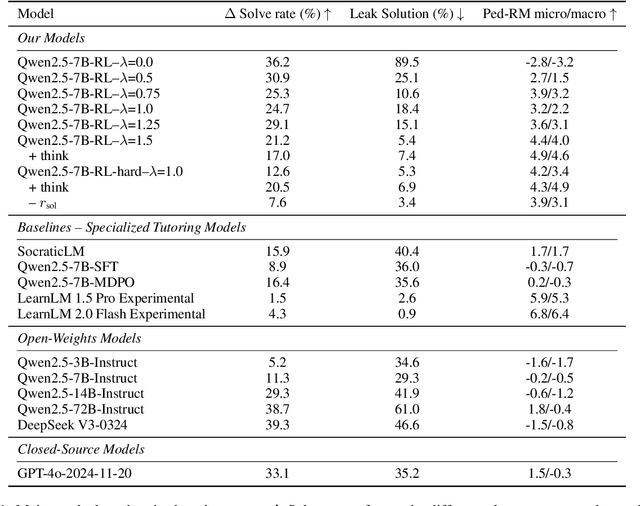
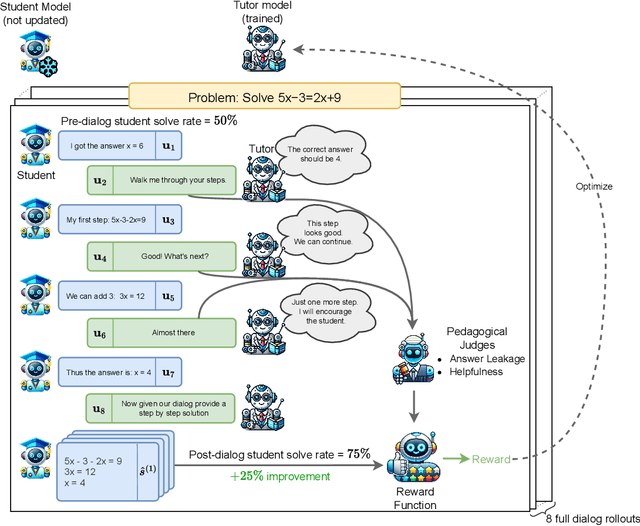
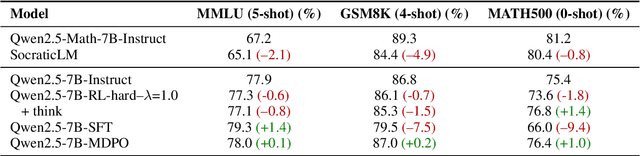
Large language models (LLMs) can transform education, but their optimization for direct question-answering often undermines effective pedagogy which requires strategically withholding answers. To mitigate this, we propose an online reinforcement learning (RL)-based alignment framework that can quickly adapt LLMs into effective tutors using simulated student-tutor interactions by emphasizing pedagogical quality and guided problem-solving over simply giving away answers. We use our method to train a 7B parameter tutor model without human annotations which reaches similar performance to larger proprietary models like LearnLM. We introduce a controllable reward weighting to balance pedagogical support and student solving accuracy, allowing us to trace the Pareto frontier between these two objectives. Our models better preserve reasoning capabilities than single-turn SFT baselines and can optionally enhance interpretability through thinking tags that expose the model's instructional planning.
A Head to Predict and a Head to Question: Pre-trained Uncertainty Quantification Heads for Hallucination Detection in LLM Outputs
May 13, 2025Large Language Models (LLMs) have the tendency to hallucinate, i.e., to sporadically generate false or fabricated information. This presents a major challenge, as hallucinations often appear highly convincing and users generally lack the tools to detect them. Uncertainty quantification (UQ) provides a framework for assessing the reliability of model outputs, aiding in the identification of potential hallucinations. In this work, we introduce pre-trained UQ heads: supervised auxiliary modules for LLMs that substantially enhance their ability to capture uncertainty compared to unsupervised UQ methods. Their strong performance stems from the powerful Transformer architecture in their design and informative features derived from LLM attention maps. Experimental evaluation shows that these heads are highly robust and achieve state-of-the-art performance in claim-level hallucination detection across both in-domain and out-of-domain prompts. Moreover, these modules demonstrate strong generalization to languages they were not explicitly trained on. We pre-train a collection of UQ heads for popular LLM series, including Mistral, Llama, and Gemma 2. We publicly release both the code and the pre-trained heads.
Token Weighting for Long-Range Language Modeling
Mar 12, 2025



Many applications of large language models (LLMs) require long-context understanding, but models continue to struggle with such tasks. We hypothesize that conventional next-token prediction training could contribute to this, because each token is assigned equal weight. Yet, intuitively, the amount of context needed to predict the next token accurately varies greatly across different data. To reflect this, we propose various novel token-weighting schemes that assign different weights to each training token in the loss, thereby generalizing existing works. For this, we categorize token-weighting methods using a two-step framework which compares the confidences of a long-context and short-context model to score tokens. We evaluate all methods on multiple long-context understanding tasks and show that non-uniform loss weights are helpful to improve the long-context abilities of LLMs. Different short-context models can be used effectively for token scoring, including models that are much smaller than the long-context model that is trained. All in all, this work contributes to a better understanding of the trade-offs long-context language modeling faces and provides guidelines for model steering via loss-weighting based on empirical evidence. The code can be found on Github.
Uncertainty-Aware Decoding with Minimum Bayes Risk
Mar 07, 2025Despite their outstanding performance in the majority of scenarios, contemporary language models still occasionally generate undesirable outputs, for example, hallucinated text. While such behaviors have previously been linked to uncertainty, there is a notable lack of methods that actively consider uncertainty during text generation. In this work, we show how Minimum Bayes Risk (MBR) decoding, which selects model generations according to an expected risk, can be generalized into a principled uncertainty-aware decoding method. In short, we account for model uncertainty during decoding by incorporating a posterior over model parameters into MBR's computation of expected risk. We show that this modified expected risk is useful for both choosing outputs and deciding when to abstain from generation and can provide improvements without incurring overhead. We benchmark different methods for learning posteriors and show that performance improves with prediction diversity. We release our code publicly.
MathTutorBench: A Benchmark for Measuring Open-ended Pedagogical Capabilities of LLM Tutors
Feb 26, 2025Evaluating the pedagogical capabilities of AI-based tutoring models is critical for making guided progress in the field. Yet, we lack a reliable, easy-to-use, and simple-to-run evaluation that reflects the pedagogical abilities of models. To fill this gap, we present MathTutorBench, an open-source benchmark for holistic tutoring model evaluation. MathTutorBench contains a collection of datasets and metrics that broadly cover tutor abilities as defined by learning sciences research in dialog-based teaching. To score the pedagogical quality of open-ended teacher responses, we train a reward model and show it can discriminate expert from novice teacher responses with high accuracy. We evaluate a wide set of closed- and open-weight models on MathTutorBench and find that subject expertise, indicated by solving ability, does not immediately translate to good teaching. Rather, pedagogy and subject expertise appear to form a trade-off that is navigated by the degree of tutoring specialization of the model. Furthermore, tutoring appears to become more challenging in longer dialogs, where simpler questioning strategies begin to fail. We release the benchmark, code, and leaderboard openly to enable rapid benchmarking of future models.
How to Weight Multitask Finetuning? Fast Previews via Bayesian Model-Merging
Dec 11, 2024



When finetuning multiple tasks altogether, it is important to carefully weigh them to get a good performance, but searching for good weights can be difficult and costly. Here, we propose to aid the search with fast previews to quickly get a rough idea of different reweighting options. We use model merging to create previews by simply reusing and averaging parameters of models trained on each task separately (no retraining required). To improve the quality of previews, we propose a Bayesian approach to design new merging strategies by using more flexible posteriors. We validate our findings on vision and natural-language transformers. Our work shows the benefits of model merging via Bayes to improve multitask finetuning.
Variational Low-Rank Adaptation Using IVON
Nov 07, 2024



We show that variational learning can significantly improve the accuracy and calibration of Low-Rank Adaptation (LoRA) without a substantial increase in the cost. We replace AdamW by the Improved Variational Online Newton (IVON) algorithm to finetune large language models. For Llama-2 with 7 billion parameters, IVON improves the accuracy over AdamW by 2.8% and expected calibration error by 4.6%. The accuracy is also better than the other Bayesian alternatives, yet the cost is lower and the implementation is easier. Our work provides additional evidence for the effectiveness of IVON for large language models. The code is available at https://github.com/team-approx-bayes/ivon-lora.
Stepwise Verification and Remediation of Student Reasoning Errors with Large Language Model Tutors
Jul 12, 2024



Large language models (LLMs) present an opportunity to scale high-quality personalized education to all. A promising approach towards this means is to build dialog tutoring models that scaffold students' problem-solving. However, even though existing LLMs perform well in solving reasoning questions, they struggle to precisely detect student's errors and tailor their feedback to these errors. Inspired by real-world teaching practice where teachers identify student errors and customize their response based on them, we focus on verifying student solutions and show how grounding to such verification improves the overall quality of tutor response generation. We collect a dataset of 1K stepwise math reasoning chains with the first error step annotated by teachers. We show empirically that finding the mistake in a student solution is challenging for current models. We propose and evaluate several verifiers for detecting these errors. Using both automatic and human evaluation we show that the student solution verifiers steer the generation model towards highly targeted responses to student errors which are more often correct with less hallucinations compared to existing baselines.
Book2Dial: Generating Teacher-Student Interactions from Textbooks for Cost-Effective Development of Educational Chatbots
Mar 05, 2024



Educational chatbots are a promising tool for assisting student learning. However, the development of effective chatbots in education has been challenging, as high-quality data is seldom available in this domain. In this paper, we propose a framework for generating synthetic teacher-student interactions grounded in a set of textbooks. Our approaches capture one aspect of learning interactions where curious students with partial knowledge interactively ask a teacher questions about the material in the textbook. We highlight various quality criteria that such dialogues should fulfill and compare several approaches relying on either prompting or fine-tuning large language models. We use synthetic dialogues to train educational chatbots and show benefits of further fine-tuning in different educational domains. However, human evaluation shows that our best data synthesis method still suffers from hallucinations and tends to reiterate information from previous conversations. Our findings offer insights for future efforts in synthesizing conversational data that strikes a balance between size and quality. We will open-source our data and code.