 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaperMentor: A Human-Centered Multi-Agent Writing Tutor for AI Research Papers on Overleaf
Jun 07, 2026Expert writing feedback from experienced researchers is critical for early-career scholars to improve their manuscripts, yet high-quality feedback often remains scarce because reviewing research papers is labor-intensive. Emerging AI-powered writing assistants largely focus on grammar fixes or simulating peer review with final scores, yet they fall short of providing concrete, actionable suggestions that help students improve their papers during drafting. We present PaperMentor, a human-centered writing assistant system that delivers actionable suggestions as Overleaf-native inline comments while leaving the actual writing entirely to human authors. PaperMentor integrates an expert skill library carefully curated from established researchers' writing advice with 12 specialized agents covering different aspects of paper writing, such as formatting compliance, phrasing accuracy, and terminology consistency. In a user study (n=14), 90.6% of the generated comments were rated actionable and 67.5% were rated valid, significantly outperforming a GPT-5.2 baseline uswithout the skill library. We release PaperMentor as open source for public use. Our code is publicly available under the AGPL-3.0 license at https://github.com/jiarui-liu/overleaf
Tackling the Root of Misinformation by Teaching Laypeople about Logical Fallacies via Socratic Questioning and Critical Argumentation
May 31, 2026Identifying logical fallacies in everyday discourse is challenging for many people. This challenge is amplified in the era of Large Language Models (LLMs), where malicious agents can deploy fallacious arguments to disseminate misinformation at scale. In this work, we explore the potential of LLMs as part of the solution. We introduce LFTutor, an intelligent tutoring system which uses LLMs to tutor laypeople and help them learn about logical fallacies. LFTutor integrates intent-driven Socratic questioning and critical argumentation principles to actively engage learners to reflect on their reasoning. Through both automatic and human evaluations, we demonstrate that LFTutor significantly outperforms baseline LLMs lacking these pedagogical strategies. This work highlights the promise of combining LLMs with pedagogical scaffolding to foster critical thinking and argument literacy in the age of AI.
* This paper has been accepted to Proceedings of the 64th Annual Meeting of the Association for Computational Linguistics (Long Paper), Main Conference
PATS: Personality-Aware Teaching Strategies with Large Language Model Tutors
Jan 13, 2026Recent advances in large language models (LLMs) demonstrate their potential as educational tutors. However, different tutoring strategies benefit different student personalities, and mismatches can be counterproductive to student outcomes. Despite this, current LLM tutoring systems do not take into account student personality traits. To address this problem, we first construct a taxonomy that links pedagogical methods to personality profiles, based on pedagogical literature. We simulate student-teacher conversations and use our framework to let the LLM tutor adjust its strategy to the simulated student personality. We evaluate the scenario with human teachers and find that they consistently prefer our approach over two baselines. Our method also increases the use of less common, high-impact strategies such as role-playing, which human and LLM annotators prefer significantly. Our findings pave the way for developing more personalized and effective LLM use in educational applications.
Multilingual Performance Biases of Large Language Models in Education
Apr 24, 2025Large language models (LLMs) are increasingly being adopted in educational settings. These applications expand beyond English, though current LLMs remain primarily English-centric. In this work, we ascertain if their use in education settings in non-English languages is warranted. We evaluated the performance of popular LLMs on four educational tasks: identifying student misconceptions, providing targeted feedback, interactive tutoring, and grading translations in six languages (Hindi, Arabic, Farsi, Telugu, Ukrainian, Czech) in addition to English. We find that the performance on these tasks somewhat corresponds to the amount of language represented in training data, with lower-resource languages having poorer task performance. Although the models perform reasonably well in most languages, the frequent performance drop from English is significant. Thus, we recommend that practitioners first verify that the LLM works well in the target language for their educational task before deployment.
Book2Dial: Generating Teacher-Student Interactions from Textbooks for Cost-Effective Development of Educational Chatbots
Mar 05, 2024



Educational chatbots are a promising tool for assisting student learning. However, the development of effective chatbots in education has been challenging, as high-quality data is seldom available in this domain. In this paper, we propose a framework for generating synthetic teacher-student interactions grounded in a set of textbooks. Our approaches capture one aspect of learning interactions where curious students with partial knowledge interactively ask a teacher questions about the material in the textbook. We highlight various quality criteria that such dialogues should fulfill and compare several approaches relying on either prompting or fine-tuning large language models. We use synthetic dialogues to train educational chatbots and show benefits of further fine-tuning in different educational domains. However, human evaluation shows that our best data synthesis method still suffers from hallucinations and tends to reiterate information from previous conversations. Our findings offer insights for future efforts in synthesizing conversational data that strikes a balance between size and quality. We will open-source our data and code.
Scaling the Authoring of AutoTutors with Large Language Models
Feb 27, 2024



Large Language Models (LLMs) have found several use cases in education, ranging from automatic question generation to essay evaluation. In this paper, we explore the potential of using Large Language Models (LLMs) to author Intelligent Tutoring Systems. A common pitfall of LLMs is their straying from desired pedagogical strategies such as leaking the answer to the student, and in general, providing no guarantees. We posit that while LLMs with certain guardrails can take the place of subject experts, the overall pedagogical design still needs to be handcrafted for the best learning results. Based on this principle, we create a sample end-to-end tutoring system named MWPTutor, which uses LLMs to fill in the state space of a pre-defined finite state transducer. This approach retains the structure and the pedagogy of traditional tutoring systems that has been developed over the years by learning scientists but brings in additional flexibility of LLM-based approaches. Through a human evaluation study on two datasets based on math word problems, we show that our hybrid approach achieves a better overall tutoring score than an instructed, but otherwise free-form, GPT-4. MWPTutor is completely modular and opens up the scope for the community to improve its performance by improving individual modules or using different teaching strategies that it can follow
MathDial: A Dialogue Tutoring Dataset with Rich Pedagogical Properties Grounded in Math Reasoning Problems
May 23, 2023

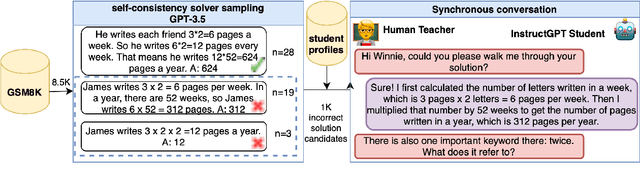

Although automatic dialogue tutors hold great potential in making education personalized and more accessible, research on such systems has been hampered by a lack of sufficiently large and high-quality datasets. However, collecting such datasets remains challenging, as recording tutoring sessions raises privacy concerns and crowdsourcing leads to insufficient data quality. To address this problem, we propose a framework to semi-synthetically generate such dialogues by pairing real teachers with a large language model (LLM) scaffolded to represent common student errors. In this paper, we describe our ongoing efforts to use this framework to collect MathDial, a dataset of currently ca. 1.5k tutoring dialogues grounded in multi-step math word problems. We show that our dataset exhibits rich pedagogical properties, focusing on guiding students using sense-making questions to let them explore problems. Moreover, we outline that MathDial and its grounding annotations can be used to finetune language models to be more effective tutors (and not just solvers) and highlight remaining challenges that need to be addressed by the research community. We will release our dataset publicly to foster research in this socially important area of NLP.
On Learning the Transformer Kernel
Oct 15, 2021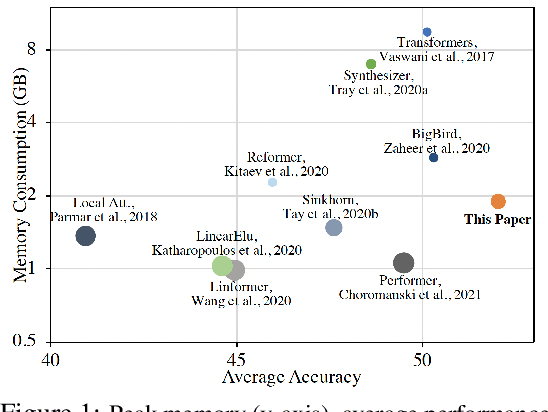

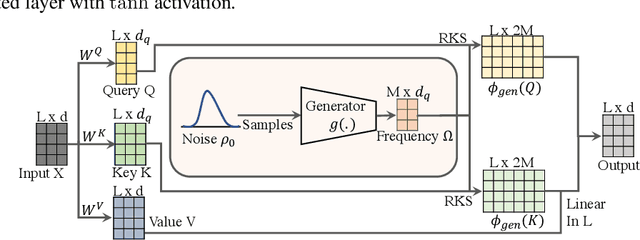
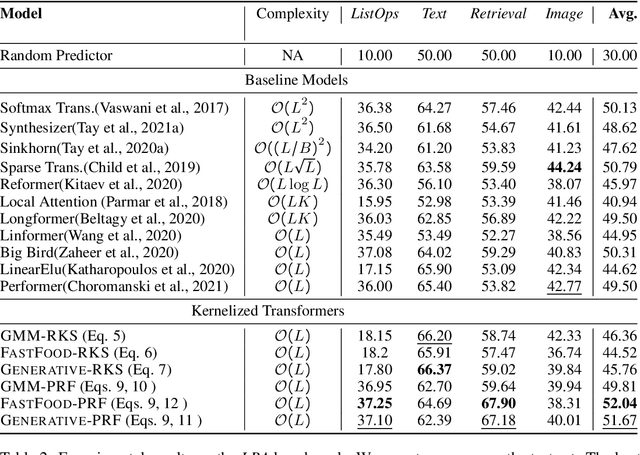
In this work we introduce KERNELIZED TRANSFORMER, a generic, scalable, data driven framework for learning the kernel function in Transformers. Our framework approximates the Transformer kernel as a dot product between spectral feature maps and learns the kernel by learning the spectral distribution. This not only helps in learning a generic kernel end-to-end, but also reduces the time and space complexity of Transformers from quadratic to linear. We show that KERNELIZED TRANSFORMERS achieve performance comparable to existing efficient Transformer architectures, both in terms of accuracy as well as computational efficiency. Our study also demonstrates that the choice of the kernel has a substantial impact on performance, and kernel learning variants are competitive alternatives to fixed kernel Transformers, both in long as well as short sequence tasks.
Towards Latent Space Optimality for Auto-Encoder Based Generative Models
Dec 10, 2019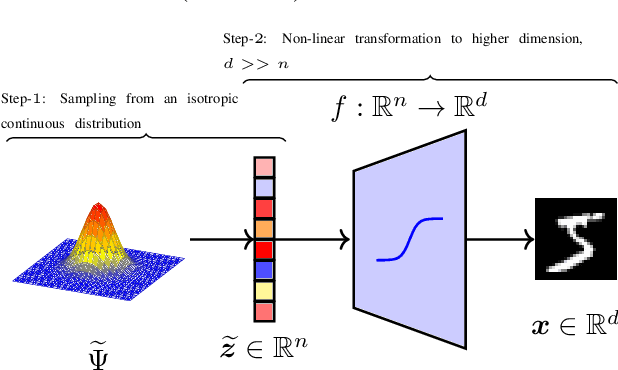
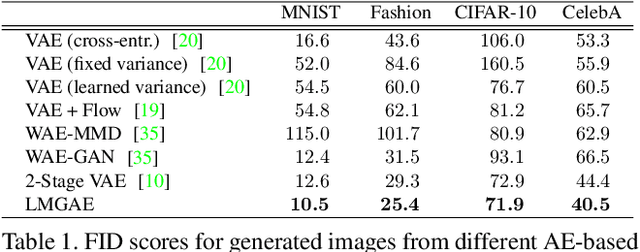
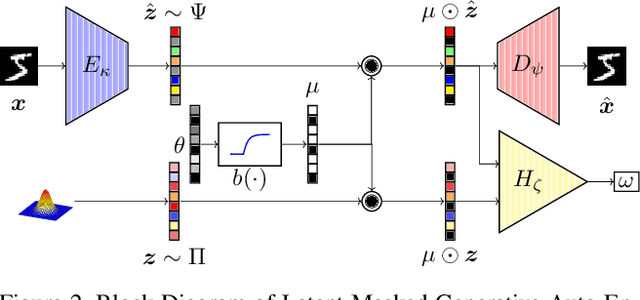
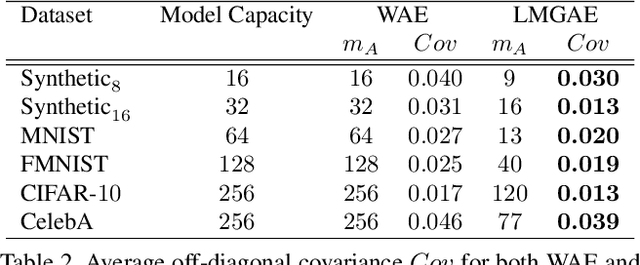
The field of neural generative models is dominated by the highly successful Generative Adversarial Networks (GANs) despite their challenges, such as training instability and mode collapse. Auto-Encoders (AE) with regularized latent space provides an alternative framework for generative models, albeit their performance levels have not reached that of GANs. In this work, we identify one of the causes for the under-performance of AE-based models and propose a remedial measure. Specifically, we hypothesize that the dimensionality of the AE model's latent space has a critical effect on the quality of the generated data. Under the assumption that nature generates data by sampling from a "true" generative latent space followed by a deterministic non-linearity, we show that the optimal performance is obtained when the dimensionality of the latent space of the AE-model matches with that of the "true" generative latent space. Further, we propose an algorithm called the Latent Masked Generative Auto-Encoder (LMGAE), in which the dimensionality of the model's latent space is brought closer to that of the "true" generative latent space, via a novel procedure to mask the spurious latent dimensions. We demonstrate through experiments on synthetic and several real-world datasets that the proposed formulation yields generation quality that is better than the state-of-the-art AE-based generative models and is comparable to that of GANs.
DeepSearch: Simple and Effective Blackbox Fuzzing of Deep Neural Networks
Oct 14, 2019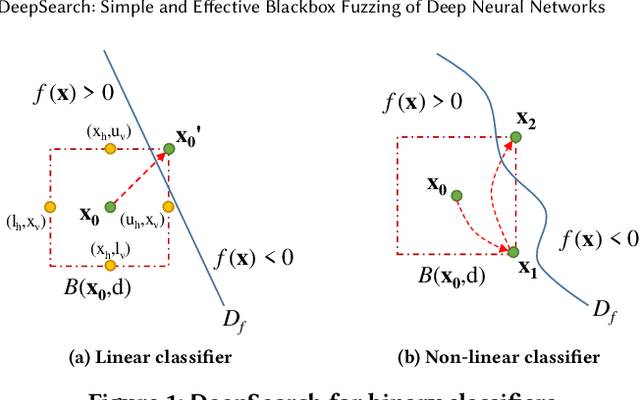
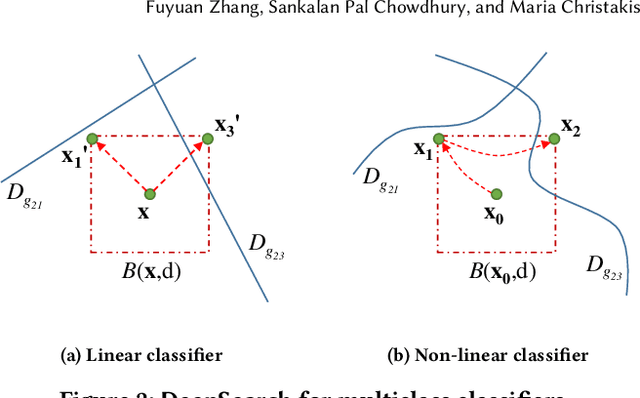
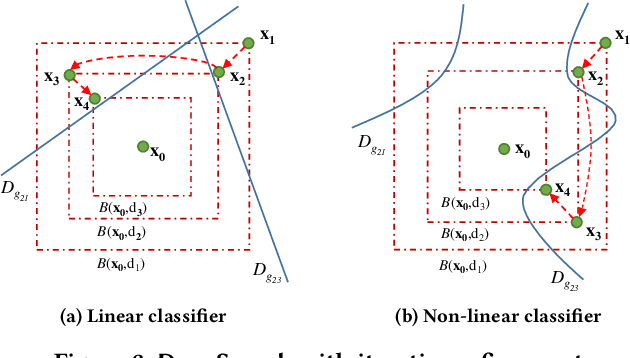
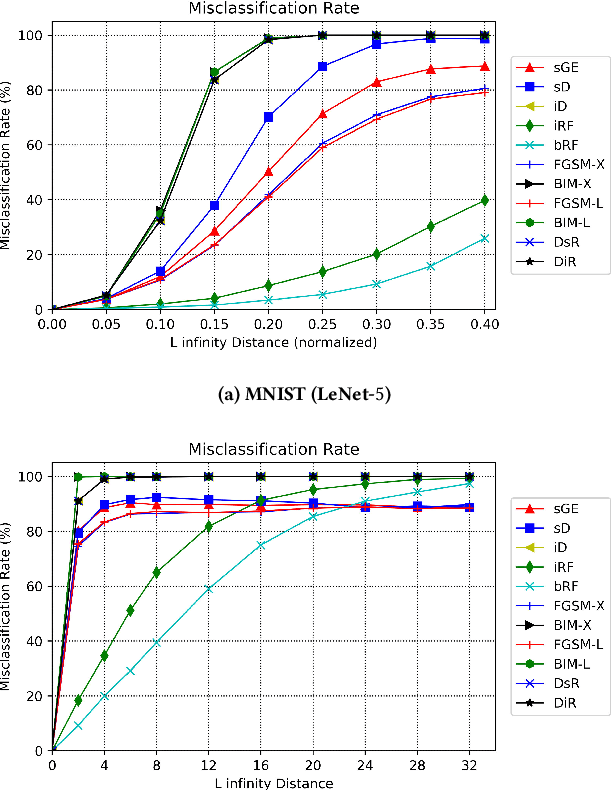
Although deep neural networks have been successful in image classification, they are prone to adversarial attacks. To generate misclassified inputs, there has emerged a wide variety of techniques, such as black- and whitebox testing of neural networks. In this paper, we present DeepSearch, a novel blackbox-fuzzing technique for image classifiers. Despite its simplicity, DeepSearch is shown to be more effective in finding adversarial examples than closely related black- and whitebox approaches. DeepSearch is additionally able to generate the most subtle adversarial examples in comparison to these approaches.