 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatically Testing Functional Properties of Code Translation Models
Sep 07, 2023Large language models are becoming increasingly practical for translating code across programming languages, a process known as $transpiling$. Even though automated transpilation significantly boosts developer productivity, a key concern is whether the generated code is correct. Existing work initially used manually crafted test suites to test the translations of a small corpus of programs; these test suites were later automated. In contrast, we devise the first approach for automated, functional, property-based testing of code translation models. Our general, user-provided specifications about the transpiled code capture a range of properties, from purely syntactic to purely semantic ones. As shown by our experiments, this approach is very effective in detecting property violations in popular code translation models, and therefore, in evaluating model quality with respect to given properties. We also go a step further and explore the usage scenario where a user simply aims to obtain a correct translation of some code with respect to certain properties without necessarily being concerned about the overall quality of the model. To this purpose, we develop the first property-guided search procedure for code translation models, where a model is repeatedly queried with slightly different parameters to produce alternative and potentially more correct translations. Our results show that this search procedure helps to obtain significantly better code translations.
Synthesizing a Progression of Subtasks for Block-Based Visual Programming Tasks
May 27, 2023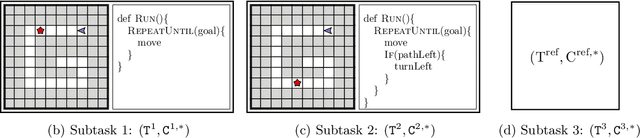
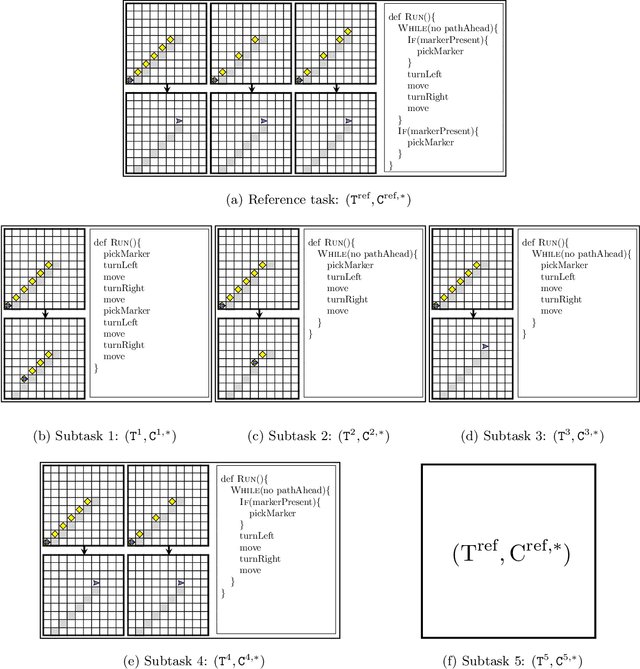
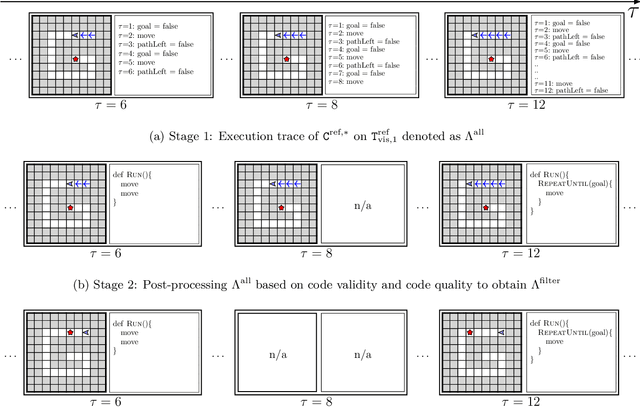
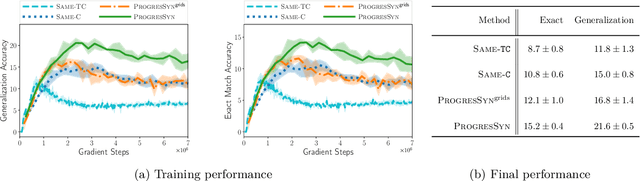
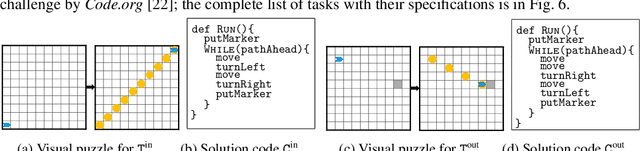
Block-based visual programming environments play an increasingly important role in introducing computing concepts to K-12 students. In recent years, they have also gained popularity in neuro-symbolic AI, serving as a benchmark to evaluate general problem-solving and logical reasoning skills. The open-ended and conceptual nature of these visual programming tasks make them challenging, both for state-of-the-art AI agents as well as for novice programmers. A natural approach to providing assistance for problem-solving is breaking down a complex task into a progression of simpler subtasks; however, this is not trivial given that the solution codes are typically nested and have non-linear execution behavior. In this paper, we formalize the problem of synthesizing such a progression for a given reference block-based visual programming task. We propose a novel synthesis algorithm that generates a progression of subtasks that are high-quality, well-spaced in terms of their complexity, and solving this progression leads to solving the reference task. We show the utility of our synthesis algorithm in improving the efficacy of AI agents (in this case, neural program synthesizers) for solving tasks in the Karel programming environment. Then, we conduct a user study to demonstrate that our synthesized progression of subtasks can assist a novice programmer in solving tasks in the Hour of Code: Maze Challenge by Code-dot-org.
Specifying and Testing $k$-Safety Properties for Machine-Learning Models
Jun 13, 2022
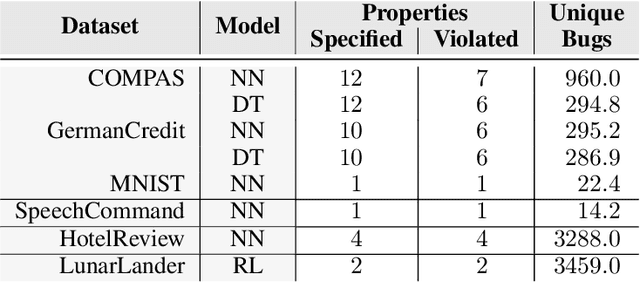

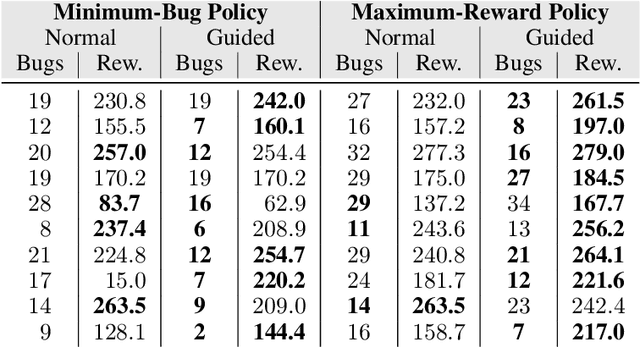
Machine-learning models are becoming increasingly prevalent in our lives, for instance assisting in image-classification or decision-making tasks. Consequently, the reliability of these models is of critical importance and has resulted in the development of numerous approaches for validating and verifying their robustness and fairness. However, beyond such specific properties, it is challenging to specify, let alone check, general functional-correctness expectations from models. In this paper, we take inspiration from specifications used in formal methods, expressing functional-correctness properties by reasoning about $k$ different executions, so-called $k$-safety properties. Considering a credit-screening model of a bank, the expected property that "if a person is denied a loan and their income decreases, they should still be denied the loan" is a 2-safety property. Here, we show the wide applicability of $k$-safety properties for machine-learning models and present the first specification language for expressing them. We also operationalize the language in a framework for automatically validating such properties using metamorphic testing. Our experiments show that our framework is effective in identifying property violations, and that detected bugs could be used to train better models.
Synthesizing Tasks for Block-based Programming
Jul 01, 2020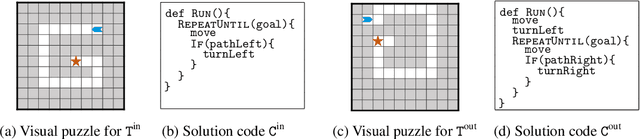
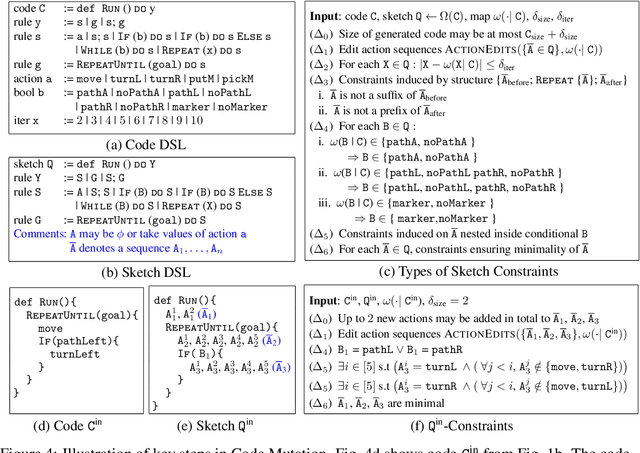

Block-based visual programming environments play a critical role in introducing computing concepts to K-12 students. One of the key pedagogical challenges in these environments is in designing new practice tasks for a student that match a desired level of difficulty and exercise specific programming concepts. In this paper, we formalize the problem of synthesizing visual programming tasks. In particular, given a reference visual task $\rm T^{in}$ and its solution code $\rm C^{in}$, we propose a novel methodology to automatically generate a set $\{(\rm T^{out}, \rm C^{out})\}$ of new tasks along with solution codes such that tasks $\rm T^{in}$ and $\rm T^{out}$ are conceptually similar but visually dissimilar. Our methodology is based on the realization that the mapping from the space of visual tasks to their solution codes is highly discontinuous; hence, directly mutating reference task $\rm T^{in}$ to generate new tasks is futile. Our task synthesis algorithm operates by first mutating code $\rm C^{in}$ to obtain a set of codes $\{\rm C^{out}\}$. Then, the algorithm performs symbolic execution over a code $\rm C^{out}$ to obtain a visual task $\rm T^{out}$; this step uses the Monte Carlo Tree Search (MCTS) procedure to guide the search in the symbolic tree. We demonstrate the effectiveness of our algorithm through an extensive empirical evaluation and user study on reference tasks taken from the \emph{Hour of the Code: Classic Maze} challenge by \emph{Code.org} and the \emph{Intro to Programming with Karel} course by \emph{CodeHS.com}.
RAID: Randomized Adversarial-Input Detection for Neural Networks
Feb 07, 2020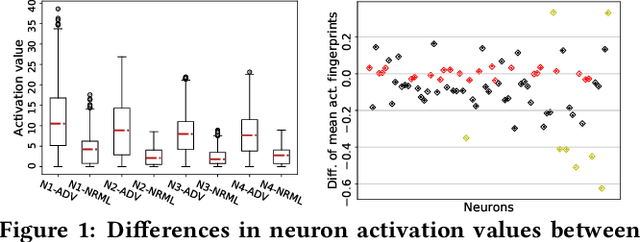
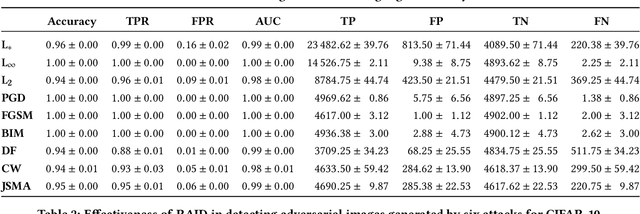
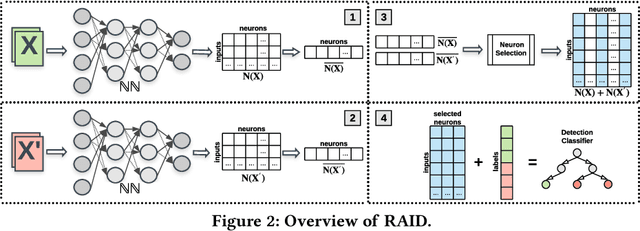
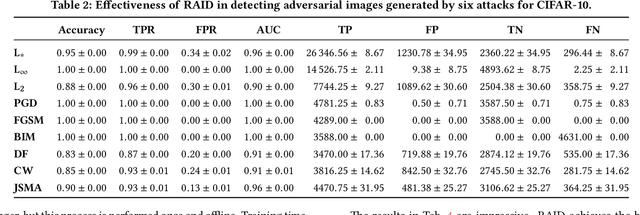
In recent years, neural networks have become the default choice for image classification and many other learning tasks, even though they are vulnerable to so-called adversarial attacks. To increase their robustness against these attacks, there have emerged numerous detection mechanisms that aim to automatically determine if an input is adversarial. However, state-of-the-art detection mechanisms either rely on being tuned for each type of attack, or they do not generalize across different attack types. To alleviate these issues, we propose a novel technique for adversarial-image detection, RAID, that trains a secondary classifier to identify differences in neuron activation values between benign and adversarial inputs. Our technique is both more reliable and more effective than the state of the art when evaluated against six popular attacks. Moreover, a straightforward extension of RAID increases its robustness against detection-aware adversaries without affecting its effectiveness.
DeepSearch: Simple and Effective Blackbox Fuzzing of Deep Neural Networks
Oct 14, 2019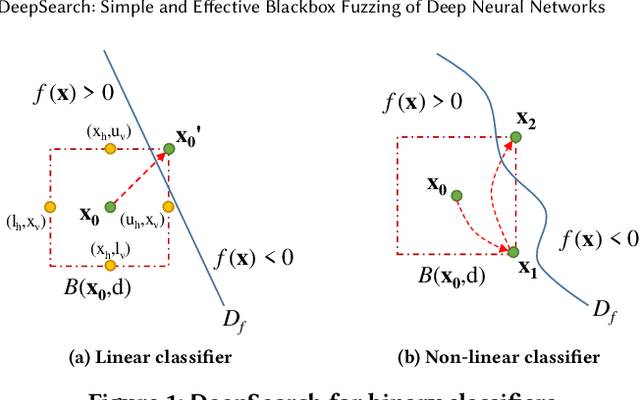
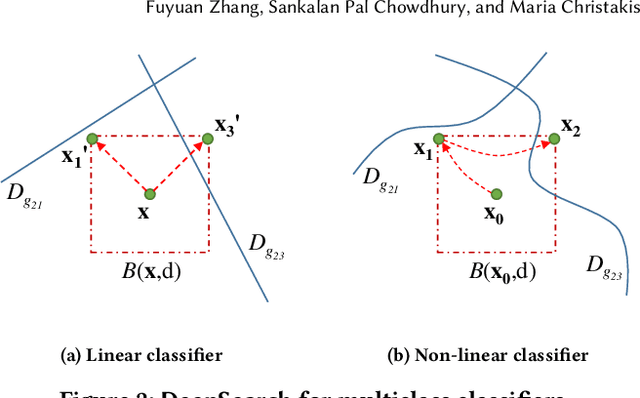
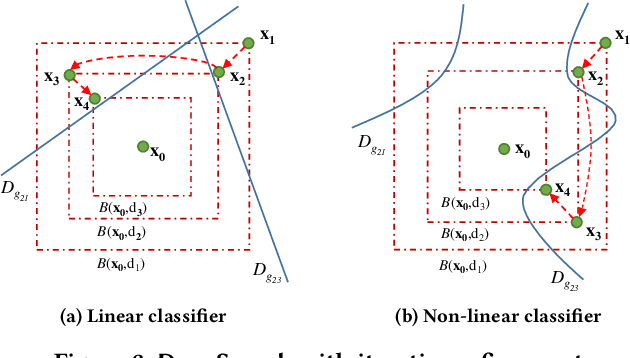
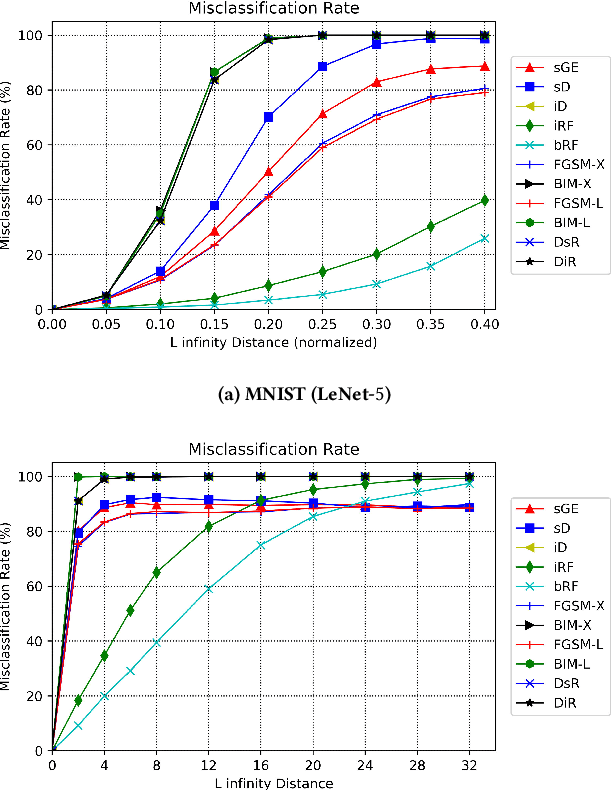
Although deep neural networks have been successful in image classification, they are prone to adversarial attacks. To generate misclassified inputs, there has emerged a wide variety of techniques, such as black- and whitebox testing of neural networks. In this paper, we present DeepSearch, a novel blackbox-fuzzing technique for image classifiers. Despite its simplicity, DeepSearch is shown to be more effective in finding adversarial examples than closely related black- and whitebox approaches. DeepSearch is additionally able to generate the most subtle adversarial examples in comparison to these approaches.