 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Reward Identification In Max Entropy Reinforcement Learning with Sparsity and Rank Priors
Aug 10, 2025In this paper, we consider the problem of recovering time-varying reward functions from either optimal policies or demonstrations coming from a max entropy reinforcement learning problem. This problem is highly ill-posed without additional assumptions on the underlying rewards. However, in many applications, the rewards are indeed parsimonious, and some prior information is available. We consider two such priors on the rewards: 1) rewards are mostly constant and they change infrequently, 2) rewards can be represented by a linear combination of a small number of feature functions. We first show that the reward identification problem with the former prior can be recast as a sparsification problem subject to linear constraints. Moreover, we give a polynomial-time algorithm that solves this sparsification problem exactly. Then, we show that identifying rewards representable with the minimum number of features can be recast as a rank minimization problem subject to linear constraints, for which convex relaxations of rank can be invoked. In both cases, these observations lead to efficient optimization-based reward identification algorithms. Several examples are given to demonstrate the accuracy of the recovered rewards as well as their generalizability.
Thresholded Lexicographic Ordered Multiobjective Reinforcement Learning
Aug 24, 2024



Lexicographic multi-objective problems, which impose a lexicographic importance order over the objectives, arise in many real-life scenarios. Existing Reinforcement Learning work directly addressing lexicographic tasks has been scarce. The few proposed approaches were all noted to be heuristics without theoretical guarantees as the Bellman equation is not applicable to them. Additionally, the practical applicability of these prior approaches also suffers from various issues such as not being able to reach the goal state. While some of these issues have been known before, in this work we investigate further shortcomings, and propose fixes for improving practical performance in many cases. We also present a policy optimization approach using our Lexicographic Projection Optimization (LPO) algorithm that has the potential to address these theoretical and practical concerns. Finally, we demonstrate our proposed algorithms on benchmark problems.
Synthesizing a Progression of Subtasks for Block-Based Visual Programming Tasks
May 27, 2023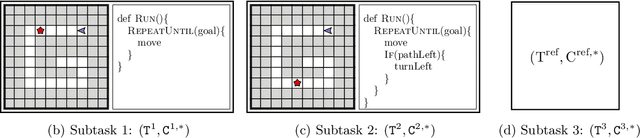
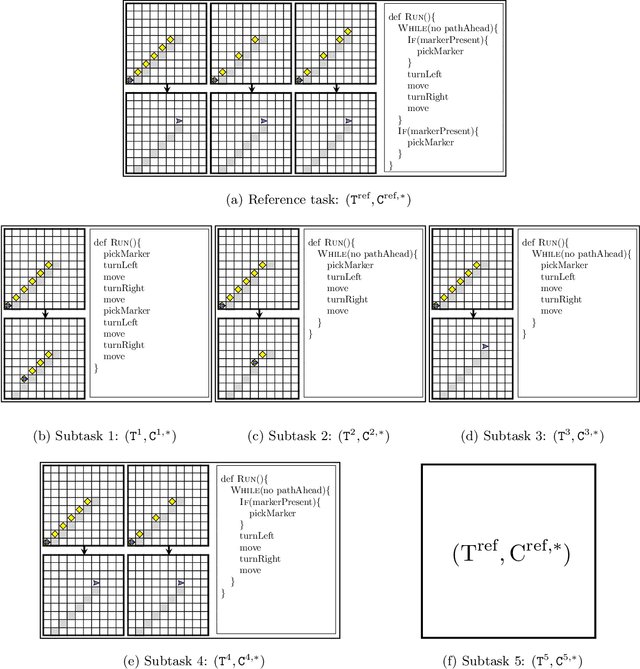
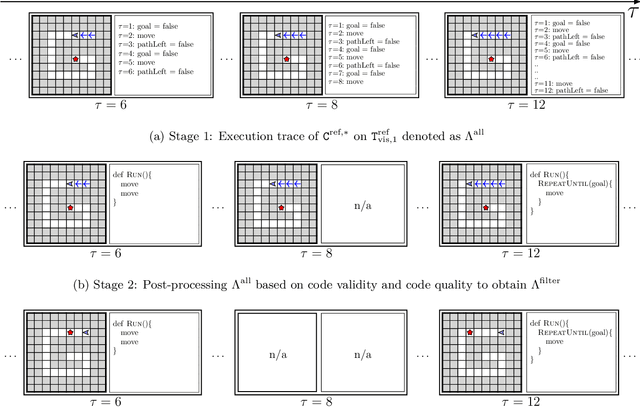
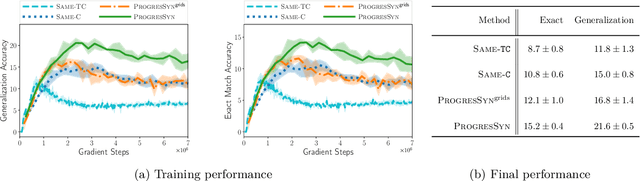
Block-based visual programming environments play an increasingly important role in introducing computing concepts to K-12 students. In recent years, they have also gained popularity in neuro-symbolic AI, serving as a benchmark to evaluate general problem-solving and logical reasoning skills. The open-ended and conceptual nature of these visual programming tasks make them challenging, both for state-of-the-art AI agents as well as for novice programmers. A natural approach to providing assistance for problem-solving is breaking down a complex task into a progression of simpler subtasks; however, this is not trivial given that the solution codes are typically nested and have non-linear execution behavior. In this paper, we formalize the problem of synthesizing such a progression for a given reference block-based visual programming task. We propose a novel synthesis algorithm that generates a progression of subtasks that are high-quality, well-spaced in terms of their complexity, and solving this progression leads to solving the reference task. We show the utility of our synthesis algorithm in improving the efficacy of AI agents (in this case, neural program synthesizers) for solving tasks in the Karel programming environment. Then, we conduct a user study to demonstrate that our synthesized progression of subtasks can assist a novice programmer in solving tasks in the Hour of Code: Maze Challenge by Code-dot-org.