 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurtleAI: Benchmarking Multimodal Models for Visual Programming in Turtle Graphics
Jun 02, 2026Vision-language models (VLMs) have been explored for visual programming, where they generate code to solve visual tasks. However, most prior work focuses on visual programming for productivity; it remains unclear how well current VLMs perform on education-oriented visual programming and what factors limit their performance. To bridge this gap, we introduce TurtleAI, a benchmark containing 823 tasks curated based on real-world visual programming tasks in the Turtle Graphics domain. Solving these tasks requires models to perceive geometric patterns, reason about spatial relationships, and synthesize Python code that faithfully reproduces geometric patterns. We evaluate 20+ VLMs, including GPT-5, GPT-4o, and Qwen2-VL-72B, and find that they struggle significantly, with most achieving success rates below 30%. To address these limitations, we propose a data generation technique that requires only a small set of seed samples. Fine-tuning Qwen2-VL-72B on the resulting synthetic data yields an improvement of about 20% on real-world tasks. Our failure analysis reveals that GPT-4o struggles with spatial reasoning and precise visual replication, whereas fine-tuning primarily improves the alignment between visual reasoning and code implementation.
Corruption-robust Offline Multi-agent Reinforcement Learning From Human Feedback
Mar 30, 2026We consider robustness against data corruption in offline multi-agent reinforcement learning from human feedback (MARLHF) under a strong-contamination model: given a dataset $D$ of trajectory-preference tuples (each preference being an $n$-dimensional binary label vector representing each of the $n$ agents' preferences), an $ε$-fraction of the samples may be arbitrarily corrupted. We model the problem using the framework of linear Markov games. First, under a uniform coverage assumption - where every policy of interest is sufficiently represented in the clean (prior to corruption) data - we introduce a robust estimator that guarantees an $O(ε^{1 - o(1)})$ bound on the Nash equilibrium gap. Next, we move to the more challenging unilateral coverage setting, in which only a Nash equilibrium and its single-player deviations are covered. In this case, our proposed algorithm achieves an $O(\sqrtε)$ bound on the Nash gap. Both of these procedures, however, suffer from intractable computation. To address this, we relax our solution concept to coarse correlated equilibria (CCE). Under the same unilateral coverage regime, we derive a quasi-polynomial-time algorithm whose CCE gap scales as $O(\sqrtε)$. To the best of our knowledge, this is the first systematic treatment of adversarial data corruption in offline MARLHF.
MaMa: A Game-Theoretic Approach for Designing Safe Agentic Systems
Feb 04, 2026LLM-based multi-agent systems have demonstrated impressive capabilities, but they also introduce significant safety risks when individual agents fail or behave adversarially. In this work, we study the automated design of agentic systems that remain safe even when a subset of agents is compromised. We formalize this challenge as a Stackelberg security game between a system designer (the Meta-Agent) and a best-responding Meta-Adversary that selects and compromises a subset of agents to minimize safety. We propose Meta-Adversary-Meta-Agent (MaMa), a novel algorithm for approximately solving this game and automatically designing safe agentic systems. Our approach uses LLM-based adversarial search, where the Meta-Agent iteratively proposes system designs and receives feedback based on the strongest attacks discovered by the Meta-Adversary. Empirical evaluations across diverse environments show that systems designed with MaMa consistently defend against worst-case attacks while maintaining performance comparable to systems optimized solely for task success. Moreover, the resulting systems generalize to stronger adversaries, as well as ones with different attack objectives or underlying LLMs, demonstrating robust safety beyond the training setting.
Learning Half-Spaces from Perturbed Contrastive Examples
Feb 02, 2026We study learning under a two-step contrastive example oracle, as introduced by Mansouri et. al. (2025), where each queried (or sampled) labeled example is paired with an additional contrastive example of opposite label. While Mansouri et al. assume an idealized setting, where the contrastive example is at minimum distance of the originally queried/sampled point, we introduce and analyze a mechanism, parameterized by a non-decreasing noise function $f$, under which this ideal contrastive example is perturbed. The amount of perturbation is controlled by $f(d)$, where $d$ is the distance of the queried/sampled point to the decision boundary. Intuitively, this results in higher-quality contrastive examples for points closer to the decision boundary. We study this model in two settings: (i) when the maximum perturbation magnitude is fixed, and (ii) when it is stochastic. For one-dimensional thresholds and for half-spaces under the uniform distribution on a bounded domain, we characterize active and passive contrastive sample complexity in dependence on the function $f$. We show that, under certain conditions on $f$, the presence of contrastive examples speeds up learning in terms of asymptotic query complexity and asymptotic expected query complexity.
Divergent-Convergent Thinking in Large Language Models for Creative Problem Generation
Dec 29, 2025Large language models (LLMs) have significant potential for generating educational questions and problems, enabling educators to create large-scale learning materials. However, LLMs are fundamentally limited by the ``Artificial Hivemind'' effect, where they generate similar responses within the same model and produce homogeneous outputs across different models. As a consequence, students may be exposed to overly similar and repetitive LLM-generated problems, which harms diversity of thought. Drawing inspiration from Wallas's theory of creativity and Guilford's framework of divergent-convergent thinking, we propose CreativeDC, a two-phase prompting method that explicitly scaffolds the LLM's reasoning into distinct phases. By decoupling creative exploration from constraint satisfaction, our method enables LLMs to explore a broader space of ideas before committing to a final problem. We evaluate CreativeDC for creative problem generation using a comprehensive set of metrics that capture diversity, novelty, and utility. The results show that CreativeDC achieves significantly higher diversity and novelty compared to baselines while maintaining high utility. Moreover, scaling analysis shows that CreativeDC generates a larger effective number of distinct problems as more are sampled, increasing at a faster rate than baseline methods.
Exploration vs. Fixation: Scaffolding Divergent and Convergent Thinking for Human-AI Co-Creation with Generative Models
Dec 20, 2025Generative AI has begun to democratize creative work, enabling novices to produce complex artifacts such as code, images, and videos. However, in practice, existing interaction paradigms often fail to support divergent exploration: users tend to converge too quickly on early ``good enough'' results and struggle to move beyond them, leading to premature convergence and design fixation that constrains their creative potential. To address this, we propose a structured, process-oriented human-AI co-creation paradigm including divergent and convergent thinking stages, grounded in Wallas's model of creativity. To avoid design fixation, our paradigm scaffolds both high-level exploration of conceptual ideas in the early divergent thinking phase and low-level exploration of variations in the later convergent thinking phrase. We instantiate this paradigm in HAIExplore, an image co-creation system that (i) scaffolds divergent thinking through a dedicated brainstorming stage for exploring high-level ideas in a conceptual space, and (ii) scaffolds convergent refinement through an interface that externalizes users' refinement intentions as interpretable parameters and options, making the refinement process more controllable and easier to explore. We report on a within-subjects study comparing HAIExplore with a widely used linear chat interface (ChatGPT) for creative image generation. Our findings show that explicitly scaffolding the creative process into brainstorming and refinement stages can mitigate design fixation, improve perceived controllability and alignment with users' intentions, and better support the non-linear nature of creative work. We conclude with design implications for future creativity support tools and human-AI co-creation workflows.
Prompt Optimization Across Multiple Agents for Representing Diverse Human Populations
Oct 08, 2025The difficulty and expense of obtaining large-scale human responses make Large Language Models (LLMs) an attractive alternative and a promising proxy for human behavior. However, prior work shows that LLMs often produce homogeneous outputs that fail to capture the rich diversity of human perspectives and behaviors. Thus, rather than trying to capture this diversity with a single LLM agent, we propose a novel framework to construct a set of agents that collectively capture the diversity of a given human population. Each agent is an LLM whose behavior is steered by conditioning on a small set of human demonstrations (task-response pairs) through in-context learning. The central challenge is therefore to select a representative set of LLM agents from the exponentially large space of possible agents. We tackle this selection problem from the lens of submodular optimization. In particular, we develop methods that offer different trade-offs regarding time complexity and performance guarantees. Extensive experiments in crowdsourcing and educational domains demonstrate that our approach constructs agents that more effectively represent human populations compared to baselines. Moreover, behavioral analyses on new tasks show that these agents reproduce the behavior patterns and perspectives of the students and annotators they are designed to represent.
ClickSight: Interpreting Student Clickstreams to Reveal Insights on Learning Strategies via LLMs
May 21, 2025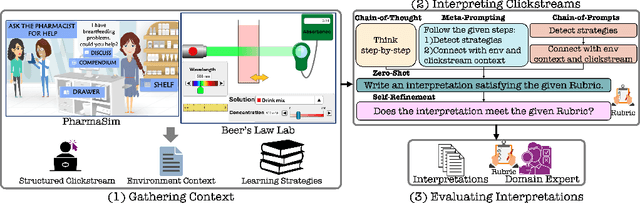

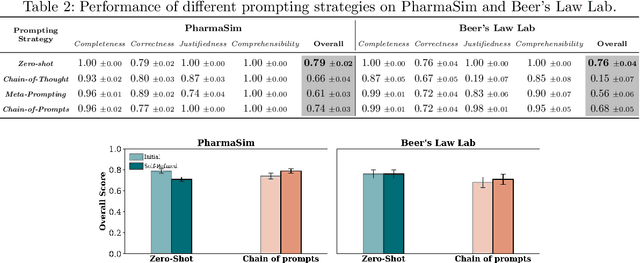
Clickstream data from digital learning environments offer valuable insights into students' learning behaviors, but are challenging to interpret due to their high dimensionality and granularity. Prior approaches have relied mainly on handcrafted features, expert labeling, clustering, or supervised models, therefore often lacking generalizability and scalability. In this work, we introduce ClickSight, an in-context Large Language Model (LLM)-based pipeline that interprets student clickstreams to reveal their learning strategies. ClickSight takes raw clickstreams and a list of learning strategies as input and generates textual interpretations of students' behaviors during interaction. We evaluate four different prompting strategies and investigate the impact of self-refinement on interpretation quality. Our evaluation spans two open-ended learning environments and uses a rubric-based domain-expert evaluation. Results show that while LLMs can reasonably interpret learning strategies from clickstreams, interpretation quality varies by prompting strategy, and self-refinement offers limited improvement. ClickSight demonstrates the potential of LLMs to generate theory-driven insights from educational interaction data.
Synthesizing High-Quality Programming Tasks with LLM-based Expert and Student Agents
Apr 10, 2025



Generative AI is transforming computing education by enabling the automatic generation of personalized content and feedback. We investigate its capabilities in providing high-quality programming tasks to students. Despite promising advancements in task generation, a quality gap remains between AI-generated and expert-created tasks. The AI-generated tasks may not align with target programming concepts, could be incomprehensible for students to solve, or may contain critical issues such as incorrect tests. Existing works often require interventions from human teachers for validation. We address these challenges by introducing PyTaskSyn, a novel synthesis technique that first generates a programming task and then decides whether it meets certain quality criteria to be given to students. The key idea is to break this process into multiple stages performed by expert and student agents simulated using both strong and weaker generative models. Through extensive evaluation, we show that PyTaskSyn significantly improves task quality compared to baseline techniques and showcases the importance of each specialized agent type in our validation pipeline. Additionally, we conducted user studies using our publicly available web application and show that PyTaskSyn can deliver high-quality programming tasks comparable to expert-designed ones while reducing workload and costs, and being more engaging than programming tasks that are available in online resources.
Policy Teaching via Data Poisoning in Learning from Human Preferences
Mar 13, 2025
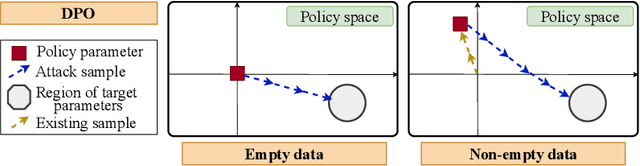
We study data poisoning attacks in learning from human preferences. More specifically, we consider the problem of teaching/enforcing a target policy $\pi^\dagger$ by synthesizing preference data. We seek to understand the susceptibility of different preference-based learning paradigms to poisoned preference data by analyzing the number of samples required by the attacker to enforce $\pi^\dagger$. We first propose a general data poisoning formulation in learning from human preferences and then study it for two popular paradigms, namely: (a) reinforcement learning from human feedback (RLHF) that operates by learning a reward model using preferences; (b) direct preference optimization (DPO) that directly optimizes policy using preferences. We conduct a theoretical analysis of the effectiveness of data poisoning in a setting where the attacker is allowed to augment a pre-existing dataset and also study its special case where the attacker can synthesize the entire preference dataset from scratch. As our main results, we provide lower/upper bounds on the number of samples required to enforce $\pi^\dagger$. Finally, we discuss the implications of our results in terms of the susceptibility of these learning paradigms under such data poisoning attacks.