 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurtleAI: Benchmarking Multimodal Models for Visual Programming in Turtle Graphics
Jun 02, 2026Vision-language models (VLMs) have been explored for visual programming, where they generate code to solve visual tasks. However, most prior work focuses on visual programming for productivity; it remains unclear how well current VLMs perform on education-oriented visual programming and what factors limit their performance. To bridge this gap, we introduce TurtleAI, a benchmark containing 823 tasks curated based on real-world visual programming tasks in the Turtle Graphics domain. Solving these tasks requires models to perceive geometric patterns, reason about spatial relationships, and synthesize Python code that faithfully reproduces geometric patterns. We evaluate 20+ VLMs, including GPT-5, GPT-4o, and Qwen2-VL-72B, and find that they struggle significantly, with most achieving success rates below 30%. To address these limitations, we propose a data generation technique that requires only a small set of seed samples. Fine-tuning Qwen2-VL-72B on the resulting synthetic data yields an improvement of about 20% on real-world tasks. Our failure analysis reveals that GPT-4o struggles with spatial reasoning and precise visual replication, whereas fine-tuning primarily improves the alignment between visual reasoning and code implementation.
What Semantics Survive the Connector? Diagnosing VLM-to-DiT Alignment in Video Editing
May 20, 2026Flow matching based video generative models have been increasingly relying on prepended Vision-Language Models (VLMs) to handle complex, instruction-based video editing. The prevailing assumption underlying this paradigm is that a connector module can seamlessly align the VLM's rich multi-modal reasoning with the original text embedding space of DiTs. However, we hypothesize that this alignment acts as a severe semantic bottleneck, degrading fine-grained structural variables. Verifying this is challenging, as end-to-end evaluations conflate alignment failures with generation errors, and natural datasets lack disentangled annotations. To rigorously investigate this, we propose a controlled data processing pipeline based on video composition that results in TRACE-Edit, a diagnostic dataset focusing on relation-based editing. Leveraging this dataset, we propose a comprehensive diagnostic protocol to analyze two important designs of meta-query and connector in the existing video editing models. Systematic evaluation of four representative model cases reveals that fine-grained structural semantics can be severely degraded during alignment. Our findings overturn the assumption of lossless semantic transfer, identifying the VLM-to-DiT alignment as a major bottleneck and providing a new diagnostic foundation for future multi-modal alignment architectures.
Exploration vs. Fixation: Scaffolding Divergent and Convergent Thinking for Human-AI Co-Creation with Generative Models
Dec 20, 2025Generative AI has begun to democratize creative work, enabling novices to produce complex artifacts such as code, images, and videos. However, in practice, existing interaction paradigms often fail to support divergent exploration: users tend to converge too quickly on early ``good enough'' results and struggle to move beyond them, leading to premature convergence and design fixation that constrains their creative potential. To address this, we propose a structured, process-oriented human-AI co-creation paradigm including divergent and convergent thinking stages, grounded in Wallas's model of creativity. To avoid design fixation, our paradigm scaffolds both high-level exploration of conceptual ideas in the early divergent thinking phase and low-level exploration of variations in the later convergent thinking phrase. We instantiate this paradigm in HAIExplore, an image co-creation system that (i) scaffolds divergent thinking through a dedicated brainstorming stage for exploring high-level ideas in a conceptual space, and (ii) scaffolds convergent refinement through an interface that externalizes users' refinement intentions as interpretable parameters and options, making the refinement process more controllable and easier to explore. We report on a within-subjects study comparing HAIExplore with a widely used linear chat interface (ChatGPT) for creative image generation. Our findings show that explicitly scaffolding the creative process into brainstorming and refinement stages can mitigate design fixation, improve perceived controllability and alignment with users' intentions, and better support the non-linear nature of creative work. We conclude with design implications for future creativity support tools and human-AI co-creation workflows.
HeadGAP: Few-shot 3D Head Avatar via Generalizable Gaussian Priors
Aug 12, 2024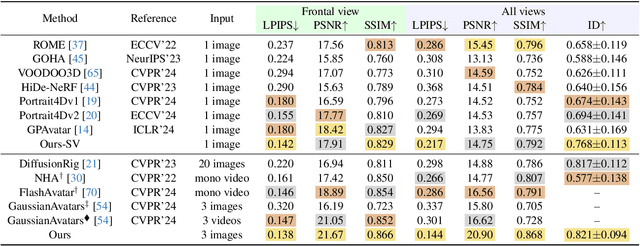

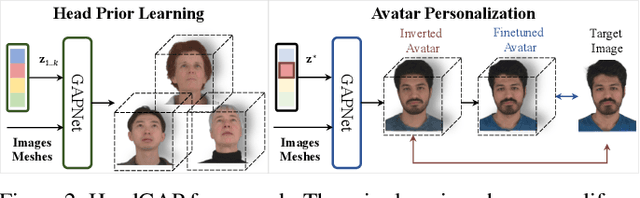
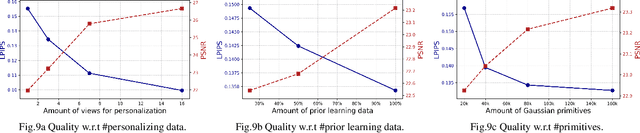
In this paper, we present a novel 3D head avatar creation approach capable of generalizing from few-shot in-the-wild data with high-fidelity and animatable robustness. Given the underconstrained nature of this problem, incorporating prior knowledge is essential. Therefore, we propose a framework comprising prior learning and avatar creation phases. The prior learning phase leverages 3D head priors derived from a large-scale multi-view dynamic dataset, and the avatar creation phase applies these priors for few-shot personalization. Our approach effectively captures these priors by utilizing a Gaussian Splatting-based auto-decoder network with part-based dynamic modeling. Our method employs identity-shared encoding with personalized latent codes for individual identities to learn the attributes of Gaussian primitives. During the avatar creation phase, we achieve fast head avatar personalization by leveraging inversion and fine-tuning strategies. Extensive experiments demonstrate that our model effectively exploits head priors and successfully generalizes them to few-shot personalization, achieving photo-realistic rendering quality, multi-view consistency, and stable animation.
Program Synthesis Benchmark for Visual Programming in XLogoOnline Environment
Jun 17, 2024



Large language and multimodal models have shown remarkable successes on various benchmarks focused on specific skills such as general-purpose programming, natural language understanding, math word problem-solving, and visual question answering. However, it is unclear how well these models perform on tasks that require a combination of these skills. In this paper, we curate a novel program synthesis benchmark based on the XLogoOnline visual programming environment. The benchmark comprises 85 real-world tasks from the Mini-level of the XLogoOnline environment, each requiring a combination of different skills such as spatial planning, basic programming, and logical reasoning. Our evaluation shows that current state-of-the-art models like GPT-4V and Llama3-70B struggle to solve these tasks, achieving only 20% and 2.35% success rates. Next, we develop a fine-tuning pipeline to boost the performance of models by leveraging a large-scale synthetic training dataset with over 80000 tasks. Moreover, we showcase how emulator-driven feedback can be used to design a curriculum over training data distribution. We showcase that a fine-tuned Llama3-8B drastically outperforms GPT-4V and Llama3-70B models, and provide an in-depth analysis of the models' expertise across different skill dimensions. We will publicly release the benchmark for future research on program synthesis in visual programming.
OHTA: One-shot Hand Avatar via Data-driven Implicit Priors
Feb 29, 2024In this paper, we delve into the creation of one-shot hand avatars, attaining high-fidelity and drivable hand representations swiftly from a single image. With the burgeoning domains of the digital human, the need for quick and personalized hand avatar creation has become increasingly critical. Existing techniques typically require extensive input data and may prove cumbersome or even impractical in certain scenarios. To enhance accessibility, we present a novel method OHTA (One-shot Hand avaTAr) that enables the creation of detailed hand avatars from merely one image. OHTA tackles the inherent difficulties of this data-limited problem by learning and utilizing data-driven hand priors. Specifically, we design a hand prior model initially employed for 1) learning various hand priors with available data and subsequently for 2) the inversion and fitting of the target identity with prior knowledge. OHTA demonstrates the capability to create high-fidelity hand avatars with consistent animatable quality, solely relying on a single image. Furthermore, we illustrate the versatility of OHTA through diverse applications, encompassing text-to-avatar conversion, hand editing, and identity latent space manipulation.
Joint2Human: High-quality 3D Human Generation via Compact Spherical Embedding of 3D Joints
Dec 14, 2023
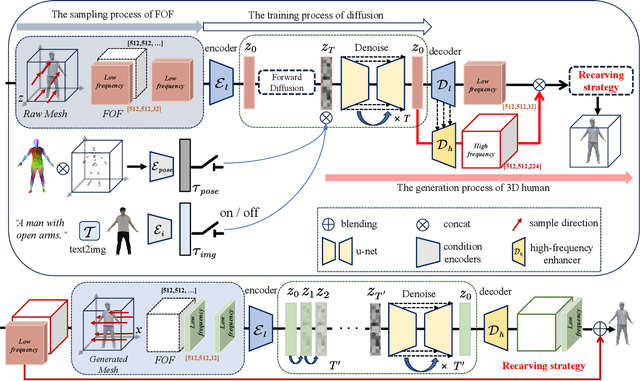

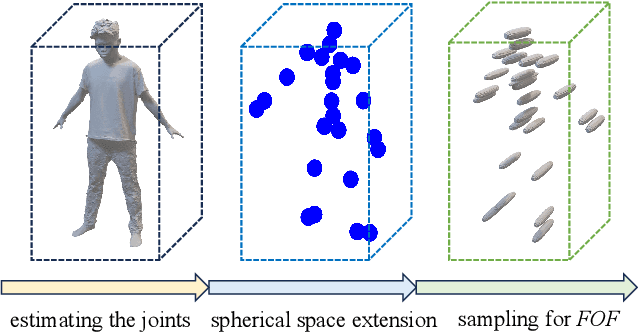
3D human generation is increasingly significant in various applications. However, the direct use of 2D generative methods in 3D generation often results in significant loss of local details, while methods that reconstruct geometry from generated images struggle with global view consistency. In this work, we introduce Joint2Human, a novel method that leverages 2D diffusion models to generate detailed 3D human geometry directly, ensuring both global structure and local details. To achieve this, we employ the Fourier occupancy field (FOF) representation, enabling the direct production of 3D shapes as preliminary results using 2D generative models. With the proposed high-frequency enhancer and the multi-view recarving strategy, our method can seamlessly integrate the details from different views into a uniform global shape.To better utilize the 3D human prior and enhance control over the generated geometry, we introduce a compact spherical embedding of 3D joints. This allows for effective application of pose guidance during the generation process. Additionally, our method is capable of generating 3D humans guided by textual inputs. Our experimental results demonstrate the capability of our method to ensure global structure, local details, high resolution, and low computational cost, simultaneously. More results and code can be found on our project page at http://cic.tju.edu.cn/faculty/likun/projects/Joint2Human.
SemanticBoost: Elevating Motion Generation with Augmented Textual Cues
Oct 31, 2023

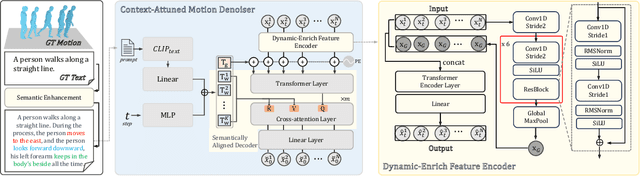

Current techniques face difficulties in generating motions from intricate semantic descriptions, primarily due to insufficient semantic annotations in datasets and weak contextual understanding. To address these issues, we present SemanticBoost, a novel framework that tackles both challenges simultaneously. Our framework comprises a Semantic Enhancement module and a Context-Attuned Motion Denoiser (CAMD). The Semantic Enhancement module extracts supplementary semantics from motion data, enriching the dataset's textual description and ensuring precise alignment between text and motion data without depending on large language models. On the other hand, the CAMD approach provides an all-encompassing solution for generating high-quality, semantically consistent motion sequences by effectively capturing context information and aligning the generated motion with the given textual descriptions. Distinct from existing methods, our approach can synthesize accurate orientational movements, combined motions based on specific body part descriptions, and motions generated from complex, extended sentences. Our experimental results demonstrate that SemanticBoost, as a diffusion-based method, outperforms auto-regressive-based techniques, achieving cutting-edge performance on the Humanml3D dataset while maintaining realistic and smooth motion generation quality.
Realistic Full-Body Tracking from Sparse Observations via Joint-Level Modeling
Aug 17, 2023To bridge the physical and virtual worlds for rapidly developed VR/AR applications, the ability to realistically drive 3D full-body avatars is of great significance. Although real-time body tracking with only the head-mounted displays (HMDs) and hand controllers is heavily under-constrained, a carefully designed end-to-end neural network is of great potential to solve the problem by learning from large-scale motion data. To this end, we propose a two-stage framework that can obtain accurate and smooth full-body motions with the three tracking signals of head and hands only. Our framework explicitly models the joint-level features in the first stage and utilizes them as spatiotemporal tokens for alternating spatial and temporal transformer blocks to capture joint-level correlations in the second stage. Furthermore, we design a set of loss terms to constrain the task of a high degree of freedom, such that we can exploit the potential of our joint-level modeling. With extensive experiments on the AMASS motion dataset and real-captured data, we validate the effectiveness of our designs and show our proposed method can achieve more accurate and smooth motion compared to existing approaches.
Railway Network Delay Evolution: A Heterogeneous Graph Neural Network Approach
Mar 27, 2023Railway operations involve different types of entities (stations, trains, etc.), making the existing graph/network models with homogenous nodes (i.e., the same kind of nodes) incapable of capturing the interactions between the entities. This paper aims to develop a heterogeneous graph neural network (HetGNN) model, which can address different types of nodes (i.e., heterogeneous nodes), to investigate the train delay evolution on railway networks. To this end, a graph architecture combining the HetGNN model and the GraphSAGE homogeneous GNN (HomoGNN), called SAGE-Het, is proposed. The aim is to capture the interactions between trains, trains and stations, and stations and other stations on delay evolution based on different edges. In contrast to the traditional methods that require the inputs to have constant dimensions (e.g., in rectangular or grid-like arrays) or only allow homogeneous nodes in the graph, SAGE-Het allows for flexible inputs and heterogeneous nodes. The data from two sub-networks of the China railway network are applied to test the performance and robustness of the proposed SAGE-Het model. The experimental results show that SAGE-Het exhibits better performance than the existing delay prediction methods and some advanced HetGNNs used for other prediction tasks; the predictive performances of SAGE-Het under different prediction time horizons (10/20/30 min ahead) all outperform other baseline methods; Specifically, the influences of train interactions on delay propagation are investigated based on the proposed model. The results show that train interactions become subtle when the train headways increase . This finding directly contributes to decision-making in the situation where conflict-resolution or train-canceling actions are needed.