 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaGRPO: A Capability-Aware Adaptive Enhancement for Flow-based GRPO
Jun 05, 2026Group Relative Policy Optimization (GRPO) has demonstrated remarkable success in aligning text-to-image (T2I) flow models with human preferences. However, we have identified that the learning loop of current flow-based GRPO is fundamentally decoupled from the learner's current capability, suffering from critical blind spots at both prompt selection and advantage estimation: (i) Existing methods sample prompts randomly, overlooking the substantial impact of data selection on reinforcement learning (RL) efficacy--a factor proven crucial in GRPO for large language models; (ii) They evaluate sample quality solely relying on intra-group statistics, lacking a global perspective to accurately measure true policy improvement. To address these issues, we propose Adaptive GRPO (AdaGRPO), a novel capability-aware RL algorithm tailored for flow models. Specifically, AdaGRPO consists of two principal components: (i) Online Curriculum Filtering Strategy: Dynamically tracks the model's proficiency and adaptively selects prompts that best match its current learning boundary; (ii) Cross-Level Advantage Fusion: Synergistically integrates fine-grained intra-group advantages with macro-level global advantages, providing a comprehensive and unbiased policy evaluation. As a lightweight, plug-and-play module, AdaGRPO can be seamlessly integrated with existing frameworks such as Flow-GRPO, DanceGRPO, and Flow-CPS. Extensive experiments demonstrate that AdaGRPO consistently drives performance gains while significantly stabilizes GRPO training for flow models.
Inline Critic Steers Image Editing
May 12, 2026Instruction-based image editing exhibits heterogeneous difficulty not only across cases but also across regions of an image, motivating refinement approaches that allocate correction to where the model struggles. Existing refinement signals arrive late, after a fully generated image or a completed denoising step. We ask whether such a signal can act within an ongoing forward pass. To investigate this, we probe a frozen image-editing model and find that although generation capability emerges only in the last few layers, the error pattern is already set in early layers (rank correlation \r{ho} = 0.83 with the final-layer error map). Based on this, we introduce Inline Critic, a learnable token that critiques a frozen model's predictions at its intermediate layers and steers its hidden states to refine generation during the forward pass. A three-stage recipe is proposed to stabilize the training from learning how to critique to steering generation. As a result, we achieve state of the art on GEdit-Bench (7.89), a +9.4 gain on RISEBench over the same backbone, and the strongest open-source result on KRIS-Bench (81.92, surpassing GPT-4o). We further provide analyses showing that the critic genuinely shapes the model's attention and prediction updates at subsequent layers.
Beyond Thinking: Imagining in 360$^\circ$ for Humanoid Visual Search
May 09, 2026Humanoid Visual Search (HVS) requires agents to actively explore immersive 360$^\circ$ environments. While prior methods treat this as a monolithic task relying on cumulative, multi-turn Chain-of-Thought (CoT) reasoning, they impose heavy cognitive burdens and require expensive trajectory-level annotations. In this paper, we propose Imagining in 360$^\circ$, a novel framework that decouples the exploration process into a specialized Imaginator and an Actor. The Imaginator functions as a probabilistic predictor of spatial priors; instead of maintaining a cumulative reasoning chain, it infers the semantic layout of both observed and unobserved regions in a single step. By sampling multiple hypotheses within this semantic space, we provide the Actor with a distribution of effective spatial information, offering robust guidance that hedges against uncertainty during active search. This decoupled architecture significantly lowers data engineering costs by eliminating the need for full-trajectory CoT annotations, enabling the generation of over 1.96 million curated training samples. Extensive experiments demonstrate that explicitly modeling semantic spatial priors drastically improves search efficiency and success rates in complex, in-the-wild environments.
Tri-Prompting: Video Diffusion with Unified Control over Scene, Subject, and Motion
Mar 16, 2026Recent video diffusion models have made remarkable strides in visual quality, yet precise, fine-grained control remains a key bottleneck that limits practical customizability for content creation. For AI video creators, three forms of control are crucial: (i) scene composition, (ii) multi-view consistent subject customization, and (iii) camera-pose or object-motion adjustment. Existing methods typically handle these dimensions in isolation, with limited support for multi-view subject synthesis and identity preservation under arbitrary pose changes. This lack of a unified architecture makes it difficult to support versatile, jointly controllable video. We introduce Tri-Prompting, a unified framework and two-stage training paradigm that integrates scene composition, multi-view subject consistency, and motion control. Our approach leverages a dual-condition motion module driven by 3D tracking points for background scenes and downsampled RGB cues for foreground subjects. To ensure a balance between controllability and visual realism, we further propose an inference ControlNet scale schedule. Tri-Prompting supports novel workflows, including 3D-aware subject insertion into any scenes and manipulation of existing subjects in an image. Experimental results demonstrate that Tri-Prompting significantly outperforms specialized baselines such as Phantom and DaS in multi-view subject identity, 3D consistency, and motion accuracy.
From Sparse to Dense: Multi-View GRPO for Flow Models via Augmented Condition Space
Mar 13, 2026Group Relative Policy Optimization (GRPO) has emerged as a powerful framework for preference alignment in text-to-image (T2I) flow models. However, we observe that the standard paradigm where evaluating a group of generated samples against a single condition suffers from insufficient exploration of inter-sample relationships, constraining both alignment efficacy and performance ceilings. To address this sparse single-view evaluation scheme, we propose Multi-View GRPO (MV-GRPO), a novel approach that enhances relationship exploration by augmenting the condition space to create a dense multi-view reward mapping. Specifically, for a group of samples generated from one prompt, MV-GRPO leverages a flexible Condition Enhancer to generate semantically adjacent yet diverse captions. These captions enable multi-view advantage re-estimation, capturing diverse semantic attributes and providing richer optimization signals. By deriving the probability distribution of the original samples conditioned on these new captions, we can incorporate them into the training process without costly sample regeneration. Extensive experiments demonstrate that MV-GRPO achieves superior alignment performance over state-of-the-art methods.
MTPano: Multi-Task Panoramic Scene Understanding via Label-Free Integration of Dense Prediction Priors
Feb 05, 2026Comprehensive panoramic scene understanding is critical for immersive applications, yet it remains challenging due to the scarcity of high-resolution, multi-task annotations. While perspective foundation models have achieved success through data scaling, directly adapting them to the panoramic domain often fails due to severe geometric distortions and coordinate system discrepancies. Furthermore, the underlying relations between diverse dense prediction tasks in spherical spaces are underexplored. To address these challenges, we propose MTPano, a robust multi-task panoramic foundation model established by a label-free training pipeline. First, to circumvent data scarcity, we leverage powerful perspective dense priors. We project panoramic images into perspective patches to generate accurate, domain-gap-free pseudo-labels using off-the-shelf foundation models, which are then re-projected to serve as patch-wise supervision. Second, to tackle the interference between task types, we categorize tasks into rotation-invariant (e.g., depth, segmentation) and rotation-variant (e.g., surface normals) groups. We introduce the Panoramic Dual BridgeNet, which disentangles these feature streams via geometry-aware modulation layers that inject absolute position and ray direction priors. To handle the distortion from equirectangular projections (ERP), we incorporate ERP token mixers followed by a dual-branch BridgeNet for interactions with gradient truncation, facilitating beneficial cross-task information sharing while blocking conflicting gradients from incompatible task attributes. Additionally, we introduce auxiliary tasks (image gradient, point map, etc.) to fertilize the cross-task learning process. Extensive experiments demonstrate that MTPano achieves state-of-the-art performance on multiple benchmarks and delivers competitive results against task-specific panoramic specialist foundation models.
RePlan: Reasoning-guided Region Planning for Complex Instruction-based Image Editing
Dec 18, 2025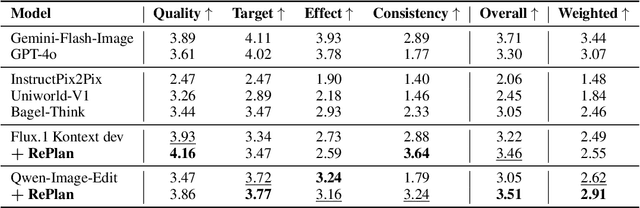
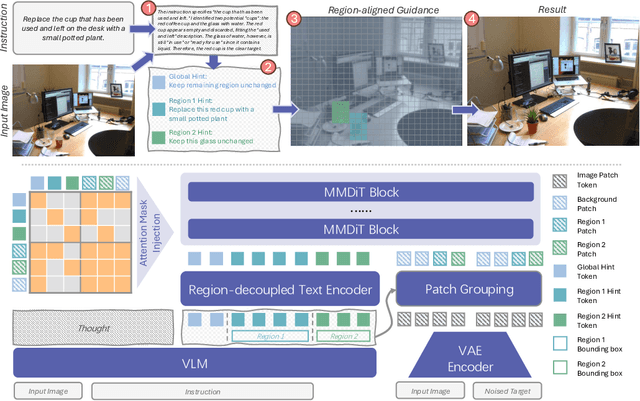

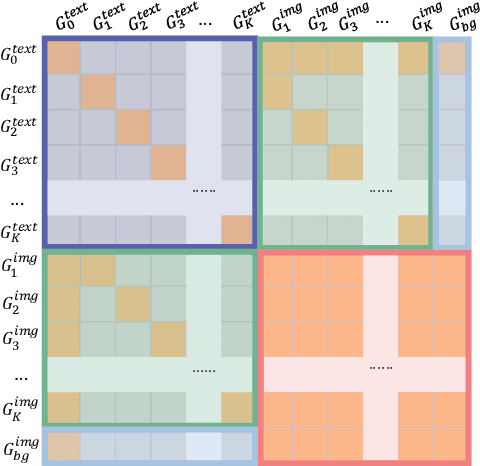
Instruction-based image editing enables natural-language control over visual modifications, yet existing models falter under Instruction-Visual Complexity (IV-Complexity), where intricate instructions meet cluttered or ambiguous scenes. We introduce RePlan (Region-aligned Planning), a plan-then-execute framework that couples a vision-language planner with a diffusion editor. The planner decomposes instructions via step-by-step reasoning and explicitly grounds them to target regions; the editor then applies changes using a training-free attention-region injection mechanism, enabling precise, parallel multi-region edits without iterative inpainting. To strengthen planning, we apply GRPO-based reinforcement learning using 1K instruction-only examples, yielding substantial gains in reasoning fidelity and format reliability. We further present IV-Edit, a benchmark focused on fine-grained grounding and knowledge-intensive edits. Across IV-Complex settings, RePlan consistently outperforms strong baselines trained on far larger datasets, improving regional precision and overall fidelity. Our project page: https://replan-iv-edit.github.io
UniSER: A Foundation Model for Unified Soft Effects Removal
Nov 18, 2025Digital images are often degraded by soft effects such as lens flare, haze, shadows, and reflections, which reduce aesthetics even though the underlying pixels remain partially visible. The prevailing works address these degradations in isolation, developing highly specialized, specialist models that lack scalability and fail to exploit the shared underlying essences of these restoration problems. While specialist models are limited, recent large-scale pretrained generalist models offer powerful, text-driven image editing capabilities. while recent general-purpose systems (e.g., GPT-4o, Flux Kontext, Nano Banana) require detailed prompts and often fail to achieve robust removal on these fine-grained tasks or preserve identity of the scene. Leveraging the common essence of soft effects, i.e., semi-transparent occlusions, we introduce a foundational versatile model UniSER, capable of addressing diverse degradations caused by soft effects within a single framework. Our methodology centers on curating a massive 3.8M-pair dataset to ensure robustness and generalization, which includes novel, physically-plausible data to fill critical gaps in public benchmarks, and a tailored training pipeline that fine-tunes a Diffusion Transformer to learn robust restoration priors from this diverse data, integrating fine-grained mask and strength controls. This synergistic approach allows UniSER to significantly outperform both specialist and generalist models, achieving robust, high-fidelity restoration in the wild.
Social Agent: Mastering Dyadic Nonverbal Behavior Generation via Conversational LLM Agents
Oct 06, 2025We present Social Agent, a novel framework for synthesizing realistic and contextually appropriate co-speech nonverbal behaviors in dyadic conversations. In this framework, we develop an agentic system driven by a Large Language Model (LLM) to direct the conversation flow and determine appropriate interactive behaviors for both participants. Additionally, we propose a novel dual-person gesture generation model based on an auto-regressive diffusion model, which synthesizes coordinated motions from speech signals. The output of the agentic system is translated into high-level guidance for the gesture generator, resulting in realistic movement at both the behavioral and motion levels. Furthermore, the agentic system periodically examines the movements of interlocutors and infers their intentions, forming a continuous feedback loop that enables dynamic and responsive interactions between the two participants. User studies and quantitative evaluations show that our model significantly improves the quality of dyadic interactions, producing natural, synchronized nonverbal behaviors.
LaRender: Training-Free Occlusion Control in Image Generation via Latent Rendering
Aug 11, 2025



We propose a novel training-free image generation algorithm that precisely controls the occlusion relationships between objects in an image. Existing image generation methods typically rely on prompts to influence occlusion, which often lack precision. While layout-to-image methods provide control over object locations, they fail to address occlusion relationships explicitly. Given a pre-trained image diffusion model, our method leverages volume rendering principles to "render" the scene in latent space, guided by occlusion relationships and the estimated transmittance of objects. This approach does not require retraining or fine-tuning the image diffusion model, yet it enables accurate occlusion control due to its physics-grounded foundation. In extensive experiments, our method significantly outperforms existing approaches in terms of occlusion accuracy. Furthermore, we demonstrate that by adjusting the opacities of objects or concepts during rendering, our method can achieve a variety of effects, such as altering the transparency of objects, the density of mass (e.g., forests), the concentration of particles (e.g., rain, fog), the intensity of light, and the strength of lens effects, etc.