 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen Long-Tailed Recognition in a Dynamic World
Paper and Code
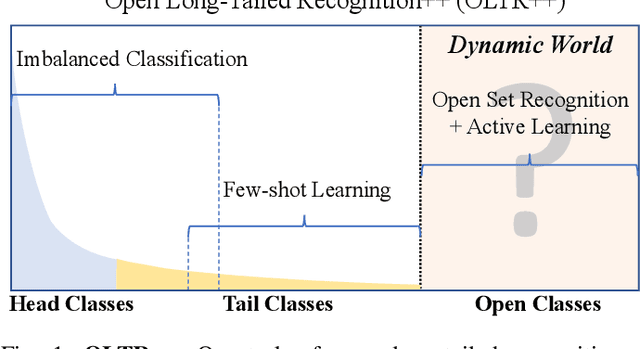
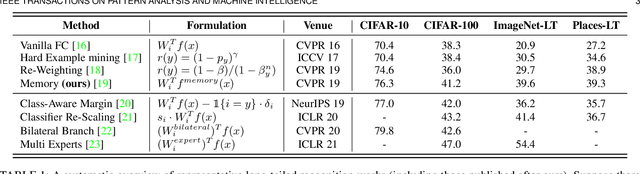
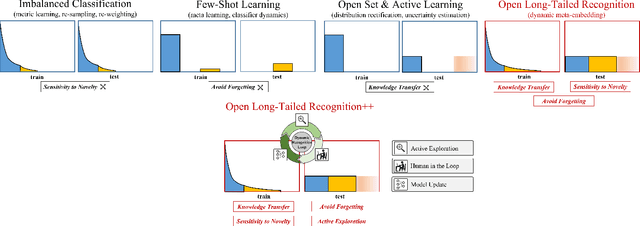

Real world data often exhibits a long-tailed and open-ended (with unseen classes) distribution. A practical recognition system must balance between majority (head) and minority (tail) classes, generalize across the distribution, and acknowledge novelty upon the instances of unseen classes (open classes). We define Open Long-Tailed Recognition++ (OLTR++) as learning from such naturally distributed data and optimizing for the classification accuracy over a balanced test set which includes both known and open classes. OLTR++ handles imbalanced classification, few-shot learning, open-set recognition, and active learning in one integrated algorithm, whereas existing classification approaches often focus only on one or two aspects and deliver poorly over the entire spectrum. The key challenges are: 1) how to share visual knowledge between head and tail classes, 2) how to reduce confusion between tail and open classes, and 3) how to actively explore open classes with learned knowledge. Our algorithm, OLTR++, maps images to a feature space such that visual concepts can relate to each other through a memory association mechanism and a learned metric (dynamic meta-embedding) that both respects the closed world classification of seen classes and acknowledges the novelty of open classes. Additionally, we propose an active learning scheme based on visual memory, which learns to recognize open classes in a data-efficient manner for future expansions. On three large-scale open long-tailed datasets we curated from ImageNet (object-centric), Places (scene-centric), and MS1M (face-centric) data, as well as three standard benchmarks (CIFAR-10-LT, CIFAR-100-LT, and iNaturalist-18), our approach, as a unified framework, consistently demonstrates competitive performance. Notably, our approach also shows strong potential for the active exploration of open classes and the fairness analysis of minority groups.