 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoiré Video Authentication: A Physical Signature Against AI Video Generation
Apr 02, 2026Recent advances in video generation have made AI-synthesized content increasingly difficult to distinguish from real footage. We propose a physics-based authentication signature that real cameras produce naturally, but that generative models cannot faithfully reproduce. Our approach exploits the Moiré effect: the interference fringes formed when a camera views a compact two-layer grating structure. We derive the Moiré motion invariant, showing that fringe phase and grating image displacement are linearly coupled by optical geometry, independent of viewing distance and grating structure. A verifier extracts both signals from video and tests their correlation. We validate the invariant on both real-captured and AI-generated videos from multiple state-of-the-art generators, and find that real and AI-generated videos produce significantly different correlation signatures, suggesting a robust means of differentiating them. Our work demonstrates that deterministic optical phenomena can serve as physically grounded, verifiable signatures against AI-generated video.
Ego2Web: A Web Agent Benchmark Grounded in Egocentric Videos
Mar 23, 2026Multimodal AI agents are increasingly automating complex real-world workflows that involve online web execution. However, current web-agent benchmarks suffer from a critical limitation: they focus entirely on web-based interaction and perception, lacking grounding in the user's real-world physical surroundings. This limitation prevents evaluation in crucial scenarios, such as when an agent must use egocentric visual perception (e.g., via AR glasses) to recognize an object in the user's surroundings and then complete a related task online. To address this gap, we introduce Ego2Web, the first benchmark designed to bridge egocentric video perception and web agent execution. Ego2Web pairs real-world first-person video recordings with web tasks that require visual understanding, web task planning, and interaction in an online environment for successful completion. We utilize an automatic data-generation pipeline combined with human verification and refinement to curate well-constructed, high-quality video-task pairs across diverse web task types, including e-commerce, media retrieval, knowledge lookup, etc. To facilitate accurate and scalable evaluation for our benchmark, we also develop a novel LLM-as-a-Judge automatic evaluation method, Ego2WebJudge, which achieves approximately 84% agreement with human judgment, substantially higher than existing evaluation methods. Experiments with diverse SoTA agents on our Ego2Web show that their performance is weak, with substantial headroom across all task categories. We also conduct a comprehensive ablation study on task design, highlighting the necessity of accurate video understanding in the proposed task and the limitations of current agents. We hope Ego2Web can be a critical new resource for developing truly capable AI assistants that can seamlessly see, understand, and act across the physical and digital worlds.
Image Diffusion Preview with Consistency Solver
Dec 15, 2025The slow inference process of image diffusion models significantly degrades interactive user experiences. To address this, we introduce Diffusion Preview, a novel paradigm employing rapid, low-step sampling to generate preliminary outputs for user evaluation, deferring full-step refinement until the preview is deemed satisfactory. Existing acceleration methods, including training-free solvers and post-training distillation, struggle to deliver high-quality previews or ensure consistency between previews and final outputs. We propose ConsistencySolver derived from general linear multistep methods, a lightweight, trainable high-order solver optimized via Reinforcement Learning, that enhances preview quality and consistency. Experimental results demonstrate that ConsistencySolver significantly improves generation quality and consistency in low-step scenarios, making it ideal for efficient preview-and-refine workflows. Notably, it achieves FID scores on-par with Multistep DPM-Solver using 47% fewer steps, while outperforming distillation baselines. Furthermore, user studies indicate our approach reduces overall user interaction time by nearly 50% while maintaining generation quality. Code is available at https://github.com/G-U-N/consolver.
BabyVLM-V2: Toward Developmentally Grounded Pretraining and Benchmarking of Vision Foundation Models
Dec 11, 2025Early children's developmental trajectories set up a natural goal for sample-efficient pretraining of vision foundation models. We introduce BabyVLM-V2, a developmentally grounded framework for infant-inspired vision-language modeling that extensively improves upon BabyVLM-V1 through a longitudinal, multifaceted pretraining set, a versatile model, and, most importantly, DevCV Toolbox for cognitive evaluation. The pretraining set maximizes coverage while minimizing curation of a longitudinal, infant-centric audiovisual corpus, yielding video-utterance, image-utterance, and multi-turn conversational data that mirror infant experiences. DevCV Toolbox adapts all vision-related measures of the recently released NIH Baby Toolbox into a benchmark suite of ten multimodal tasks, covering spatial reasoning, memory, and vocabulary understanding aligned with early children's capabilities. Experimental results show that a compact model pretrained from scratch can achieve competitive performance on DevCV Toolbox, outperforming GPT-4o on some tasks. We hope the principled, unified BabyVLM-V2 framework will accelerate research in developmentally plausible pretraining of vision foundation models.
Culture in Action: Evaluating Text-to-Image Models through Social Activities
Nov 07, 2025Text-to-image (T2I) diffusion models achieve impressive photorealism by training on large-scale web data, but models inherit cultural biases and fail to depict underrepresented regions faithfully. Existing cultural benchmarks focus mainly on object-centric categories (e.g., food, attire, and architecture), overlooking the social and daily activities that more clearly reflect cultural norms. Few metrics exist for measuring cultural faithfulness. We introduce CULTIVate, a benchmark for evaluating T2I models on cross-cultural activities (e.g., greetings, dining, games, traditional dances, and cultural celebrations). CULTIVate spans 16 countries with 576 prompts and more than 19,000 images, and provides an explainable descriptor-based evaluation framework across multiple cultural dimensions, including background, attire, objects, and interactions. We propose four metrics to measure cultural alignment, hallucination, exaggerated elements, and diversity. Our findings reveal systematic disparities: models perform better for global north countries than for the global south, with distinct failure modes across T2I systems. Human studies confirm that our metrics correlate more strongly with human judgments than existing text-image metrics.
Lifting Data-Tracing Machine Unlearning to Knowledge-Tracing for Foundation Models
Jun 12, 2025Machine unlearning removes certain training data points and their influence on AI models (e.g., when a data owner revokes their decision to allow models to learn from the data). In this position paper, we propose to lift data-tracing machine unlearning to knowledge-tracing for foundation models (FMs). We support this position based on practical needs and insights from cognitive studies. Practically, tracing data cannot meet the diverse unlearning requests for FMs, which may be from regulators, enterprise users, product teams, etc., having no access to FMs' massive training data. Instead, it is convenient for these parties to issue an unlearning request about the knowledge or capability FMs (should not) possess. Cognitively, knowledge-tracing unlearning aligns with how the human brain forgets more closely than tracing individual training data points. Finally, we provide a concrete case study about a vision-language FM to illustrate how an unlearner might instantiate the knowledge-tracing machine unlearning paradigm.
Vision LLMs Are Bad at Hierarchical Visual Understanding, and LLMs Are the Bottleneck
May 30, 2025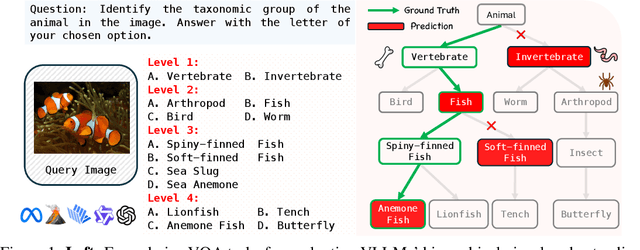
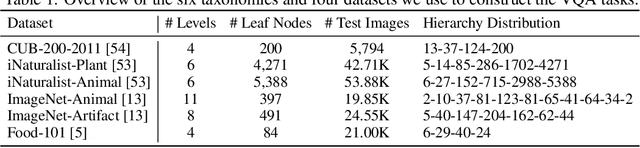

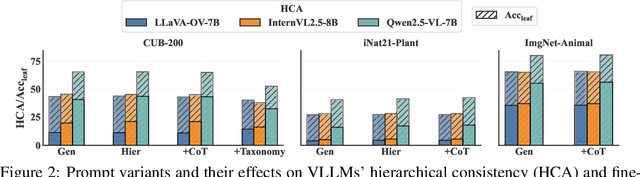
This paper reveals that many state-of-the-art large language models (LLMs) lack hierarchical knowledge about our visual world, unaware of even well-established biology taxonomies. This shortcoming makes LLMs a bottleneck for vision LLMs' hierarchical visual understanding (e.g., recognizing Anemone Fish but not Vertebrate). We arrive at these findings using about one million four-choice visual question answering (VQA) tasks constructed from six taxonomies and four image datasets. Interestingly, finetuning a vision LLM using our VQA tasks reaffirms LLMs' bottleneck effect to some extent because the VQA tasks improve the LLM's hierarchical consistency more than the vision LLM's. We conjecture that one cannot make vision LLMs understand visual concepts fully hierarchical until LLMs possess corresponding taxonomy knowledge.
SITE: towards Spatial Intelligence Thorough Evaluation
May 08, 2025Spatial intelligence (SI) represents a cognitive ability encompassing the visualization, manipulation, and reasoning about spatial relationships, underpinning disciplines from neuroscience to robotics. We introduce SITE, a benchmark dataset towards SI Thorough Evaluation in a standardized format of multi-choice visual question-answering, designed to assess large vision-language models' spatial intelligence across diverse visual modalities (single-image, multi-image, and video) and SI factors (figural to environmental scales, spatial visualization and orientation, intrinsic and extrinsic, static and dynamic). Our approach to curating the benchmark combines a bottom-up survey about 31 existing datasets and a top-down strategy drawing upon three classification systems in cognitive science, which prompt us to design two novel types of tasks about view-taking and dynamic scenes. Extensive experiments reveal that leading models fall behind human experts especially in spatial orientation, a fundamental SI factor. Moreover, we demonstrate a positive correlation between a model's spatial reasoning proficiency and its performance on an embodied AI task.
BabyVLM: Data-Efficient Pretraining of VLMs Inspired by Infant Learning
Apr 13, 2025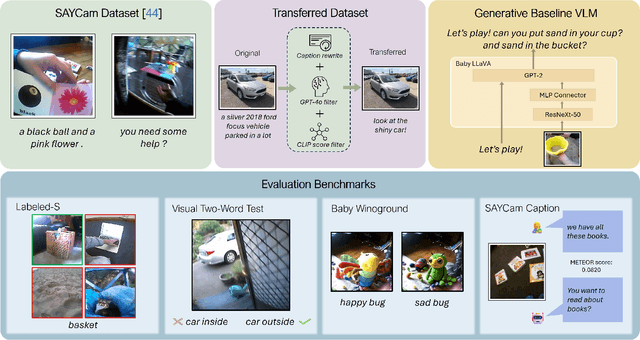

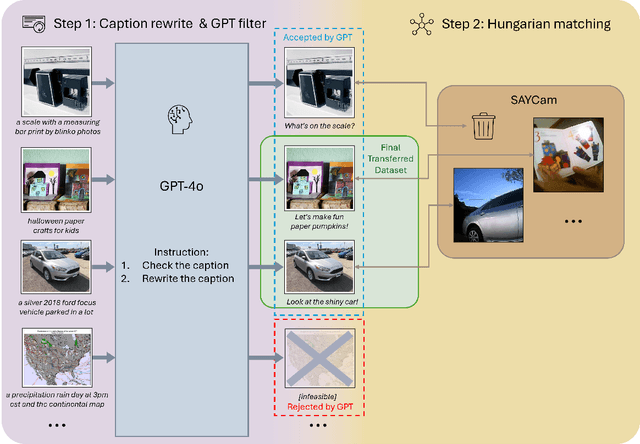

Human infants rapidly develop visual reasoning skills from minimal input, suggesting that developmentally inspired pretraining could significantly enhance the efficiency of vision-language models (VLMs). Although recent efforts have leveraged infant-inspired datasets like SAYCam, existing evaluation benchmarks remain misaligned--they are either too simplistic, narrowly scoped, or tailored for large-scale pretrained models. Additionally, training exclusively on infant data overlooks the broader, diverse input from which infants naturally learn. To address these limitations, we propose BabyVLM, a novel framework comprising comprehensive in-domain evaluation benchmarks and a synthetic training dataset created via child-directed transformations of existing datasets. We demonstrate that VLMs trained with our synthetic dataset achieve superior performance on BabyVLM tasks compared to models trained solely on SAYCam or general-purpose data of the SAYCam size. BabyVLM thus provides a robust, developmentally aligned evaluation tool and illustrates how compact models trained on carefully curated data can generalize effectively, opening pathways toward data-efficient vision-language learning paradigms.
VideoAds for Fast-Paced Video Understanding: Where Opensource Foundation Models Beat GPT-4o & Gemini-1.5 Pro
Apr 12, 2025Advertisement videos serve as a rich and valuable source of purpose-driven information, encompassing high-quality visual, textual, and contextual cues designed to engage viewers. They are often more complex than general videos of similar duration due to their structured narratives and rapid scene transitions, posing significant challenges to multi-modal large language models (MLLMs). In this work, we introduce VideoAds, the first dataset tailored for benchmarking the performance of MLLMs on advertisement videos. VideoAds comprises well-curated advertisement videos with complex temporal structures, accompanied by \textbf{manually} annotated diverse questions across three core tasks: visual finding, video summary, and visual reasoning. We propose a quantitative measure to compare VideoAds against existing benchmarks in terms of video complexity. Through extensive experiments, we find that Qwen2.5-VL-72B, an opensource MLLM, achieves 73.35\% accuracy on VideoAds, outperforming GPT-4o (66.82\%) and Gemini-1.5 Pro (69.66\%); the two proprietary models especially fall behind the opensource model in video summarization and reasoning, but perform the best in visual finding. Notably, human experts easily achieve a remarkable accuracy of 94.27\%. These results underscore the necessity of advancing MLLMs' temporal modeling capabilities and highlight VideoAds as a potentially pivotal benchmark for future research in understanding video that requires high FPS sampling. The dataset and evaluation code will be publicly available at https://videoadsbenchmark.netlify.app.