 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence Optimization for Probabilistic Encoding
Jul 22, 2025Probabilistic encoding introduces Gaussian noise into neural networks, enabling a smooth transition from deterministic to uncertain states and enhancing generalization ability. However, the randomness of Gaussian noise distorts point-based distance measurements in classification tasks. To mitigate this issue, we propose a confidence optimization probabilistic encoding (CPE) method that improves distance reliability and enhances representation learning. Specifically, we refine probabilistic encoding with two key strategies: First, we introduce a confidence-aware mechanism to adjust distance calculations, ensuring consistency and reliability in probabilistic encoding classification tasks. Second, we replace the conventional KL divergence-based variance regularization, which relies on unreliable prior assumptions, with a simpler L2 regularization term to directly constrain variance. The method we proposed is model-agnostic, and extensive experiments on natural language classification tasks demonstrate that our method significantly improves performance and generalization on both the BERT and the RoBERTa model.
Lifting Data-Tracing Machine Unlearning to Knowledge-Tracing for Foundation Models
Jun 12, 2025Machine unlearning removes certain training data points and their influence on AI models (e.g., when a data owner revokes their decision to allow models to learn from the data). In this position paper, we propose to lift data-tracing machine unlearning to knowledge-tracing for foundation models (FMs). We support this position based on practical needs and insights from cognitive studies. Practically, tracing data cannot meet the diverse unlearning requests for FMs, which may be from regulators, enterprise users, product teams, etc., having no access to FMs' massive training data. Instead, it is convenient for these parties to issue an unlearning request about the knowledge or capability FMs (should not) possess. Cognitively, knowledge-tracing unlearning aligns with how the human brain forgets more closely than tracing individual training data points. Finally, we provide a concrete case study about a vision-language FM to illustrate how an unlearner might instantiate the knowledge-tracing machine unlearning paradigm.
Vision LLMs Are Bad at Hierarchical Visual Understanding, and LLMs Are the Bottleneck
May 30, 2025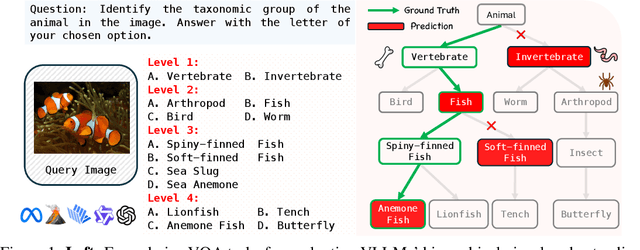
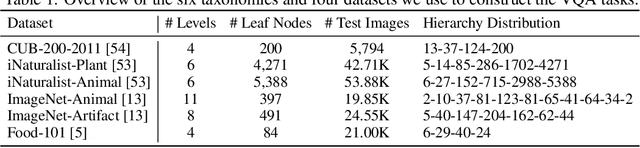

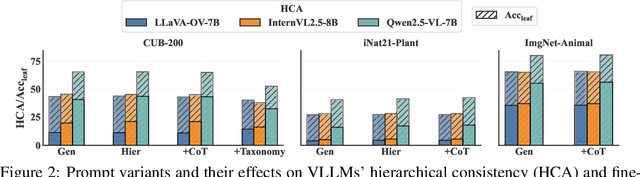
This paper reveals that many state-of-the-art large language models (LLMs) lack hierarchical knowledge about our visual world, unaware of even well-established biology taxonomies. This shortcoming makes LLMs a bottleneck for vision LLMs' hierarchical visual understanding (e.g., recognizing Anemone Fish but not Vertebrate). We arrive at these findings using about one million four-choice visual question answering (VQA) tasks constructed from six taxonomies and four image datasets. Interestingly, finetuning a vision LLM using our VQA tasks reaffirms LLMs' bottleneck effect to some extent because the VQA tasks improve the LLM's hierarchical consistency more than the vision LLM's. We conjecture that one cannot make vision LLMs understand visual concepts fully hierarchical until LLMs possess corresponding taxonomy knowledge.
Semantically-Shifted Incremental Adapter-Tuning is A Continual ViTransformer
Mar 29, 2024Class-incremental learning (CIL) aims to enable models to continuously learn new classes while overcoming catastrophic forgetting. The introduction of pre-trained models has brought new tuning paradigms to CIL. In this paper, we revisit different parameter-efficient tuning (PET) methods within the context of continual learning. We observe that adapter tuning demonstrates superiority over prompt-based methods, even without parameter expansion in each learning session. Motivated by this, we propose incrementally tuning the shared adapter without imposing parameter update constraints, enhancing the learning capacity of the backbone. Additionally, we employ feature sampling from stored prototypes to retrain a unified classifier, further improving its performance. We estimate the semantic shift of old prototypes without access to past samples and update stored prototypes session by session. Our proposed method eliminates model expansion and avoids retaining any image samples. It surpasses previous pre-trained model-based CIL methods and demonstrates remarkable continual learning capabilities. Experimental results on five CIL benchmarks validate the effectiveness of our approach, achieving state-of-the-art (SOTA) performance.
Mapping Emulation for Knowledge Distillation
May 21, 2022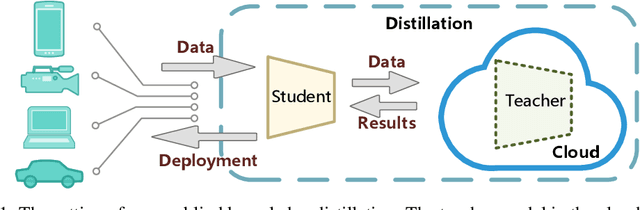
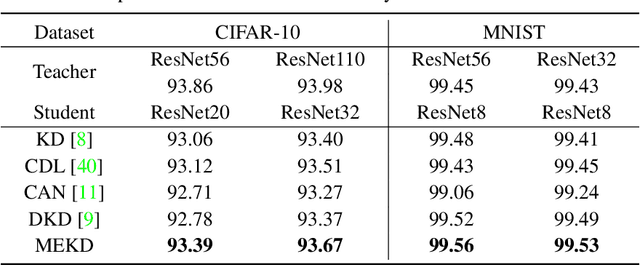
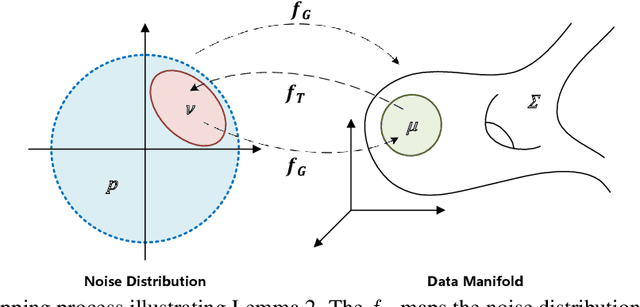
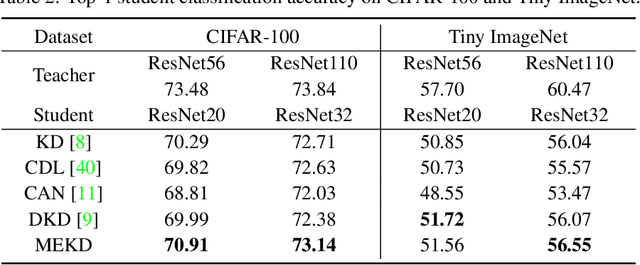
This paper formalizes the source-blind knowledge distillation problem that is essential to federated learning. A new geometric perspective is presented to view such a problem as aligning generated distributions between the teacher and student. With its guidance, a new architecture MEKD is proposed to emulate the inverse mapping through generative adversarial training. Unlike mimicking logits and aligning logit distributions, reconstructing the mapping from classifier-logits has a geometric intuition of decreasing empirical distances, and theoretical guarantees using the universal function approximation and optimal mass transportation theories. A new algorithm is also proposed to train the student model that reaches the teacher's performance source-blindly. On various benchmarks, MEKD outperforms existing source-blind KD methods, explainable with ablation studies and visualized results.
Coarse-To-Fine Incremental Few-Shot Learning
Nov 24, 2021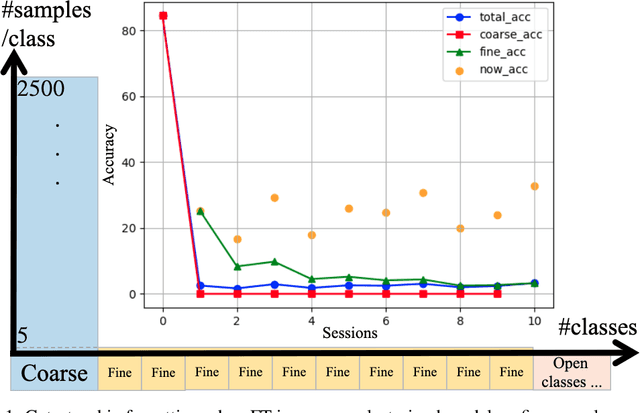

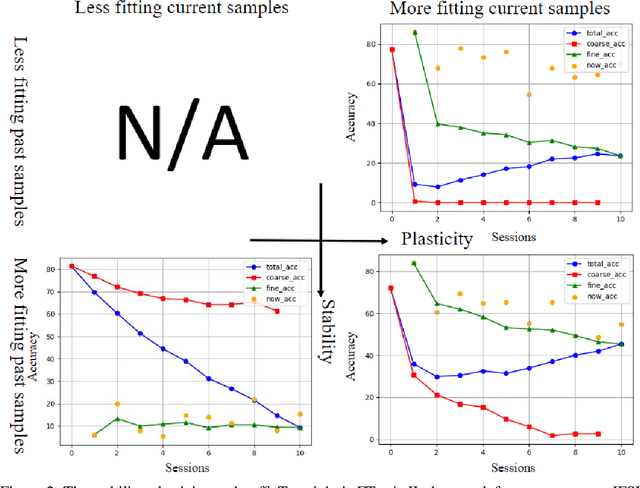
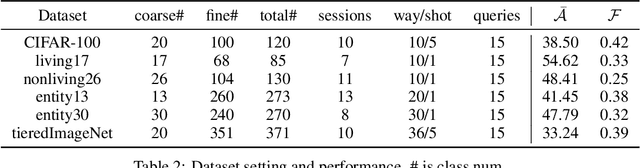
Different from fine-tuning models pre-trained on a large-scale dataset of preset classes, class-incremental learning (CIL) aims to recognize novel classes over time without forgetting pre-trained classes. However, a given model will be challenged by test images with finer-grained classes, e.g., a basenji is at most recognized as a dog. Such images form a new training set (i.e., support set) so that the incremental model is hoped to recognize a basenji (i.e., query) as a basenji next time. This paper formulates such a hybrid natural problem of coarse-to-fine few-shot (C2FS) recognition as a CIL problem named C2FSCIL, and proposes a simple, effective, and theoretically-sound strategy Knowe: to learn, normalize, and freeze a classifier's weights from fine labels, once learning an embedding space contrastively from coarse labels. Besides, as CIL aims at a stability-plasticity balance, new overall performance metrics are proposed. In that sense, on CIFAR-100, BREEDS, and tieredImageNet, Knowe outperforms all recent relevant CIL/FSCIL methods that are tailored to the new problem setting for the first time.