 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Laplacian Transformer with Progressive Sampling for Prostate Cancer Grading
Dec 11, 2025Prostate cancer grading from whole-slide images (WSIs) remains a challenging task due to the large-scale nature of WSIs, the presence of heterogeneous tissue structures, and difficulty of selecting diagnostically relevant regions. Existing approaches often rely on random or static patch selection, leading to the inclusion of redundant or non-informative regions that degrade performance. To address this, we propose a Graph Laplacian Attention-Based Transformer (GLAT) integrated with an Iterative Refinement Module (IRM) to enhance both feature learning and spatial consistency. The IRM iteratively refines patch selection by leveraging a pretrained ResNet50 for local feature extraction and a foundation model in no-gradient mode for importance scoring, ensuring only the most relevant tissue regions are preserved. The GLAT models tissue-level connectivity by constructing a graph where patches serve as nodes, ensuring spatial consistency through graph Laplacian constraints and refining feature representations via a learnable filtering mechanism that enhances discriminative histological structures. Additionally, a convex aggregation mechanism dynamically adjusts patch importance to generate a robust WSI-level representation. Extensive experiments on five public and one private dataset demonstrate that our model outperforms state-of-the-art methods, achieving higher performance and spatial consistency while maintaining computational efficiency.
RAG-Adapter: A Plug-and-Play RAG-enhanced Framework for Long Video Understanding
Mar 11, 2025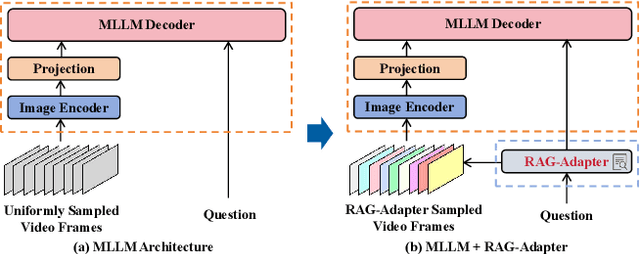
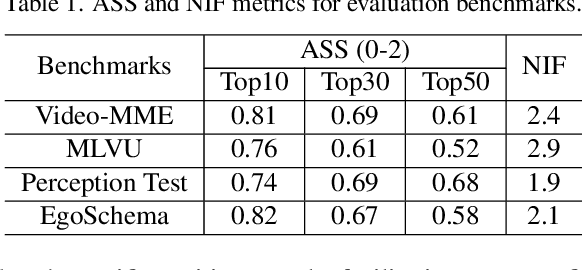
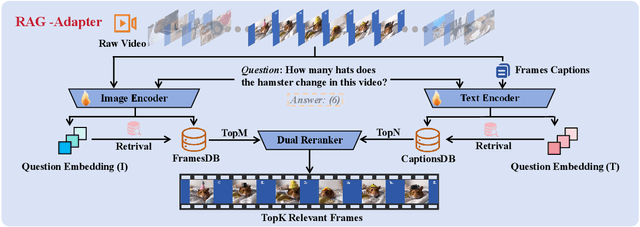
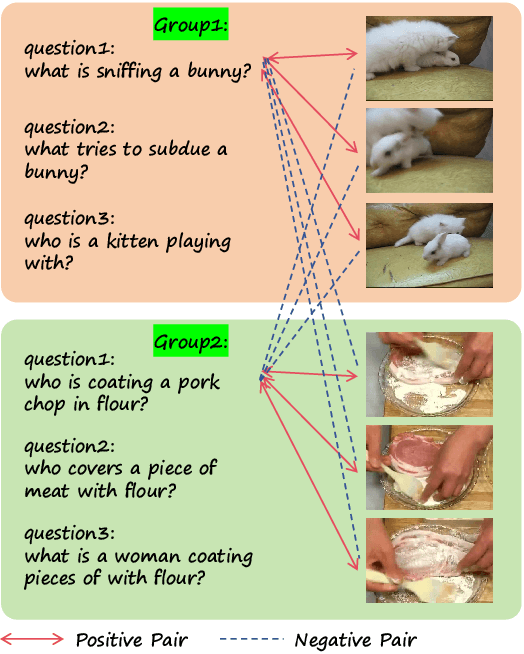
Multi-modal Large Language Models (MLLMs) capable of video understanding are advancing rapidly. To effectively assess their video comprehension capabilities, long video understanding benchmarks, such as Video-MME and MLVU, are proposed. However, these benchmarks directly use uniform frame sampling for testing, which results in significant information loss and affects the accuracy of the evaluations in reflecting the true abilities of MLLMs. To address this, we propose RAG-Adapter, a plug-and-play framework that reduces information loss during testing by sampling frames most relevant to the given question. Additionally, we introduce a Grouped-supervised Contrastive Learning (GCL) method to further enhance sampling effectiveness of RAG-Adapter through fine-tuning on our constructed MMAT dataset. Finally, we test numerous baseline MLLMs on various video understanding benchmarks, finding that RAG-Adapter sampling consistently outperforms uniform sampling (e.g., Accuracy of GPT-4o increases by 9.3 percent on Video-MME), providing a more accurate testing method for long video benchmarks.
How to Complete Domain Tuning while Keeping General Ability in LLM: Adaptive Layer-wise and Element-wise Regularization
Jan 23, 2025Large Language Models (LLMs) exhibit strong general-purpose language capabilities. However, fine-tuning these models on domain-specific tasks often leads to catastrophic forgetting, where the model overwrites or loses essential knowledge acquired during pretraining. This phenomenon significantly limits the broader applicability of LLMs. To address this challenge, we propose a novel approach to compute the element-wise importance of model parameters crucial for preserving general knowledge during fine-tuning. Our method utilizes a dual-objective optimization strategy: (1) regularization loss to retain the parameter crucial for general knowledge; (2) cross-entropy loss to adapt to domain-specific tasks. Additionally, we introduce layer-wise coefficients to account for the varying contributions of different layers, dynamically balancing the dual-objective optimization. Extensive experiments on scientific, medical, and physical tasks using GPT-J and LLaMA-3 demonstrate that our approach mitigates catastrophic forgetting while enhancing model adaptability. Compared to previous methods, our solution is approximately 20 times faster and requires only 10%-15% of the storage, highlighting the practical efficiency. The code will be released.
Gradual Vigilance and Interval Communication: Enhancing Value Alignment in Multi-Agent Debates
Dec 18, 2024
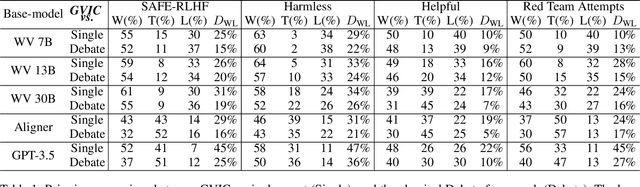
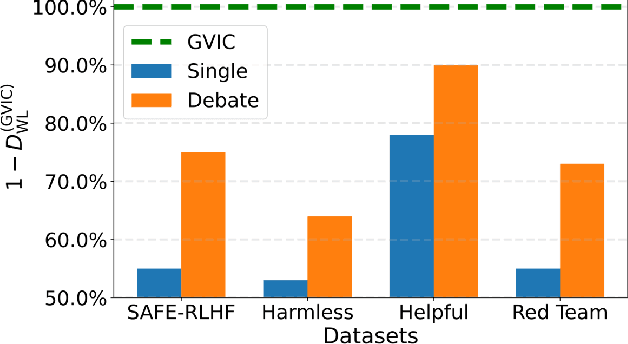
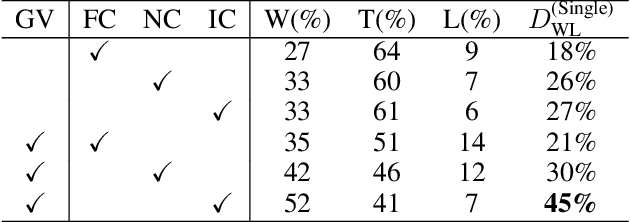
In recent years, large language models have shown exceptional performance in fulfilling diverse human needs. However, their training data can introduce harmful content, underscoring the necessity for robust value alignment. Mainstream methods, which depend on feedback learning and supervised training, are resource-intensive and may constrain the full potential of the models. Multi-Agent Debate (MAD) offers a more efficient and innovative solution by enabling the generation of reliable answers through agent interactions. To apply MAD to value alignment, we examine the relationship between the helpfulness and harmlessness of debate outcomes and individual responses, and propose a MAD based framework Gradual Vigilance and Interval Communication (GVIC). GVIC allows agents to assess risks with varying levels of vigilance and to exchange diverse information through interval communication. We theoretically prove that GVIC optimizes debate efficiency while reducing communication overhead. Experimental results demonstrate that GVIC consistently outperforms baseline methods across various tasks and datasets, particularly excelling in harmfulness mitigation and fraud prevention. Additionally, GVIC exhibits strong adaptability across different base model sizes, including both unaligned and aligned models, and across various task types.
MOSABench: Multi-Object Sentiment Analysis Benchmark for Evaluating Multimodal Large Language Models Understanding of Complex Image
Nov 25, 2024



Multimodal large language models (MLLMs) have shown remarkable progress in high-level semantic tasks such as visual question answering, image captioning, and emotion recognition. However, despite advancements, there remains a lack of standardized benchmarks for evaluating MLLMs performance in multi-object sentiment analysis, a key task in semantic understanding. To address this gap, we introduce MOSABench, a novel evaluation dataset designed specifically for multi-object sentiment analysis. MOSABench includes approximately 1,000 images with multiple objects, requiring MLLMs to independently assess the sentiment of each object, thereby reflecting real-world complexities. Key innovations in MOSABench include distance-based target annotation, post-processing for evaluation to standardize outputs, and an improved scoring mechanism. Our experiments reveal notable limitations in current MLLMs: while some models, like mPLUG-owl and Qwen-VL2, demonstrate effective attention to sentiment-relevant features, others exhibit scattered focus and performance declines, especially as the spatial distance between objects increases. This research underscores the need for MLLMs to enhance accuracy in complex, multi-object sentiment analysis tasks and establishes MOSABench as a foundational tool for advancing sentiment analysis capabilities in MLLMs.
Localization, balance and affinity: a stronger multifaceted collaborative salient object detector in remote sensing images
Oct 31, 2024


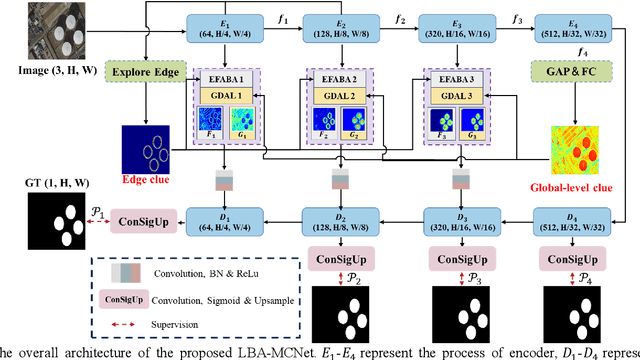
Despite significant advancements in salient object detection(SOD) in optical remote sensing images(ORSI), challenges persist due to the intricate edge structures of ORSIs and the complexity of their contextual relationships. Current deep learning approaches encounter difficulties in accurately identifying boundary features and lack efficiency in collaboratively modeling the foreground and background by leveraging contextual features. To address these challenges, we propose a stronger multifaceted collaborative salient object detector in ORSIs, termed LBA-MCNet, which incorporates aspects of localization, balance, and affinity. The network focuses on accurately locating targets, balancing detailed features, and modeling image-level global context information. Specifically, we design the Edge Feature Adaptive Balancing and Adjusting(EFABA) module for precise edge localization, using edge features to guide attention to boundaries and preserve spatial details. Moreover, we design the Global Distributed Affinity Learning(GDAL) module to model global context. It captures global context by generating an affinity map from the encoders final layer, ensuring effective modeling of global patterns. Additionally, deep supervision during deconvolution further enhances feature representation. Finally, we compared with 28 state of the art approaches on three publicly available datasets. The results clearly demonstrate the superiority of our method.
COMET: "Cone of experience" enhanced large multimodal model for mathematical problem generation
Jul 16, 2024The automatic generation of high-quality mathematical problems is practically valuable in many educational scenarios. Large multimodal model provides a novel technical approach for the mathematical problem generation because of its wide success in cross-modal data scenarios. However, the traditional method of separating problem solving from problem generation and the mainstream fine-tuning framework of monotonous data structure with homogeneous training objectives limit the application of large multimodal model in mathematical problem generation. Addressing these challenges, this paper proposes COMET, a "Cone of Experience" enhanced large multimodal model for mathematical problem generation. Firstly, from the perspective of mutual ability promotion and application logic, we unify stem generation and problem solving into mathematical problem generation. Secondly, a three-stage fine-turning framework guided by the "Cone of Experience" is proposed. The framework divides the fine-tuning data into symbolic experience, iconic experience, and direct experience to draw parallels with experiences in the career growth of teachers. Several fine-grained data construction and injection methods are designed in this framework. Finally, we construct a Chinese multimodal mathematical problem dataset to fill the vacancy of Chinese multimodal data in this field. Combined with objective and subjective indicators, experiments on multiple datasets fully verify the effectiveness of the proposed framework and model.
PTA: Enhancing Multimodal Sentiment Analysis through Pipelined Prediction and Translation-based Alignment
May 23, 2024
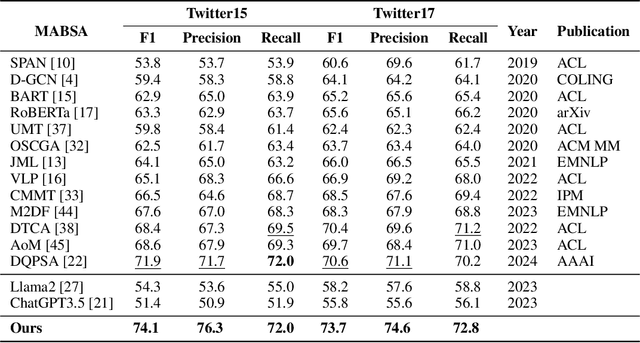


Multimodal aspect-based sentiment analysis (MABSA) aims to understand opinions in a granular manner, advancing human-computer interaction and other fields. Traditionally, MABSA methods use a joint prediction approach to identify aspects and sentiments simultaneously. However, we argue that joint models are not always superior. Our analysis shows that joint models struggle to align relevant text tokens with image patches, leading to misalignment and ineffective image utilization. In contrast, a pipeline framework first identifies aspects through MATE (Multimodal Aspect Term Extraction) and then aligns these aspects with image patches for sentiment classification (MASC: Multimodal Aspect-Oriented Sentiment Classification). This method is better suited for multimodal scenarios where effective image use is crucial. We present three key observations: (a) MATE and MASC have different feature requirements, with MATE focusing on token-level features and MASC on sequence-level features; (b) the aspect identified by MATE is crucial for effective image utilization; and (c) images play a trivial role in previous MABSA methods due to high noise. Based on these observations, we propose a pipeline framework that first predicts the aspect and then uses translation-based alignment (TBA) to enhance multimodal semantic consistency for better image utilization. Our method achieves state-of-the-art (SOTA) performance on widely used MABSA datasets Twitter-15 and Twitter-17. This demonstrates the effectiveness of the pipeline approach and its potential to provide valuable insights for future MABSA research. For reproducibility, the code and checkpoint will be released.
YOLOOC: YOLO-based Open-Class Incremental Object Detection with Novel Class Discovery
Mar 30, 2024
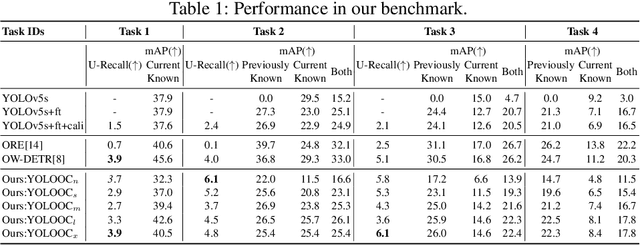
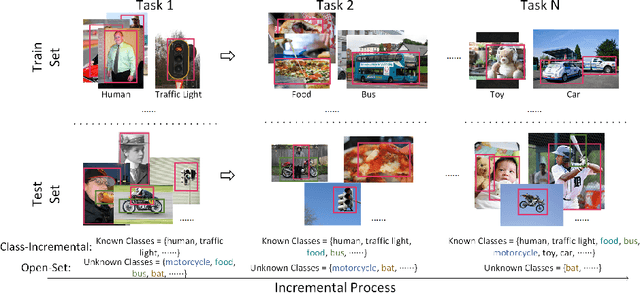
Because of its use in practice, open-world object detection (OWOD) has gotten a lot of attention recently. The challenge is how can a model detect novel classes and then incrementally learn them without forgetting previously known classes. Previous approaches hinge on strongly-supervised or weakly-supervised novel-class data for novel-class detection, which may not apply to real applications. We construct a new benchmark that novel classes are only encountered at the inference stage. And we propose a new OWOD detector YOLOOC, based on the YOLO architecture yet for the Open-Class setup. We introduce label smoothing to prevent the detector from over-confidently mapping novel classes to known classes and to discover novel classes. Extensive experiments conducted on our more realistic setup demonstrate the effectiveness of our method for discovering novel classes in our new benchmark.
Metamorpheus: Interactive, Affective, and Creative Dream Narration Through Metaphorical Visual Storytelling
Mar 01, 2024



Human emotions are essentially molded by lived experiences, from which we construct personalised meaning. The engagement in such meaning-making process has been practiced as an intervention in various psychotherapies to promote wellness. Nevertheless, to support recollecting and recounting lived experiences in everyday life remains under explored in HCI. It also remains unknown how technologies such as generative AI models can facilitate the meaning making process, and ultimately support affective mindfulness. In this paper we present Metamorpheus, an affective interface that engages users in a creative visual storytelling of emotional experiences during dreams. Metamorpheus arranges the storyline based on a dream's emotional arc, and provokes self-reflection through the creation of metaphorical images and text depictions. The system provides metaphor suggestions, and generates visual metaphors and text depictions using generative AI models, while users can apply generations to recolour and re-arrange the interface to be visually affective. Our experience-centred evaluation manifests that, by interacting with Metamorpheus, users can recall their dreams in vivid detail, through which they relive and reflect upon their experiences in a meaningful way.