 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyleGallery: Training-free and Semantic-aware Personalized Style Transfer from Arbitrary Image References
Mar 12, 2026Despite the advancements in diffusion-based image style transfer, existing methods are commonly limited by 1) semantic gap: the style reference could miss proper content semantics, causing uncontrollable stylization; 2) reliance on extra constraints (e.g., semantic masks) restricting applicability; 3) rigid feature associations lacking adaptive global-local alignment, failing to balance fine-grained stylization and global content preservation. These limitations, particularly the inability to flexibly leverage style inputs, fundamentally restrict style transfer in terms of personalization, accuracy, and adaptability. To address these, we propose StyleGallery, a training-free and semantic-aware framework that supports arbitrary reference images as input and enables effective personalized customization. It comprises three core stages: semantic region segmentation (adaptive clustering on latent diffusion features to divide regions without extra inputs); clustered region matching (block filtering on extracted features for precise alignment); and style transfer optimization (energy function-guided diffusion sampling with regional style loss to optimize stylization). Experiments on our introduced benchmark demonstrate that StyleGallery outperforms state-of-the-art methods in content structure preservation, regional stylization, interpretability, and personalized customization, particularly when leveraging multiple style references.
HOCA-Bench: Beyond Semantic Perception to Predictive World Modeling via Hegelian Ontological-Causal Anomalies
Feb 23, 2026Video-LLMs have improved steadily on semantic perception, but they still fall short on predictive world modeling, which is central to physically grounded intelligence. We introduce HOCA-Bench, a benchmark that frames physical anomalies through a Hegelian lens. HOCA-Bench separates anomalies into two types: ontological anomalies, where an entity violates its own definition or persistence, and causal anomalies, where interactions violate physical relations. Using state-of-the-art generative video models as adversarial simulators, we build a testbed of 1,439 videos (3,470 QA pairs). Evaluations on 17 Video-LLMs show a clear cognitive lag: models often identify static ontological violations (e.g., shape mutations) but struggle with causal mechanisms (e.g., gravity or friction), with performance dropping by more than 20% on causal tasks. System-2 "Thinking" modes improve reasoning, but they do not close the gap, suggesting that current architectures recognize visual patterns more readily than they apply basic physical laws.
RAG-Adapter: A Plug-and-Play RAG-enhanced Framework for Long Video Understanding
Mar 11, 2025
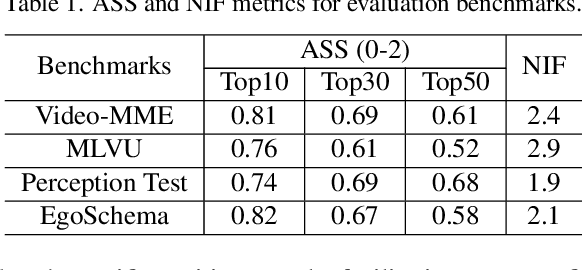
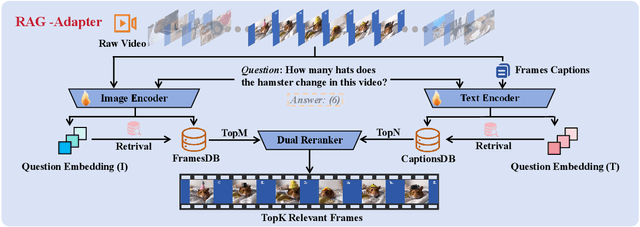
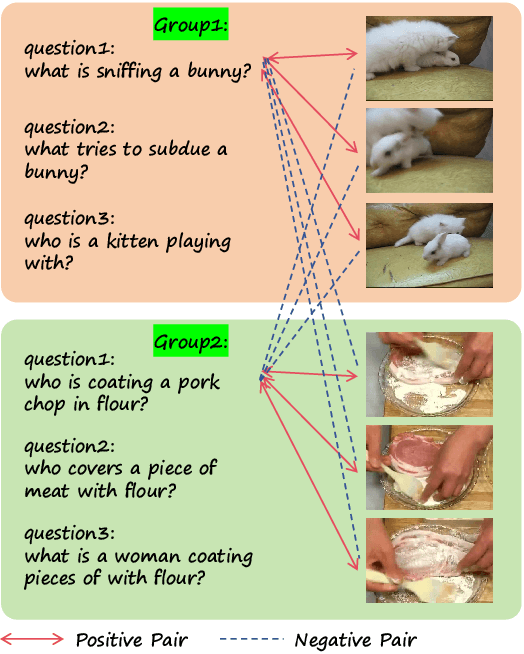
Multi-modal Large Language Models (MLLMs) capable of video understanding are advancing rapidly. To effectively assess their video comprehension capabilities, long video understanding benchmarks, such as Video-MME and MLVU, are proposed. However, these benchmarks directly use uniform frame sampling for testing, which results in significant information loss and affects the accuracy of the evaluations in reflecting the true abilities of MLLMs. To address this, we propose RAG-Adapter, a plug-and-play framework that reduces information loss during testing by sampling frames most relevant to the given question. Additionally, we introduce a Grouped-supervised Contrastive Learning (GCL) method to further enhance sampling effectiveness of RAG-Adapter through fine-tuning on our constructed MMAT dataset. Finally, we test numerous baseline MLLMs on various video understanding benchmarks, finding that RAG-Adapter sampling consistently outperforms uniform sampling (e.g., Accuracy of GPT-4o increases by 9.3 percent on Video-MME), providing a more accurate testing method for long video benchmarks.
ALLVB: All-in-One Long Video Understanding Benchmark
Mar 10, 2025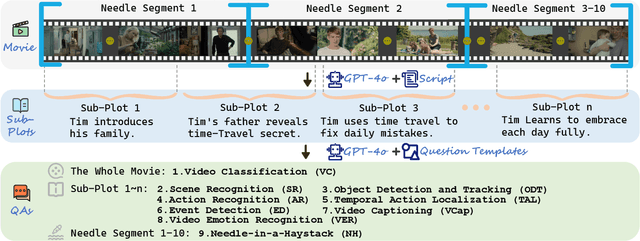
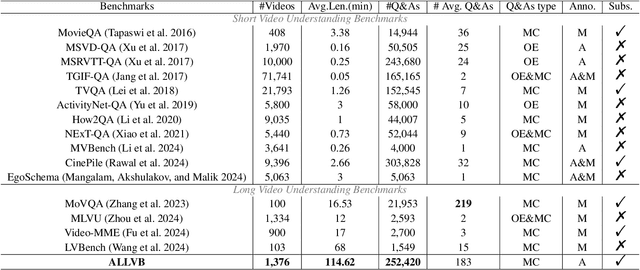
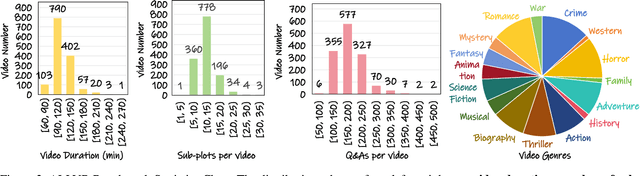
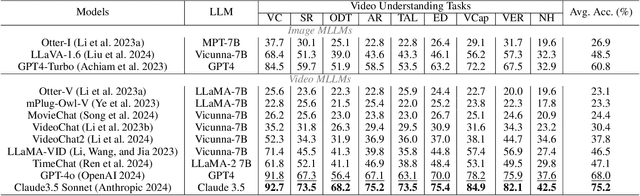
From image to video understanding, the capabilities of Multi-modal LLMs (MLLMs) are increasingly powerful. However, most existing video understanding benchmarks are relatively short, which makes them inadequate for effectively evaluating the long-sequence modeling capabilities of MLLMs. This highlights the urgent need for a comprehensive and integrated long video understanding benchmark to assess the ability of MLLMs thoroughly. To this end, we propose ALLVB (ALL-in-One Long Video Understanding Benchmark). ALLVB's main contributions include: 1) It integrates 9 major video understanding tasks. These tasks are converted into video QA formats, allowing a single benchmark to evaluate 9 different video understanding capabilities of MLLMs, highlighting the versatility, comprehensiveness, and challenging nature of ALLVB. 2) A fully automated annotation pipeline using GPT-4o is designed, requiring only human quality control, which facilitates the maintenance and expansion of the benchmark. 3) It contains 1,376 videos across 16 categories, averaging nearly 2 hours each, with a total of 252k QAs. To the best of our knowledge, it is the largest long video understanding benchmark in terms of the number of videos, average duration, and number of QAs. We have tested various mainstream MLLMs on ALLVB, and the results indicate that even the most advanced commercial models have significant room for improvement. This reflects the benchmark's challenging nature and demonstrates the substantial potential for development in long video understanding.
ROICtrl: Boosting Instance Control for Visual Generation
Nov 27, 2024



Natural language often struggles to accurately associate positional and attribute information with multiple instances, which limits current text-based visual generation models to simpler compositions featuring only a few dominant instances. To address this limitation, this work enhances diffusion models by introducing regional instance control, where each instance is governed by a bounding box paired with a free-form caption. Previous methods in this area typically rely on implicit position encoding or explicit attention masks to separate regions of interest (ROIs), resulting in either inaccurate coordinate injection or large computational overhead. Inspired by ROI-Align in object detection, we introduce a complementary operation called ROI-Unpool. Together, ROI-Align and ROI-Unpool enable explicit, efficient, and accurate ROI manipulation on high-resolution feature maps for visual generation. Building on ROI-Unpool, we propose ROICtrl, an adapter for pretrained diffusion models that enables precise regional instance control. ROICtrl is compatible with community-finetuned diffusion models, as well as with existing spatial-based add-ons (\eg, ControlNet, T2I-Adapter) and embedding-based add-ons (\eg, IP-Adapter, ED-LoRA), extending their applications to multi-instance generation. Experiments show that ROICtrl achieves superior performance in regional instance control while significantly reducing computational costs.
FedStyle: Style-Based Federated Learning Crowdsourcing Framework for Art Commissions
Apr 25, 2024



The unique artistic style is crucial to artists' occupational competitiveness, yet prevailing Art Commission Platforms rarely support style-based retrieval. Meanwhile, the fast-growing generative AI techniques aggravate artists' concerns about releasing personal artworks to public platforms. To achieve artistic style-based retrieval without exposing personal artworks, we propose FedStyle, a style-based federated learning crowdsourcing framework. It allows artists to train local style models and share model parameters rather than artworks for collaboration. However, most artists possess a unique artistic style, resulting in severe model drift among them. FedStyle addresses such extreme data heterogeneity by having artists learn their abstract style representations and align with the server, rather than merely aggregating model parameters lacking semantics. Besides, we introduce contrastive learning to meticulously construct the style representation space, pulling artworks with similar styles closer and keeping different ones apart in the embedding space. Extensive experiments on the proposed datasets demonstrate the superiority of FedStyle.
Learning Cross-hand Policies for High-DOF Reaching and Grasping
Apr 14, 2024
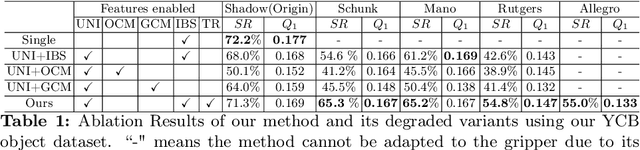


Reaching-and-grasping is a fundamental skill for robotic manipulation, but existing methods usually train models on a specific gripper and cannot be reused on another gripper without retraining. In this paper, we propose a novel method that can learn a unified policy model that can be easily transferred to different dexterous grippers. Our method consists of two stages: a gripper-agnostic policy model that predicts the displacements of predefined key points on the gripper, and a gripper specific adaptation model that translates these displacements into adjustments for controlling the grippers' joints. The gripper state and interactions with objects are captured at the finger level using robust geometric representations, integrated with a transformer-based network to address variations in gripper morphology and geometry. In the experimental part, we evaluate our method on several dexterous grippers and objects of diverse shapes, and the result shows that our method significantly outperforms the baseline methods. Pioneering the transfer of grasp policies across different dexterous grippers, our method effectively demonstrates its potential for learning generalizable and transferable manipulation skills for various robotic hands
DiffusionEdge: Diffusion Probabilistic Model for Crisp Edge Detection
Jan 09, 2024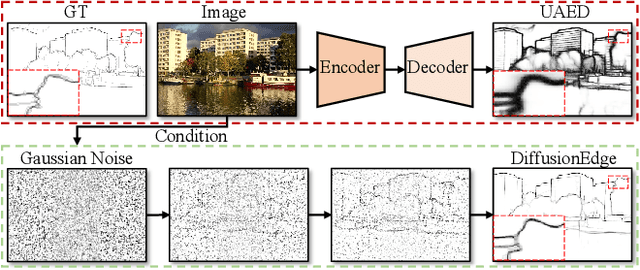

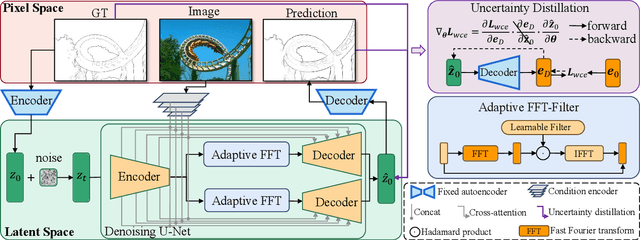
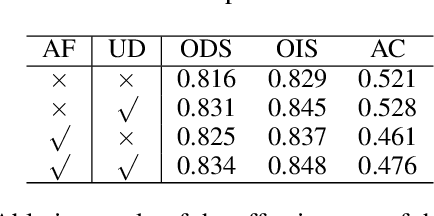
Limited by the encoder-decoder architecture, learning-based edge detectors usually have difficulty predicting edge maps that satisfy both correctness and crispness. With the recent success of the diffusion probabilistic model (DPM), we found it is especially suitable for accurate and crisp edge detection since the denoising process is directly applied to the original image size. Therefore, we propose the first diffusion model for the task of general edge detection, which we call DiffusionEdge. To avoid expensive computational resources while retaining the final performance, we apply DPM in the latent space and enable the classic cross-entropy loss which is uncertainty-aware in pixel level to directly optimize the parameters in latent space in a distillation manner. We also adopt a decoupled architecture to speed up the denoising process and propose a corresponding adaptive Fourier filter to adjust the latent features of specific frequencies. With all the technical designs, DiffusionEdge can be stably trained with limited resources, predicting crisp and accurate edge maps with much fewer augmentation strategies. Extensive experiments on four edge detection benchmarks demonstrate the superiority of DiffusionEdge both in correctness and crispness. On the NYUDv2 dataset, compared to the second best, we increase the ODS, OIS (without post-processing) and AC by 30.2%, 28.1% and 65.1%, respectively. Code: https://github.com/GuHuangAI/DiffusionEdge.
Delving into Crispness: Guided Label Refinement for Crisp Edge Detection
Jun 27, 2023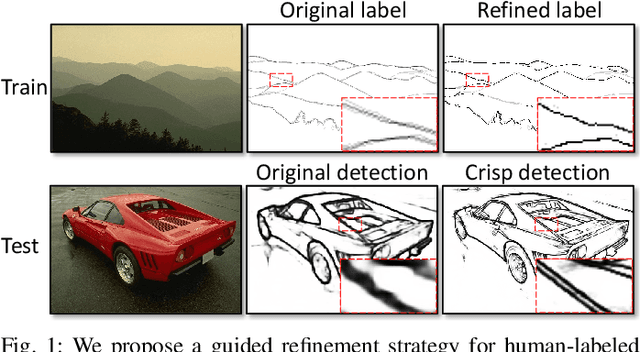
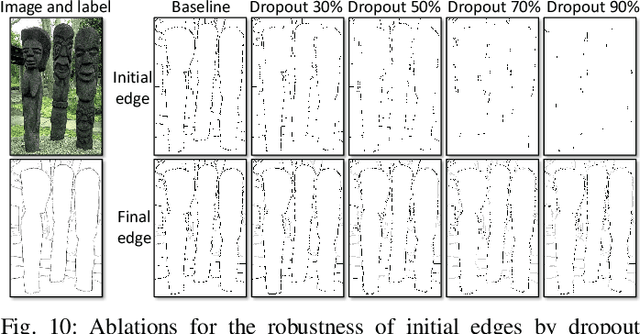


Learning-based edge detection usually suffers from predicting thick edges. Through extensive quantitative study with a new edge crispness measure, we find that noisy human-labeled edges are the main cause of thick predictions. Based on this observation, we advocate that more attention should be paid on label quality than on model design to achieve crisp edge detection. To this end, we propose an effective Canny-guided refinement of human-labeled edges whose result can be used to train crisp edge detectors. Essentially, it seeks for a subset of over-detected Canny edges that best align human labels. We show that several existing edge detectors can be turned into a crisp edge detector through training on our refined edge maps. Experiments demonstrate that deep models trained with refined edges achieve significant performance boost of crispness from 17.4% to 30.6%. With the PiDiNet backbone, our method improves ODS and OIS by 12.2% and 12.6% on the Multicue dataset, respectively, without relying on non-maximal suppression. We further conduct experiments and show the superiority of our crisp edge detection for optical flow estimation and image segmentation.
NEF: Neural Edge Fields for 3D Parametric Curve Reconstruction from Multi-view Images
Mar 16, 2023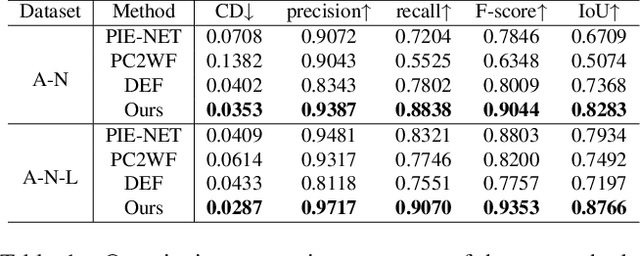
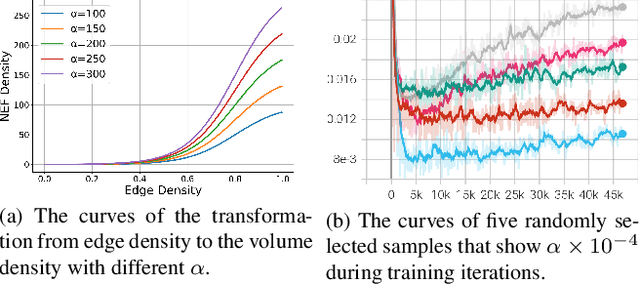
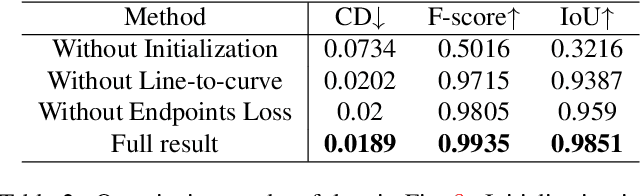
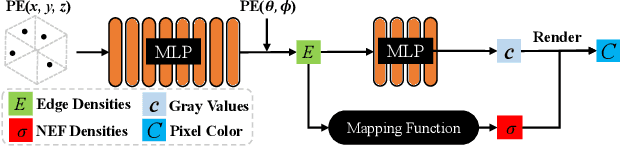
We study the problem of reconstructing 3D feature curves of an object from a set of calibrated multi-view images. To do so, we learn a neural implicit field representing the density distribution of 3D edges which we refer to as Neural Edge Field (NEF). Inspired by NeRF, NEF is optimized with a view-based rendering loss where a 2D edge map is rendered at a given view and is compared to the ground-truth edge map extracted from the image of that view. The rendering-based differentiable optimization of NEF fully exploits 2D edge detection, without needing a supervision of 3D edges, a 3D geometric operator or cross-view edge correspondence. Several technical designs are devised to ensure learning a range-limited and view-independent NEF for robust edge extraction. The final parametric 3D curves are extracted from NEF with an iterative optimization method. On our benchmark with synthetic data, we demonstrate that NEF outperforms existing state-of-the-art methods on all metrics. Project page: https://yunfan1202.github.io/NEF/.