 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-enhanced Scene Graph Learning for Household Rearrangement
Aug 22, 2024



The household rearrangement task involves spotting misplaced objects in a scene and accommodate them with proper places. It depends both on common-sense knowledge on the objective side and human user preference on the subjective side. In achieving such task, we propose to mine object functionality with user preference alignment directly from the scene itself, without relying on human intervention. To do so, we work with scene graph representation and propose LLM-enhanced scene graph learning which transforms the input scene graph into an affordance-enhanced graph (AEG) with information-enhanced nodes and newly discovered edges (relations). In AEG, the nodes corresponding to the receptacle objects are augmented with context-induced affordance which encodes what kind of carriable objects can be placed on it. New edges are discovered with newly discovered non-local relations. With AEG, we perform task planning for scene rearrangement by detecting misplaced carriables and determining a proper placement for each of them. We test our method by implementing a tiding robot in simulator and perform evaluation on a new benchmark we build. Extensive evaluations demonstrate that our method achieves state-of-the-art performance on misplacement detection and the following rearrangement planning.
Learning Cross-hand Policies for High-DOF Reaching and Grasping
Apr 14, 2024


Reaching-and-grasping is a fundamental skill for robotic manipulation, but existing methods usually train models on a specific gripper and cannot be reused on another gripper without retraining. In this paper, we propose a novel method that can learn a unified policy model that can be easily transferred to different dexterous grippers. Our method consists of two stages: a gripper-agnostic policy model that predicts the displacements of predefined key points on the gripper, and a gripper specific adaptation model that translates these displacements into adjustments for controlling the grippers' joints. The gripper state and interactions with objects are captured at the finger level using robust geometric representations, integrated with a transformer-based network to address variations in gripper morphology and geometry. In the experimental part, we evaluate our method on several dexterous grippers and objects of diverse shapes, and the result shows that our method significantly outperforms the baseline methods. Pioneering the transfer of grasp policies across different dexterous grippers, our method effectively demonstrates its potential for learning generalizable and transferable manipulation skills for various robotic hands
Learning Dual-arm Object Rearrangement for Cartesian Robots
Feb 21, 2024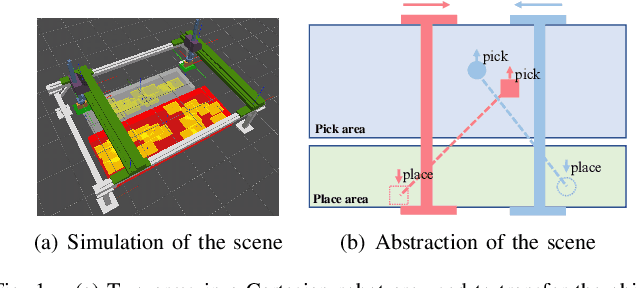
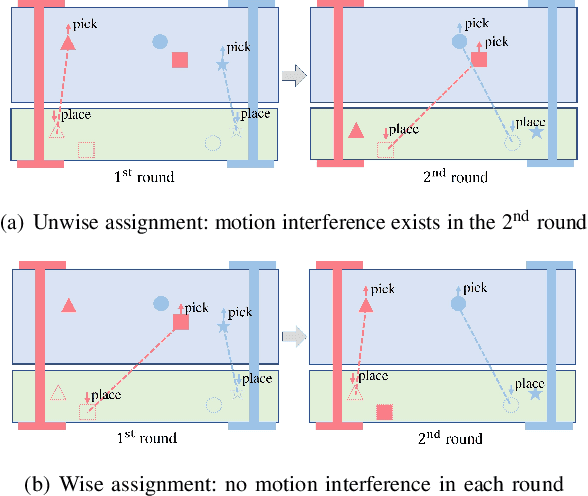
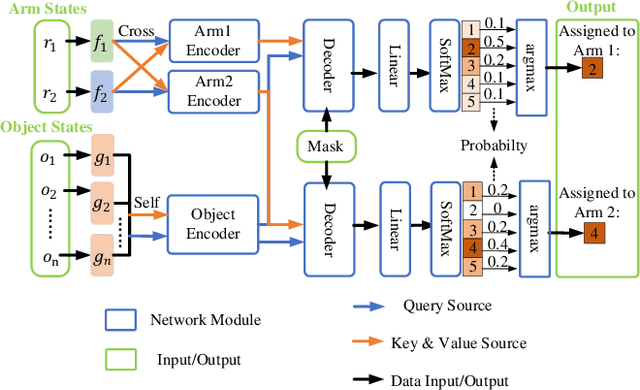
This work focuses on the dual-arm object rearrangement problem abstracted from a realistic industrial scenario of Cartesian robots. The goal of this problem is to transfer all the objects from sources to targets with the minimum total completion time. To achieve the goal, the core idea is to develop an effective object-to-arm task assignment strategy for minimizing the cumulative task execution time and maximizing the dual-arm cooperation efficiency. One of the difficulties in the task assignment is the scalability problem. As the number of objects increases, the computation time of traditional offline-search-based methods grows strongly for computational complexity. Encouraged by the adaptability of reinforcement learning (RL) in long-sequence task decisions, we propose an online task assignment decision method based on RL, and the computation time of our method only increases linearly with the number of objects. Further, we design an attention-based network to model the dependencies between the input states during the whole task execution process to help find the most reasonable object-to-arm correspondence in each task assignment round. In the experimental part, we adapt some search-based methods to this specific setting and compare our method with them. Experimental result shows that our approach achieves outperformance over search-based methods in total execution time and computational efficiency, and also verifies the generalization of our method to different numbers of objects. In addition, we show the effectiveness of our method deployed on the real robot in the supplementary video.
Online 3D Bin Packing with Constrained Deep Reinforcement Learning
Jun 26, 2020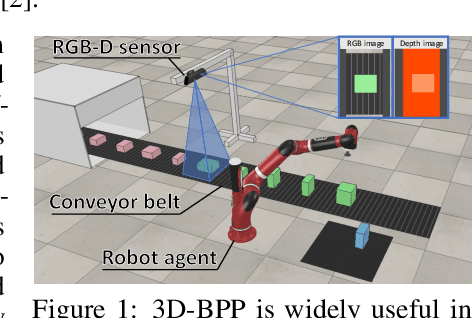

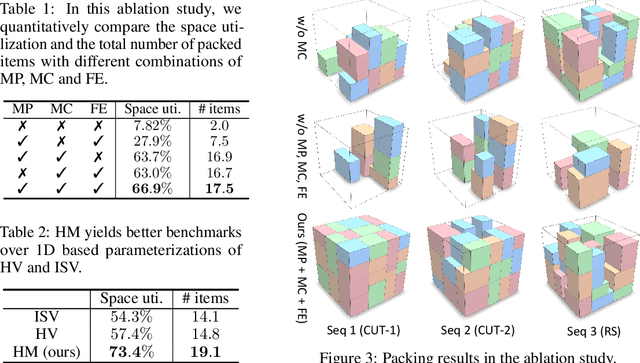
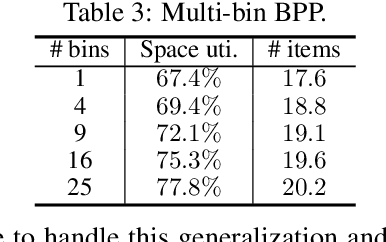
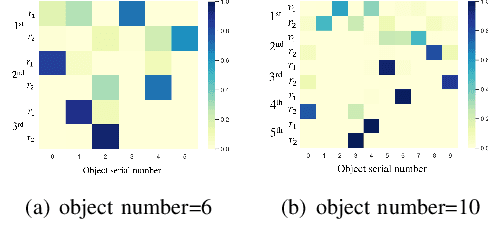
We solve a challenging yet practically useful variant of 3D Bin Packing Problem (3D-BPP). In our problem, the agent has limited information about the items to be packed into the bin, and an item must be packed immediately after its arrival without buffering or readjusting. The item's placement also subjects to the constraints of collision avoidance and physical stability. We formulate this online 3D-BPP as a constrained Markov decision process. To solve the problem, we propose an effective and easy-to-implement constrained deep reinforcement learning (DRL) method under the actor-critic framework. In particular, we introduce a feasibility predictor to predict the feasibility mask for the placement actions and use it to modulate the action probabilities output by the actor during training. Such supervisions and transformations to DRL facilitate the agent to learn feasible policies efficiently. Our method can also be generalized e.g., with the ability to handle lookahead or items with different orientations. We have conducted extensive evaluation showing that the learned policy significantly outperforms the state-of-the-art methods. A user study suggests that our method attains a human-level performance.