 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Faceted Continual Knowledge Graph Embedding for Semantic-Aware Link Prediction
Apr 13, 2026Continual Knowledge Graph Embedding (CKGE) aims to continually learn embeddings for new knowledge, i.e., entities and relations, while retaining previously acquired knowledge. Most existing CKGE methods mitigate catastrophic forgetting via regularization or replaying old knowledge. They conflate new and old knowledge of an entity within the same embedding space to seek a balance between them. However, entities inherently exhibit multi-faceted semantics that evolve dynamically as their relational contexts change over time. A shared embedding fails to capture and distinguish these temporal semantic variations, degrading lifelong link prediction accuracy across snapshots. To address this, we propose a Multi-Faceted CKGE framework (MF-CKGE) for semantic-aware link prediction. During offline learning, MF-CKGE separates temporal old and new knowledge into distinct embedding spaces to prevent knowledge entanglement and employs semantic decoupling to reduce semantic redundancy, thereby improving space efficiency. During online inference, MF-CKGE adaptively identifies semantically query-relevant entity embeddings by quantifying their semantic importance, reducing interference from query-irrelevant noise. Experiments on eight datasets show that MF-CKGE achieves an average (maximum) improvement of 1.7% (2.7%) and 1.4% (3.8%) in MRR and Hits@10, respectively, over the best baseline. Our source code and datasets are available at: https://anonymous.4open.science/r/MF-CKGE-04E5.
SyncTrack: Rhythmic Stability and Synchronization in Multi-Track Music Generation
Mar 01, 2026Multi-track music generation has garnered significant research interest due to its precise mixing and remixing capabilities. However, existing models often overlook essential attributes such as rhythmic stability and synchronization, leading to a focus on differences between tracks rather than their inherent properties. In this paper, we introduce SyncTrack, a synchronous multi-track waveform music generation model designed to capture the unique characteristics of multi-track music. SyncTrack features a novel architecture that includes track-shared modules to establish a common rhythm across all tracks and track-specific modules to accommodate diverse timbres and pitch ranges. Each track-shared module employs two cross-track attention mechanisms to synchronize rhythmic information, while each track-specific module utilizes learnable instrument priors to better represent timbre and other unique features. Additionally, we enhance the evaluation of multi-track music quality by introducing rhythmic consistency through three novel metrics: Inner-track Rhythmic Stability (IRS), Cross-track Beat Synchronization (CBS), and Cross-track Beat Dispersion (CBD). Experiments demonstrate that SyncTrack significantly improves the multi-track music quality by enhancing rhythmic consistency.
Rethinking Jailbreak Detection of Large Vision Language Models with Representational Contrastive Scoring
Dec 12, 2025



Large Vision-Language Models (LVLMs) are vulnerable to a growing array of multimodal jailbreak attacks, necessitating defenses that are both generalizable to novel threats and efficient for practical deployment. Many current strategies fall short, either targeting specific attack patterns, which limits generalization, or imposing high computational overhead. While lightweight anomaly-detection methods offer a promising direction, we find that their common one-class design tends to confuse novel benign inputs with malicious ones, leading to unreliable over-rejection. To address this, we propose Representational Contrastive Scoring (RCS), a framework built on a key insight: the most potent safety signals reside within the LVLM's own internal representations. Our approach inspects the internal geometry of these representations, learning a lightweight projection to maximally separate benign and malicious inputs in safety-critical layers. This enables a simple yet powerful contrastive score that differentiates true malicious intent from mere novelty. Our instantiations, MCD (Mahalanobis Contrastive Detection) and KCD (K-nearest Contrastive Detection), achieve state-of-the-art performance on a challenging evaluation protocol designed to test generalization to unseen attack types. This work demonstrates that effective jailbreak detection can be achieved by applying simple, interpretable statistical methods to the appropriate internal representations, offering a practical path towards safer LVLM deployment. Our code is available on Github https://github.com/sarendis56/Jailbreak_Detection_RCS.
MaskPro: Linear-Space Probabilistic Learning for Strict (N:M)-Sparsity on Large Language Models
Jun 15, 2025The rapid scaling of large language models (LLMs) has made inference efficiency a primary bottleneck in the practical deployment. To address this, semi-structured sparsity offers a promising solution by strategically retaining $N$ elements out of every $M$ weights, thereby enabling hardware-friendly acceleration and reduced memory. However, existing (N:M)-compatible approaches typically fall into two categories: rule-based layerwise greedy search, which suffers from considerable errors, and gradient-driven combinatorial learning, which incurs prohibitive training costs. To tackle these challenges, we propose a novel linear-space probabilistic framework named MaskPro, which aims to learn a prior categorical distribution for every $M$ consecutive weights and subsequently leverages this distribution to generate the (N:M)-sparsity throughout an $N$-way sampling without replacement. Furthermore, to mitigate the training instability induced by the high variance of policy gradients in the super large combinatorial space, we propose a novel update method by introducing a moving average tracker of loss residuals instead of vanilla loss. Finally, we conduct comprehensive theoretical analysis and extensive experiments to validate the superior performance of MaskPro, as well as its excellent scalability in memory efficiency and exceptional robustness to data samples. Our code is available at https://github.com/woodenchild95/Maskpro.git.
PIN-WM: Learning Physics-INformed World Models for Non-Prehensile Manipulation
Apr 23, 2025While non-prehensile manipulation (e.g., controlled pushing/poking) constitutes a foundational robotic skill, its learning remains challenging due to the high sensitivity to complex physical interactions involving friction and restitution. To achieve robust policy learning and generalization, we opt to learn a world model of the 3D rigid body dynamics involved in non-prehensile manipulations and use it for model-based reinforcement learning. We propose PIN-WM, a Physics-INformed World Model that enables efficient end-to-end identification of a 3D rigid body dynamical system from visual observations. Adopting differentiable physics simulation, PIN-WM can be learned with only few-shot and task-agnostic physical interaction trajectories. Further, PIN-WM is learned with observational loss induced by Gaussian Splatting without needing state estimation. To bridge Sim2Real gaps, we turn the learned PIN-WM into a group of Digital Cousins via physics-aware randomizations which perturb physics and rendering parameters to generate diverse and meaningful variations of the PIN-WM. Extensive evaluations on both simulation and real-world tests demonstrate that PIN-WM, enhanced with physics-aware digital cousins, facilitates learning robust non-prehensile manipulation skills with Sim2Real transfer, surpassing the Real2Sim2Real state-of-the-arts.
A Framework for Uplink ISAC Receiver Designs: Performance Analysis and Algorithm Development
Mar 04, 2025



Uplink integrated sensing and communication (ISAC) systems have recently emerged as a promising research direction, enabling simultaneous uplink signal detection and target sensing. In this paper, we propose flexible projection (FP)-type receivers that unify the projection-type receivers and the successive interference cancellation (SIC)-type receivers by using a flexible tradeoff factor to adapt to dynamically changing uplink ISAC scenarios. The FP-type receivers address the joint signal detection and target response estimation problem through two coordinated phases: 1) Communication signal detection using a reconstructed signal whose composition is controlled by the tradeoff factor, followed by 2) Target response estimation performed through subtraction of the detected communication signal from the received signal. With adjustable tradeoff factors, the FP-type receivers can balance the enhancement of the signal-to-interference-plus-noise ratio (SINR) with the reduction of correlation in the reconstructed signal for communication signal detection. The pairwise error probabilities (PEPs) are analyzed for both maximum likelihood (ML) and zero-forcing (ZF) detectors, revealing that the optimal tradeoff factor should be determined based on the adopted detection algorithm and the relative power of the sensing and communication (S&C) signal. A homotopy optimization framework is first applied for the FP-type receivers with a fixed trade-off factor. This framework is then extended to develop dynamic FP (DFP)-type receivers, which iteratively adjust the trade-off factor for improved algorithm performance and environmental adaptability. Subsequently, two extensions are explored to further enhance the receivers' performance: parallel DFP (PDFP)-type receivers and a block-structured receiver design. Finally, the effectiveness of the proposed receiver designs is verified via simulations.
Representing Long Volumetric Video with Temporal Gaussian Hierarchy
Dec 12, 2024

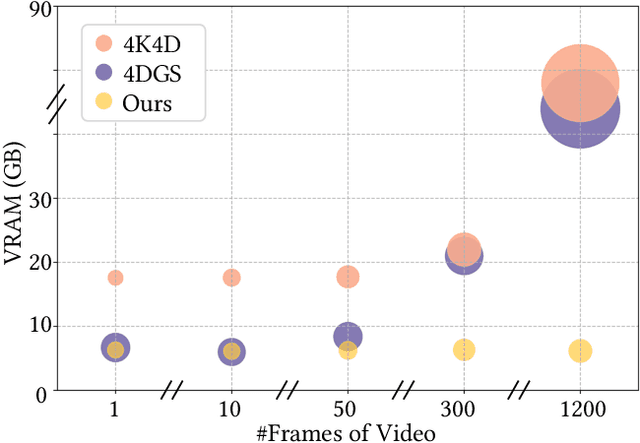
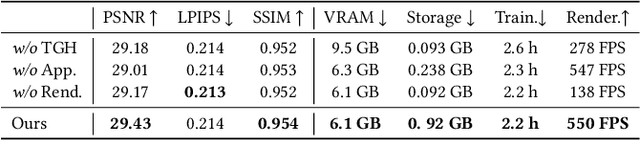
This paper aims to address the challenge of reconstructing long volumetric videos from multi-view RGB videos. Recent dynamic view synthesis methods leverage powerful 4D representations, like feature grids or point cloud sequences, to achieve high-quality rendering results. However, they are typically limited to short (1~2s) video clips and often suffer from large memory footprints when dealing with longer videos. To solve this issue, we propose a novel 4D representation, named Temporal Gaussian Hierarchy, to compactly model long volumetric videos. Our key observation is that there are generally various degrees of temporal redundancy in dynamic scenes, which consist of areas changing at different speeds. Motivated by this, our approach builds a multi-level hierarchy of 4D Gaussian primitives, where each level separately describes scene regions with different degrees of content change, and adaptively shares Gaussian primitives to represent unchanged scene content over different temporal segments, thus effectively reducing the number of Gaussian primitives. In addition, the tree-like structure of the Gaussian hierarchy allows us to efficiently represent the scene at a particular moment with a subset of Gaussian primitives, leading to nearly constant GPU memory usage during the training or rendering regardless of the video length. Extensive experimental results demonstrate the superiority of our method over alternative methods in terms of training cost, rendering speed, and storage usage. To our knowledge, this work is the first approach capable of efficiently handling minutes of volumetric video data while maintaining state-of-the-art rendering quality. Our project page is available at: https://zju3dv.github.io/longvolcap.
Addressing the Mutual Interference in Uplink ISAC Receivers: A Projection Method
Aug 29, 2024


Dual function radar and communication (DFRC) is a promising research direction within integrated sensing and communication (ISAC), improving hardware and spectrum efficiency by merging sensing and communication (S&C) functionalities into a shared platform. However, the DFRC receiver (DFRC-R) is tasked with both uplink communication signal detection and simultaneously target-related parameter estimation from the echoes, leading to issues with mutual interference. In this paper, a projection-based scheme is proposed to equivalently transform the joint signal detection and target estimation problem into a joint signal detection process across multiple snapshots. Compared with conventional successive interference cancellation (SIC) schemes, our proposed approach achieves a higher signal-to-noise ratio (SNR), and a higher ergodic rate when the radar signal is non-negligible. Nonetheless, it introduces an ill-conditioned signal detection problem, which is addressed using a non-linear detector. By jointly processing an increased number of snapshots, the proposed scheme can achieve high S&C performance simultaneously.
LLM-enhanced Scene Graph Learning for Household Rearrangement
Aug 22, 2024



The household rearrangement task involves spotting misplaced objects in a scene and accommodate them with proper places. It depends both on common-sense knowledge on the objective side and human user preference on the subjective side. In achieving such task, we propose to mine object functionality with user preference alignment directly from the scene itself, without relying on human intervention. To do so, we work with scene graph representation and propose LLM-enhanced scene graph learning which transforms the input scene graph into an affordance-enhanced graph (AEG) with information-enhanced nodes and newly discovered edges (relations). In AEG, the nodes corresponding to the receptacle objects are augmented with context-induced affordance which encodes what kind of carriable objects can be placed on it. New edges are discovered with newly discovered non-local relations. With AEG, we perform task planning for scene rearrangement by detecting misplaced carriables and determining a proper placement for each of them. We test our method by implementing a tiding robot in simulator and perform evaluation on a new benchmark we build. Extensive evaluations demonstrate that our method achieves state-of-the-art performance on misplacement detection and the following rearrangement planning.
Learning Instance-Aware Correspondences for Robust Multi-Instance Point Cloud Registration in Cluttered Scenes
Apr 06, 2024Multi-instance point cloud registration estimates the poses of multiple instances of a model point cloud in a scene point cloud. Extracting accurate point correspondence is to the center of the problem. Existing approaches usually treat the scene point cloud as a whole, overlooking the separation of instances. Therefore, point features could be easily polluted by other points from the background or different instances, leading to inaccurate correspondences oblivious to separate instances, especially in cluttered scenes. In this work, we propose MIRETR, Multi-Instance REgistration TRansformer, a coarse-to-fine approach to the extraction of instance-aware correspondences. At the coarse level, it jointly learns instance-aware superpoint features and predicts per-instance masks. With instance masks, the influence from outside of the instance being concerned is minimized, such that highly reliable superpoint correspondences can be extracted. The superpoint correspondences are then extended to instance candidates at the fine level according to the instance masks. At last, an efficient candidate selection and refinement algorithm is devised to obtain the final registrations. Extensive experiments on three public benchmarks demonstrate the efficacy of our approach. In particular, MIRETR outperforms the state of the arts by 16.6 points on F1 score on the challenging ROBI benchmark. Code and models are available at https://github.com/zhiyuanYU134/MIRETR.