 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepMath-Creative: A Benchmark for Evaluating Mathematical Creativity of Large Language Models
May 13, 2025

To advance the mathematical proficiency of large language models (LLMs), the DeepMath team has launched an open-source initiative aimed at developing an open mathematical LLM and systematically evaluating its mathematical creativity. This paper represents the initial contribution of this initiative. While recent developments in mathematical LLMs have predominantly emphasized reasoning skills, as evidenced by benchmarks on elementary to undergraduate-level mathematical tasks, the creative capabilities of these models have received comparatively little attention, and evaluation datasets remain scarce. To address this gap, we propose an evaluation criteria for mathematical creativity and introduce DeepMath-Creative, a novel, high-quality benchmark comprising constructive problems across algebra, geometry, analysis, and other domains. We conduct a systematic evaluation of mainstream LLMs' creative problem-solving abilities using this dataset. Experimental results show that even under lenient scoring criteria -- emphasizing core solution components and disregarding minor inaccuracies, such as small logical gaps, incomplete justifications, or redundant explanations -- the best-performing model, O3 Mini, achieves merely 70% accuracy, primarily on basic undergraduate-level constructive tasks. Performance declines sharply on more complex problems, with models failing to provide substantive strategies for open problems. These findings suggest that, although current LLMs display a degree of constructive proficiency on familiar and lower-difficulty problems, such performance is likely attributable to the recombination of memorized patterns rather than authentic creative insight or novel synthesis.
PIN-WM: Learning Physics-INformed World Models for Non-Prehensile Manipulation
Apr 23, 2025While non-prehensile manipulation (e.g., controlled pushing/poking) constitutes a foundational robotic skill, its learning remains challenging due to the high sensitivity to complex physical interactions involving friction and restitution. To achieve robust policy learning and generalization, we opt to learn a world model of the 3D rigid body dynamics involved in non-prehensile manipulations and use it for model-based reinforcement learning. We propose PIN-WM, a Physics-INformed World Model that enables efficient end-to-end identification of a 3D rigid body dynamical system from visual observations. Adopting differentiable physics simulation, PIN-WM can be learned with only few-shot and task-agnostic physical interaction trajectories. Further, PIN-WM is learned with observational loss induced by Gaussian Splatting without needing state estimation. To bridge Sim2Real gaps, we turn the learned PIN-WM into a group of Digital Cousins via physics-aware randomizations which perturb physics and rendering parameters to generate diverse and meaningful variations of the PIN-WM. Extensive evaluations on both simulation and real-world tests demonstrate that PIN-WM, enhanced with physics-aware digital cousins, facilitates learning robust non-prehensile manipulation skills with Sim2Real transfer, surpassing the Real2Sim2Real state-of-the-arts.
Mixture of Prompt Learning for Vision Language Models
Sep 18, 2024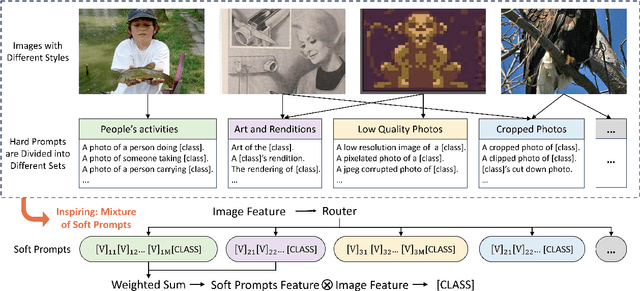
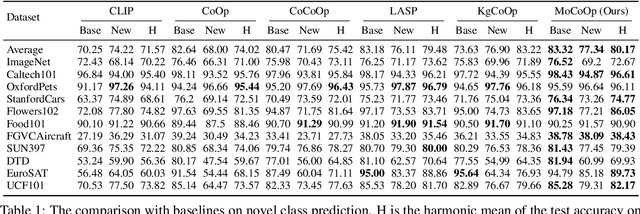
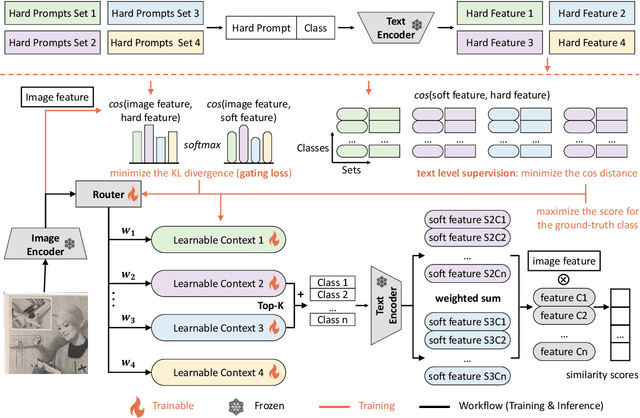
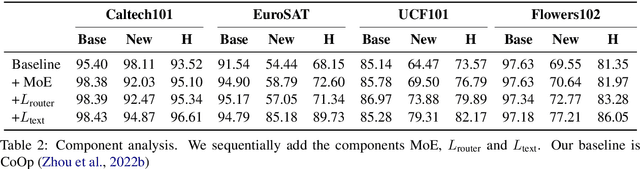
As powerful pre-trained vision-language models (VLMs) like CLIP gain prominence, numerous studies have attempted to combine VLMs for downstream tasks. Among these, prompt learning has been validated as an effective method for adapting to new tasks, which only requiring a small number of parameters. However, current prompt learning methods face two challenges: first, a single soft prompt struggles to capture the diverse styles and patterns within a dataset; second, fine-tuning soft prompts is prone to overfitting. To address these challenges, we propose a mixture of soft prompt learning method incorporating a routing module. This module is able to capture a dataset's varied styles and dynamically selects the most suitable prompts for each instance. Additionally, we introduce a novel gating mechanism to ensure the router selects prompts based on their similarity to hard prompt templates, which both retaining knowledge from hard prompts and improving selection accuracy. We also implement semantically grouped text-level supervision, initializing each soft prompt with the token embeddings of manually designed templates from its group and applied a contrastive loss between the resulted text feature and hard prompt encoded text feature. This supervision ensures that the text features derived from soft prompts remain close to those from their corresponding hard prompts, preserving initial knowledge and mitigating overfitting. Our method has been validated on 11 datasets, demonstrating evident improvements in few-shot learning, domain generalization, and base-to-new generalization scenarios compared to existing baselines. The code will be available at \url{https://anonymous.4open.science/r/mocoop-6387}
General-purpose Dataflow Model with Neuromorphic Primitives
Aug 02, 2024



Neuromorphic computing exhibits great potential to provide high-performance benefits in various applications beyond neural networks. However, a general-purpose program execution model that aligns with the features of neuromorphic computing is required to bridge the gap between program versatility and neuromorphic hardware efficiency. The dataflow model offers a potential solution, but it faces high graph complexity and incompatibility with neuromorphic hardware when dealing with control flow programs, which decreases the programmability and performance. Here, we present a dataflow model tailored for neuromorphic hardware, called neuromorphic dataflow, which provides a compact, concise, and neuromorphic-compatible program representation for control logic. The neuromorphic dataflow introduces "when" and "where" primitives, which restructure the view of control. The neuromorphic dataflow embeds these primitives in the dataflow schema with the plasticity inherited from the spiking algorithms. Our method enables the deployment of general-purpose programs on neuromorphic hardware with both programmability and plasticity, while fully utilizing the hardware's potential.
Subequivariant Reinforcement Learning in 3D Multi-Entity Physical Environments
Jul 17, 2024



Learning policies for multi-entity systems in 3D environments is far more complicated against single-entity scenarios, due to the exponential expansion of the global state space as the number of entities increases. One potential solution of alleviating the exponential complexity is dividing the global space into independent local views that are invariant to transformations including translations and rotations. To this end, this paper proposes Subequivariant Hierarchical Neural Networks (SHNN) to facilitate multi-entity policy learning. In particular, SHNN first dynamically decouples the global space into local entity-level graphs via task assignment. Second, it leverages subequivariant message passing over the local entity-level graphs to devise local reference frames, remarkably compressing the representation redundancy, particularly in gravity-affected environments. Furthermore, to overcome the limitations of existing benchmarks in capturing the subtleties of multi-entity systems under the Euclidean symmetry, we propose the Multi-entity Benchmark (MEBEN), a new suite of environments tailored for exploring a wide range of multi-entity reinforcement learning. Extensive experiments demonstrate significant advancements of SHNN on the proposed benchmarks compared to existing methods. Comprehensive ablations are conducted to verify the indispensability of task assignment and subequivariance.
MEDPNet: Achieving High-Precision Adaptive Registration for Complex Die Castings
Mar 15, 2024



Due to their complex spatial structure and diverse geometric features, achieving high-precision and robust point cloud registration for complex Die Castings has been a significant challenge in the die-casting industry. Existing point cloud registration methods primarily optimize network models using well-established high-quality datasets, often neglecting practical application in real scenarios. To address this gap, this paper proposes a high-precision adaptive registration method called Multiscale Efficient Deep Closest Point (MEDPNet) and introduces a die-casting point cloud dataset, DieCastCloud, specifically designed to tackle the challenges of point cloud registration in the die-casting industry. The MEDPNet method performs coarse die-casting point cloud data registration using the Efficient-DCP method, followed by precision registration using the Multiscale feature fusion dual-channel registration (MDR) method. We enhance the modeling capability and computational efficiency of the model by replacing the attention mechanism of the Transformer in DCP with Efficient Attention and implementing a collaborative scale mechanism through the combination of serial and parallel blocks. Additionally, we propose the MDR method, which utilizes multilayer perceptrons (MLP), Normal Distributions Transform (NDT), and Iterative Closest Point (ICP) to achieve learnable adaptive fusion, enabling high-precision, scalable, and noise-resistant global point cloud registration. Our proposed method demonstrates excellent performance compared to state-of-the-art geometric and learning-based registration methods when applied to complex die-casting point cloud data.
A unified Bayesian framework for interval hypothesis testing in clinical trials
Feb 21, 2024



The American Statistical Association (ASA) statement on statistical significance and P-values \cite{wasserstein2016asa} cautioned statisticians against making scientific decisions solely on the basis of traditional P-values. The statement delineated key issues with P-values, including a lack of transparency, an inability to quantify evidence in support of the null hypothesis, and an inability to measure the size of an effect or the importance of a result. In this article, we demonstrate that the interval null hypothesis framework (instead of the point null hypothesis framework), when used in tandem with Bayes factor-based tests, is instrumental in circumnavigating the key issues of P-values. Further, we note that specifying prior densities for Bayes factors is challenging and has been a reason for criticism of Bayesian hypothesis testing in existing literature. We address this by adapting Bayes factors directly based on common test statistics. We demonstrate, through numerical experiments and real data examples, that the proposed Bayesian interval hypothesis testing procedures can be calibrated to ensure frequentist error control while retaining their inherent interpretability. Finally, we illustrate the improved flexibility and applicability of the proposed methods by providing coherent frameworks for competitive landscape analysis and end-to-end Bayesian hypothesis tests in the context of reporting clinical trial outcomes.
AnyTool: Self-Reflective, Hierarchical Agents for Large-Scale API Calls
Feb 06, 2024



We introduce AnyTool, a large language model agent designed to revolutionize the utilization of a vast array of tools in addressing user queries. We utilize over 16,000 APIs from Rapid API, operating under the assumption that a subset of these APIs could potentially resolve the queries. AnyTool primarily incorporates three elements: an API retriever with a hierarchical structure, a solver aimed at resolving user queries using a selected set of API candidates, and a self-reflection mechanism, which re-activates AnyTool if the initial solution proves impracticable. AnyTool is powered by the function calling feature of GPT-4, eliminating the need for training external modules. We also revisit the evaluation protocol introduced by previous works and identify a limitation in this protocol that leads to an artificially high pass rate. By revising the evaluation protocol to better reflect practical application scenarios, we introduce an additional benchmark, termed AnyToolBench. Experiments across various datasets demonstrate the superiority of our AnyTool over strong baselines such as ToolLLM and a GPT-4 variant tailored for tool utilization. For instance, AnyTool outperforms ToolLLM by +35.4% in terms of average pass rate on ToolBench. Code will be available at https://github.com/dyabel/AnyTool.
General Automatic Solution Generation of Social Problems
Jan 25, 2024Given the escalating intricacy and multifaceted nature of contemporary social systems, manually generating solutions to address pertinent social issues has become a formidable task. In response to this challenge, the rapid development of artificial intelligence has spurred the exploration of computational methodologies aimed at automatically generating solutions. However, current methods for auto-generation of solutions mainly concentrate on local social regulations that pertain to specific scenarios. Here, we report an automatic social operating system (ASOS) designed for general social solution generation, which is built upon agent-based models, enabling both global and local analyses and regulations of social problems across spatial and temporal dimensions. ASOS adopts a hypergraph with extensible social semantics for a comprehensive and structured representation of social dynamics. It also incorporates a generalized protocol for standardized hypergraph operations and a symbolic hybrid framework that delivers interpretable solutions, yielding a balance between regulatory efficacy and function viability. To demonstrate the effectiveness of ASOS, we apply it to the domain of averting extreme events within international oil futures markets. By generating a new trading role supplemented by new mechanisms, ASOS can adeptly discern precarious market conditions and make front-running interventions for non-profit purposes. This study demonstrates that ASOS provides an efficient and systematic approach for generating solutions for enhancing our society.
Spiking Structured State Space Model for Monaural Speech Enhancement
Sep 07, 2023Speech enhancement seeks to extract clean speech from noisy signals. Traditional deep learning methods face two challenges: efficiently using information in long speech sequences and high computational costs. To address these, we introduce the Spiking Structured State Space Model (Spiking-S4). This approach merges the energy efficiency of Spiking Neural Networks (SNN) with the long-range sequence modeling capabilities of Structured State Space Models (S4), offering a compelling solution. Evaluation on the DNS Challenge and VoiceBank+Demand Datasets confirms that Spiking-S4 rivals existing Artificial Neural Network (ANN) methods but with fewer computational resources, as evidenced by reduced parameters and Floating Point Operations (FLOPs).