 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonoUNet: A Robust Tiny Neural Network for Automated Knee Cartilage Segmentation on Point-of-Care Ultrasound Devices
Apr 09, 2026Objective: To develop a robust and compact deep learning model for automated knee cartilage segmentation on point-of-care ultrasound (POCUS) devices. Methods: We propose MonoUNet, an ultra-compact U-Net consisting of (i) an aggressively reduced backbone with an asymmetric decoder, (ii) a trainable monogenic block that extracts multi-scale local phase features, and (iii) a gated feature injection mechanism that integrates these features into the encoder stages to reduce sensitivity to variations in ultrasound image appearance and improve robustness across devices. MonoUNet was evaluated on a multi-site, multi-device knee cartilage ultrasound dataset acquired using cart-based, portable, and handheld POCUS devices. Results: Overall, MonoUNet outperformed existing lightweight segmentation models, with average Dice scores ranging from 92.62% to 94.82% and mean average surface distance (MASD) values between 0.133 mm and 0.254 mm. MonoUNet reduces the number of parameters by 10x--700x and computational cost by 14x--2000x relative to existing lightweight models. MonoUNet cartilage outcomes showed excellent reliability and agreement with the manual outcomes: intraclass correlation coefficients (ICC$_{2,k})$=0.96 and bias=2.00% (0.047 mm) for average thickness, and ICC$_{2,k}$=0.99 and bias=0.80% (0.328 a.u.) for echo intensity. Conclusion: Incorporating trainable local phase features improves the robustness of highly compact neural networks for knee cartilage segmentation across varying acquisition settings and could support scalable ultrasound-based assessment and monitoring of knee osteoarthritis using POCUS devices. The code is publicly available at https://github.com/alvinkimbowa/monounet.
Generating Synthetic Doctor-Patient Conversations for Long-form Audio Summarization
Apr 07, 2026Long-context audio reasoning is underserved in both training data and evaluation. Existing benchmarks target short-context tasks, and the open-ended generation tasks most relevant to long-context reasoning pose well-known challenges for automatic evaluation. We propose a synthetic data generation pipeline designed to serve both as a training resource and as a controlled evaluation environment, and instantiate it for first-visit doctor-patient conversations with SOAP note generation as the task. The pipeline has three stages, persona-driven dialogue generation, multi-speaker audio synthesis with overlap/pause modeling, room acoustics, and sound events, and LLM-based reference SOAP note production, built entirely on open-weight models. We release 8,800 synthetic conversations with 1.3k hours of corresponding audio and reference notes. Evaluating current open-weight systems, we find that cascaded approaches still substantially outperform end-to-end models.
Representation-Level Adversarial Regularization for Clinically Aligned Multitask Thyroid Ultrasound Assessment
Mar 22, 2026Thyroid ultrasound is the first-line exam for assessing thyroid nodules and determining whether biopsy is warranted. In routine reporting, radiologists produce two coupled outputs: a nodule contour for measurement and a TI-RADS risk category based on sonographic criteria. Yet both contouring style and risk grading vary across readers, creating inconsistent supervision that can degrade standard learning pipelines. In this paper, we address this workflow with a clinically guided multitask framework that jointly predicts the nodule mask and TI-RADS category within a single model. To ground risk prediction in clinically meaningful evidence, we guide the classification embedding using a compact TI-RADS aligned radiomics target during training, while preserving complementary deep features for discriminative performance. However, under annotator variability, naive multitask optimization often fails not because the tasks are unrelated, but because their gradients compete within the shared representation. To make this competition explicit and controllable, we introduce RLAR, a representation-level adversarial gradient regularizer. Rather than performing parameter-level gradient surgery, RLAR uses each task's normalized adversarial direction in latent space as a geometric probe of task sensitivity and penalizes excessive angular alignment between task-specific adversarial directions. On a public TI-RADS dataset, our clinically guided multitask model with RLAR consistently improves risk stratification while maintaining segmentation quality compared to single-task training and conventional multitask baselines. Code and pretrained models will be released.
ViThinker: Active Vision-Language Reasoning via Dynamic Perceptual Querying
Feb 02, 2026Chain-of-Thought (CoT) reasoning excels in language models but struggles in vision-language models due to premature visual-to-text conversion that discards continuous information such as geometry and spatial layout. While recent methods enhance CoT through static enumeration or attention-based selection, they remain passive, i.e., processing pre-computed inputs rather than actively seeking task-relevant details. Inspired by human active perception, we introduce ViThinker, a framework that enables vision-language models to autonomously generate decision (query) tokens triggering the synthesis of expert-aligned visual features on demand. ViThinker internalizes vision-expert capabilities during training, performing generative mental simulation during inference without external tool calls. Through a two-stage curriculum: first distilling frozen experts into model parameters, then learning task-driven querying via sparsity penalties, i.e., ViThinker discovers minimal sufficient perception for each reasoning step. Evaluations across vision-centric benchmarks demonstrate consistent improvements, validating that active query generation outperforms passive approaches in both perceptual grounding and reasoning accuracy.
Distribution Matching Distillation Meets Reinforcement Learning
Nov 19, 2025Distribution Matching Distillation (DMD) distills a pre-trained multi-step diffusion model to a few-step one to improve inference efficiency. However, the performance of the latter is often capped by the former. To circumvent this dilemma, we propose DMDR, a novel framework that combines Reinforcement Learning (RL) techniques into the distillation process. We show that for the RL of the few-step generator, the DMD loss itself is a more effective regularization compared to the traditional ones. In turn, RL can help to guide the mode coverage process in DMD more effectively. These allow us to unlock the capacity of the few-step generator by conducting distillation and RL simultaneously. Meanwhile, we design the dynamic distribution guidance and dynamic renoise sampling training strategies to improve the initial distillation process. The experiments demonstrate that DMDR can achieve leading visual quality, prompt coherence among few-step methods, and even exhibit performance that exceeds the multi-step teacher.
Mono2D: A Trainable Monogenic Layer for Robust Knee Cartilage Segmentation on Out-of-Distribution 2D Ultrasound Data
Mar 12, 2025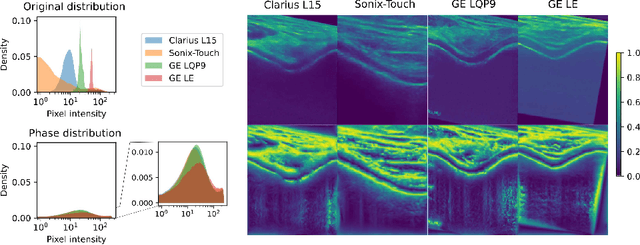



Automated knee cartilage segmentation using point-of-care ultrasound devices and deep-learning networks has the potential to enhance the management of knee osteoarthritis. However, segmentation algorithms often struggle with domain shifts caused by variations in ultrasound devices and acquisition parameters, limiting their generalizability. In this paper, we propose Mono2D, a monogenic layer that extracts multi-scale, contrast- and intensity-invariant local phase features using trainable bandpass quadrature filters. This layer mitigates domain shifts, improving generalization to out-of-distribution domains. Mono2D is integrated before the first layer of a segmentation network, and its parameters jointly trained alongside the network's parameters. We evaluated Mono2D on a multi-domain 2D ultrasound knee cartilage dataset for single-source domain generalization (SSDG). Our results demonstrate that Mono2D outperforms other SSDG methods in terms of Dice score and mean average surface distance. To further assess its generalizability, we evaluate Mono2D on a multi-site prostate MRI dataset, where it continues to outperform other SSDG methods, highlighting its potential to improve domain generalization in medical imaging. Nevertheless, further evaluation on diverse datasets is still necessary to assess its clinical utility.
Re-visiting Skip-Gram Negative Sampling: Dimension Regularization for More Efficient Dissimilarity Preservation in Graph Embeddings
Apr 30, 2024



A wide range of graph embedding objectives decompose into two components: one that attracts the embeddings of nodes that are perceived as similar, and another that repels embeddings of nodes that are perceived as dissimilar. Because real-world graphs are sparse and the number of dissimilar pairs grows quadratically with the number of nodes, Skip-Gram Negative Sampling (SGNS) has emerged as a popular and efficient repulsion approach. SGNS repels each node from a sample of dissimilar nodes, as opposed to all dissimilar nodes. In this work, we show that node-wise repulsion is, in aggregate, an approximate re-centering of the node embedding dimensions. Such dimension operations are much more scalable than node operations. The dimension approach, in addition to being more efficient, yields a simpler geometric interpretation of the repulsion. Our result extends findings from the self-supervised learning literature to the skip-gram model, establishing a connection between skip-gram node contrast and dimension regularization. We show that in the limit of large graphs, under mild regularity conditions, the original node repulsion objective converges to optimization with dimension regularization. We use this observation to propose an algorithm augmentation framework that speeds up any existing algorithm, supervised or unsupervised, using SGNS. The framework prioritizes node attraction and replaces SGNS with dimension regularization. We instantiate this generic framework for LINE and node2vec and show that the augmented algorithms preserve downstream performance while dramatically increasing efficiency.
APP-RUSS: Automated Path Planning for Robotic Ultrasound System
Oct 22, 2023Autonomous robotic ultrasound System (RUSS) has been extensively studied. However, fully automated ultrasound image acquisition is still challenging, partly due to the lack of study in combining two phases of path planning: guiding the ultrasound probe to the scan target and covering the scan surface or volume. This paper presents a system of Automated Path Planning for RUSS (APP-RUSS). Our focus is on the first phase of automation, which emphasizes directing the ultrasound probe's path toward the target over extended distances. Specifically, our APP-RUSS system consists of a RealSense D405 RGB-D camera that is employed for visual guidance of the UR5e robotic arm and a cubic Bezier curve path planning model that is customized for delivering the probe to the recognized target. APP-RUSS can contribute to understanding the integration of the two phases of path planning in robotic ultrasound imaging, paving the way for its clinical adoption.
DT/MARS-CycleGAN: Improved Object Detection for MARS Phenotyping Robot
Oct 20, 2023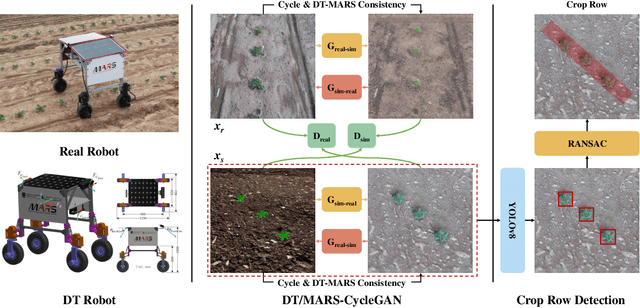
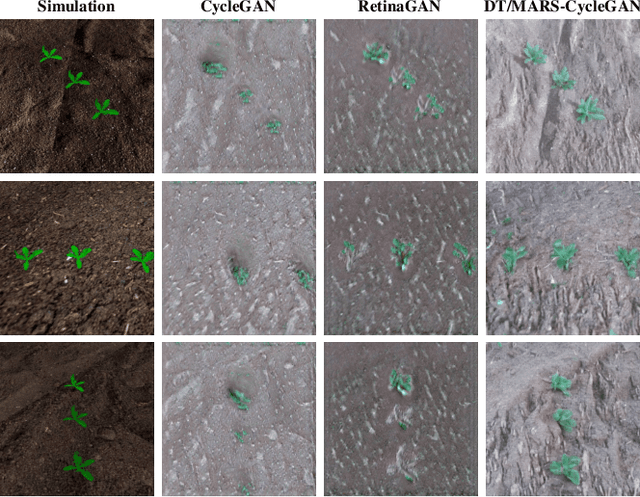

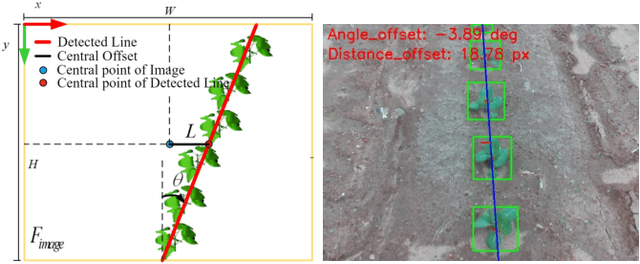
Robotic crop phenotyping has emerged as a key technology to assess crops' morphological and physiological traits at scale. These phenotypical measurements are essential for developing new crop varieties with the aim of increasing productivity and dealing with environmental challenges such as climate change. However, developing and deploying crop phenotyping robots face many challenges such as complex and variable crop shapes that complicate robotic object detection, dynamic and unstructured environments that baffle robotic control, and real-time computing and managing big data that challenge robotic hardware/software. This work specifically tackles the first challenge by proposing a novel Digital-Twin(DT)MARS-CycleGAN model for image augmentation to improve our Modular Agricultural Robotic System (MARS)'s crop object detection from complex and variable backgrounds. Our core idea is that in addition to the cycle consistency losses in the CycleGAN model, we designed and enforced a new DT-MARS loss in the deep learning model to penalize the inconsistency between real crop images captured by MARS and synthesized images sensed by DT MARS. Therefore, the generated synthesized crop images closely mimic real images in terms of realism, and they are employed to fine-tune object detectors such as YOLOv8. Extensive experiments demonstrated that our new DT/MARS-CycleGAN framework significantly boosts our MARS' crop object/row detector's performance, contributing to the field of robotic crop phenotyping.
When Collaborative Filtering is not Collaborative: Unfairness of PCA for Recommendations
Oct 15, 2023



We study the fairness of dimensionality reduction methods for recommendations. We focus on the established method of principal component analysis (PCA), which identifies latent components and produces a low-rank approximation via the leading components while discarding the trailing components. Prior works have defined notions of "fair PCA"; however, these definitions do not answer the following question: what makes PCA unfair? We identify two underlying mechanisms of PCA that induce unfairness at the item level. The first negatively impacts less popular items, due to the fact that less popular items rely on trailing latent components to recover their values. The second negatively impacts the highly popular items, since the leading PCA components specialize in individual popular items instead of capturing similarities between items. To address these issues, we develop a polynomial-time algorithm, Item-Weighted PCA, a modification of PCA that uses item-specific weights in the objective. On a stylized class of matrices, we prove that Item-Weighted PCA using a specific set of weights minimizes a popularity-normalized error metric. Our evaluations on real-world datasets show that Item-Weighted PCA not only improves overall recommendation quality by up to $0.1$ item-level AUC-ROC but also improves on both popular and less popular items.