Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMViT: Multiscale Multiview Vision Transformers
Paper and Code
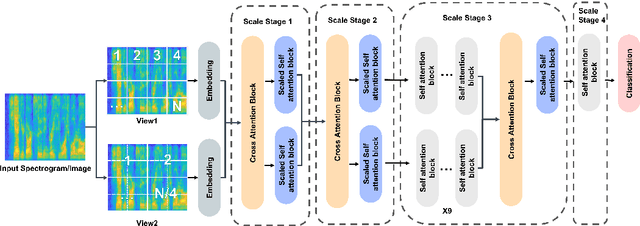
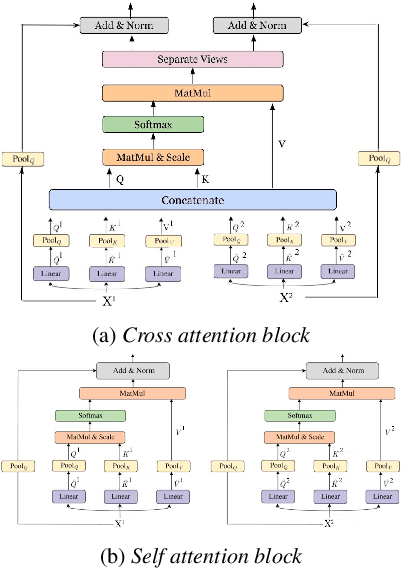
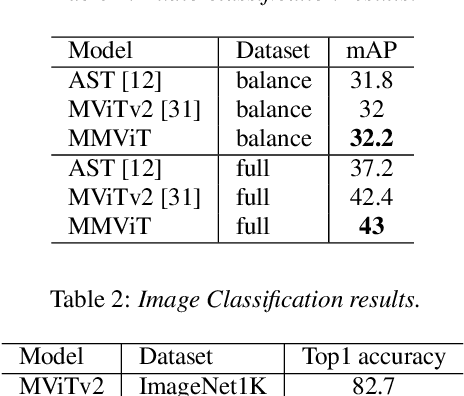
We present Multiscale Multiview Vision Transformers (MMViT), which introduces multiscale feature maps and multiview encodings to transformer models. Our model encodes different views of the input signal and builds several channel-resolution feature stages to process the multiple views of the input at different resolutions in parallel. At each scale stage, we use a cross-attention block to fuse information across different views. This enables the MMViT model to acquire complex high-dimensional representations of the input at different resolutions. The proposed model can serve as a backbone model in multiple domains. We demonstrate the effectiveness of MMViT on audio and image classification tasks, achieving state-of-the-art results.
View paper on