 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Attention Beyond Neighborhoods: Reviving Transformer for Graph Clustering
Sep 18, 2025Attention mechanisms have become a cornerstone in modern neural networks, driving breakthroughs across diverse domains. However, their application to graph structured data, where capturing topological connections is essential, remains underexplored and underperforming compared to Graph Neural Networks (GNNs), particularly in the graph clustering task. GNN tends to overemphasize neighborhood aggregation, leading to a homogenization of node representations. Conversely, Transformer tends to over globalize, highlighting distant nodes at the expense of meaningful local patterns. This dichotomy raises a key question: Is attention inherently redundant for unsupervised graph learning? To address this, we conduct a comprehensive empirical analysis, uncovering the complementary weaknesses of GNN and Transformer in graph clustering. Motivated by these insights, we propose the Attentive Graph Clustering Network (AGCN) a novel architecture that reinterprets the notion that graph is attention. AGCN directly embeds the attention mechanism into the graph structure, enabling effective global information extraction while maintaining sensitivity to local topological cues. Our framework incorporates theoretical analysis to contrast AGCN behavior with GNN and Transformer and introduces two innovations: (1) a KV cache mechanism to improve computational efficiency, and (2) a pairwise margin contrastive loss to boost the discriminative capacity of the attention space. Extensive experimental results demonstrate that AGCN outperforms state-of-the-art methods.
High Accuracy, Less Talk (HALT): Reliable LLMs through Capability-Aligned Finetuning
Jun 04, 2025Large Language Models (LLMs) currently respond to every prompt. However, they can produce incorrect answers when they lack knowledge or capability -- a problem known as hallucination. We instead propose post-training an LLM to generate content only when confident in its correctness and to otherwise (partially) abstain. Specifically, our method, HALT, produces capability-aligned post-training data that encodes what the model can and cannot reliably generate. We generate this data by splitting responses of the pretrained LLM into factual fragments (atomic statements or reasoning steps), and use ground truth information to identify incorrect fragments. We achieve capability-aligned finetuning responses by either removing incorrect fragments or replacing them with "Unsure from Here" -- according to a tunable threshold that allows practitioners to trade off response completeness and mean correctness of the response's fragments. We finetune four open-source models for biography writing, mathematics, coding, and medicine with HALT for three different trade-off thresholds. HALT effectively trades off response completeness for correctness, increasing the mean correctness of response fragments by 15% on average, while resulting in a 4% improvement in the F1 score (mean of completeness and correctness of the response) compared to the relevant baselines. By tuning HALT for highest correctness, we train a single reliable Llama3-70B model with correctness increased from 51% to 87% across all four domains while maintaining 53% of the response completeness achieved with standard finetuning.
LlamaRL: A Distributed Asynchronous Reinforcement Learning Framework for Efficient Large-scale LLM Trainin
May 29, 2025Reinforcement Learning (RL) has become the most effective post-training approach for improving the capabilities of Large Language Models (LLMs). In practice, because of the high demands on latency and memory, it is particularly challenging to develop an efficient RL framework that reliably manages policy models with hundreds to thousands of billions of parameters. In this paper, we present LlamaRL, a fully distributed, asynchronous RL framework optimized for efficient training of large-scale LLMs with various model sizes (8B, 70B, and 405B parameters) on GPU clusters ranging from a handful to thousands of devices. LlamaRL introduces a streamlined, single-controller architecture built entirely on native PyTorch, enabling modularity, ease of use, and seamless scalability to thousands of GPUs. We also provide a theoretical analysis of LlamaRL's efficiency, including a formal proof that its asynchronous design leads to strict RL speed-up. Empirically, by leveraging best practices such as colocated model offloading, asynchronous off-policy training, and distributed direct memory access for weight synchronization, LlamaRL achieves significant efficiency gains -- up to 10.7x speed-up compared to DeepSpeed-Chat-like systems on a 405B-parameter policy model. Furthermore, the efficiency advantage continues to grow with increasing model scale, demonstrating the framework's suitability for future large-scale RL training.
Comet: Accelerating Private Inference for Large Language Model by Predicting Activation Sparsity
May 12, 2025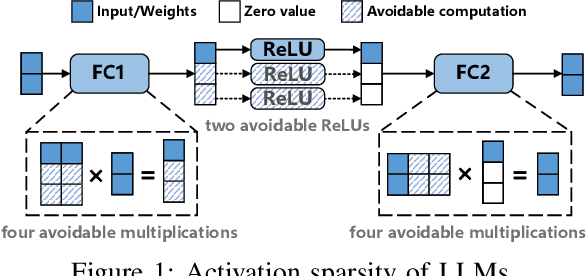
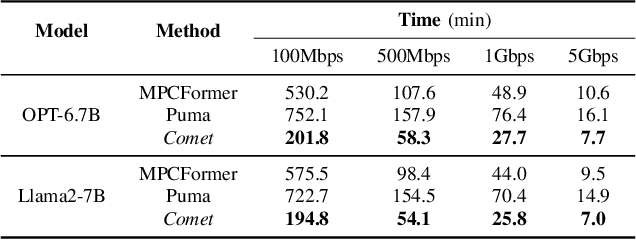
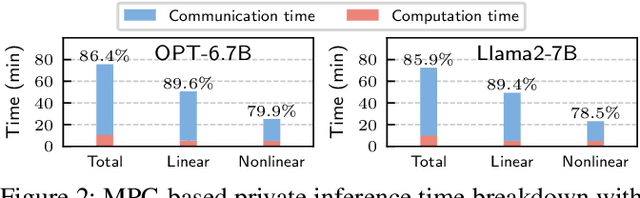
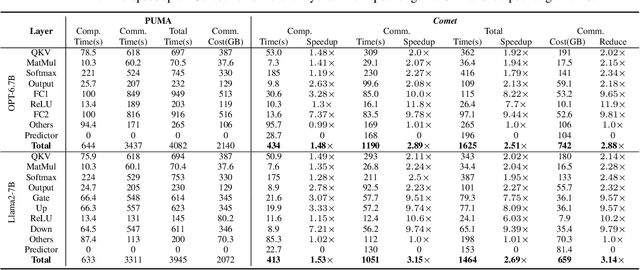
With the growing use of large language models (LLMs) hosted on cloud platforms to offer inference services, privacy concerns about the potential leakage of sensitive information are escalating. Secure multi-party computation (MPC) is a promising solution to protect the privacy in LLM inference. However, MPC requires frequent inter-server communication, causing high performance overhead. Inspired by the prevalent activation sparsity of LLMs, where most neuron are not activated after non-linear activation functions, we propose an efficient private inference system, Comet. This system employs an accurate and fast predictor to predict the sparsity distribution of activation function output. Additionally, we introduce a new private inference protocol. It efficiently and securely avoids computations involving zero values by exploiting the spatial locality of the predicted sparse distribution. While this computation-avoidance approach impacts the spatiotemporal continuity of KV cache entries, we address this challenge with a low-communication overhead cache refilling strategy that merges miss requests and incorporates a prefetching mechanism. Finally, we evaluate Comet on four common LLMs and compare it with six state-of-the-art private inference systems. Comet achieves a 1.87x-2.63x speedup and a 1.94x-2.64x communication reduction.
Autoregressive Stochastic Clock Jitter Compensation in Analog-to-Digital Converters
May 08, 2025This paper deals with the mathematical modeling and compensation of stochastic discrete time clock jitter in Analog-to-Digital Converters (ADCs). Two novel, computationally efficient de-jittering sample pilots-based algorithms for baseband signals are proposed: one consisting in solving a sequence of weighted least-squares problems and another that fully leverages the correlated jitter structure in a Kalman filter-type routine. Alongside, a comprehensive and rigorous mathematical analysis of the linearization errors committed is presented, and the work is complemented with extensive synthetic simulations and performance benchmarking with the scope of gauging and stress-testing the techniques in different scenarios.
Shadow Wireless Intelligence: Large Language Model-Driven Reasoning in Covert Communications
May 07, 2025Covert Communications (CC) can secure sensitive transmissions in industrial, military, and mission-critical applications within 6G wireless networks. However, traditional optimization methods based on Artificial Noise (AN), power control, and channel manipulation might not adapt to dynamic and adversarial environments due to the high dimensionality, nonlinearity, and stringent real-time covertness requirements. To bridge this gap, we introduce Shadow Wireless Intelligence (SWI), which integrates the reasoning capabilities of Large Language Models (LLMs) with retrieval-augmented generation to enable intelligent decision-making in covert wireless systems. Specifically, we utilize DeepSeek-R1, a mixture-of-experts-based LLM with RL-enhanced reasoning, combined with real-time retrieval of domain-specific knowledge to improve context accuracy and mitigate hallucinations. Our approach develops a structured CC knowledge base, supports context-aware retrieval, and performs semantic optimization, allowing LLMs to generate and adapt CC strategies in real time. In a case study on optimizing AN power in a full-duplex CC scenario, DeepSeek-R1 achieves 85% symbolic derivation accuracy and 94% correctness in the generation of simulation code, outperforming baseline models. These results validate SWI as a robust, interpretable, and adaptive foundation for LLM-driven intelligent covert wireless systems in 6G networks.
Diversity-driven Data Selection for Language Model Tuning through Sparse Autoencoder
Feb 19, 2025Current pre-trained large language models typically need instruction tuning to align with human preferences. However, instruction tuning data is often quantity-saturated due to the large volume of data collection and fast model iteration, leaving coreset data selection important but underexplored. On the other hand, existing quality-driven data selection methods such as LIMA (NeurIPS 2023 (Zhou et al., 2024)) and AlpaGasus (ICLR 2024 (Chen et al.)) generally ignore the equal importance of data diversity and complexity. In this work, we aim to design a diversity-aware data selection strategy and creatively propose using sparse autoencoders to tackle the challenge of data diversity measure. In addition, sparse autoencoders can also provide more interpretability of model behavior and explain, e.g., the surprising effectiveness of selecting the longest response (ICML 2024 (Zhao et al.)). Using effective data selection, we experimentally prove that models trained on our selected data can outperform other methods in terms of model capabilities, reduce training cost, and potentially gain more control over model behaviors.
A Systematic Examination of Preference Learning through the Lens of Instruction-Following
Dec 18, 2024Preference learning is a widely adopted post-training technique that aligns large language models (LLMs) to human preferences and improves specific downstream task capabilities. In this work we systematically investigate how specific attributes of preference datasets affect the alignment and downstream performance of LLMs in instruction-following tasks. We use a novel synthetic data generation pipeline to generate 48,000 unique instruction-following prompts with combinations of 23 verifiable constraints that enable fine-grained and automated quality assessments of model responses. With our synthetic prompts, we use two preference dataset curation methods - rejection sampling (RS) and Monte Carlo Tree Search (MCTS) - to obtain pairs of (chosen, rejected) responses. Then, we perform experiments investigating the effects of (1) the presence of shared prefixes between the chosen and rejected responses, (2) the contrast and quality of the chosen, rejected responses and (3) the complexity of the training prompts. Our experiments reveal that shared prefixes in preference pairs, as generated by MCTS, provide marginal but consistent improvements and greater stability across challenging training configurations. High-contrast preference pairs generally outperform low-contrast pairs; however, combining both often yields the best performance by balancing diversity and learning efficiency. Additionally, training on prompts of moderate difficulty leads to better generalization across tasks, even for more complex evaluation scenarios, compared to overly challenging prompts. Our findings provide actionable insights into optimizing preference data curation for instruction-following tasks, offering a scalable and effective framework for enhancing LLM training and alignment.
Self-Generated Critiques Boost Reward Modeling for Language Models
Nov 25, 2024



Reward modeling is crucial for aligning large language models (LLMs) with human preferences, especially in reinforcement learning from human feedback (RLHF). However, current reward models mainly produce scalar scores and struggle to incorporate critiques in a natural language format. We hypothesize that predicting both critiques and the scalar reward would improve reward modeling ability. Motivated by this, we propose Critic-RM, a framework that improves reward models using self-generated critiques without extra supervision. Critic-RM employs a two-stage process: generating and filtering high-quality critiques, followed by joint fine-tuning on reward prediction and critique generation. Experiments across benchmarks show that Critic-RM improves reward modeling accuracy by 3.7%-7.3% compared to standard reward models and LLM judges, demonstrating strong performance and data efficiency. Additional studies further validate the effectiveness of generated critiques in rectifying flawed reasoning steps with 2.5%-3.2% gains in improving reasoning accuracy.