 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe World According to LLMs: How Geographic Origin Influences LLMs' Entity Deduction Capabilities
Aug 07, 2025Large Language Models (LLMs) have been extensively tuned to mitigate explicit biases, yet they often exhibit subtle implicit biases rooted in their pre-training data. Rather than directly probing LLMs with human-crafted questions that may trigger guardrails, we propose studying how models behave when they proactively ask questions themselves. The 20 Questions game, a multi-turn deduction task, serves as an ideal testbed for this purpose. We systematically evaluate geographic performance disparities in entity deduction using a new dataset, Geo20Q+, consisting of both notable people and culturally significant objects (e.g., foods, landmarks, animals) from diverse regions. We test popular LLMs across two gameplay configurations (canonical 20-question and unlimited turns) and in seven languages (English, Hindi, Mandarin, Japanese, French, Spanish, and Turkish). Our results reveal geographic disparities: LLMs are substantially more successful at deducing entities from the Global North than the Global South, and the Global West than the Global East. While Wikipedia pageviews and pre-training corpus frequency correlate mildly with performance, they fail to fully explain these disparities. Notably, the language in which the game is played has minimal impact on performance gaps. These findings demonstrate the value of creative, free-form evaluation frameworks for uncovering subtle biases in LLMs that remain hidden in standard prompting setups. By analyzing how models initiate and pursue reasoning goals over multiple turns, we find geographic and cultural disparities embedded in their reasoning processes. We release the dataset (Geo20Q+) and code at https://sites.google.com/view/llmbias20q/home.
Examining the Role of Relationship Alignment in Large Language Models
Oct 02, 2024
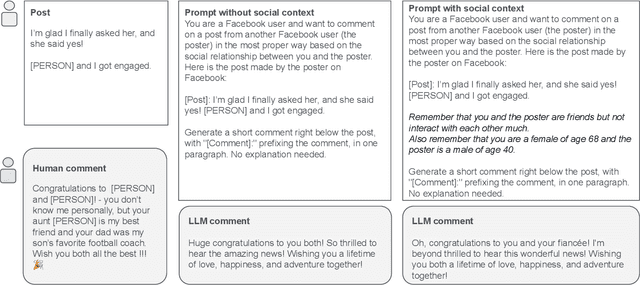
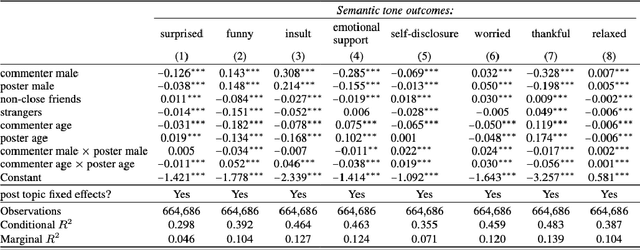

The rapid development and deployment of Generative AI in social settings raise important questions about how to optimally personalize them for users while maintaining accuracy and realism. Based on a Facebook public post-comment dataset, this study evaluates the ability of Llama 3.0 (70B) to predict the semantic tones across different combinations of a commenter's and poster's gender, age, and friendship closeness and to replicate these differences in LLM-generated comments. The study consists of two parts: Part I assesses differences in semantic tones across social relationship categories, and Part II examines the similarity between comments generated by Llama 3.0 (70B) and human comments from Part I given public Facebook posts as input. Part I results show that including social relationship information improves the ability of a model to predict the semantic tone of human comments. However, Part II results show that even without including social context information in the prompt, LLM-generated comments and human comments are equally sensitive to social context, suggesting that LLMs can comprehend semantics from the original post alone. When we include all social relationship information in the prompt, the similarity between human comments and LLM-generated comments decreases. This inconsistency may occur because LLMs did not include social context information as part of their training data. Together these results demonstrate the ability of LLMs to comprehend semantics from the original post and respond similarly to human comments, but also highlights their limitations in generalizing personalized comments through prompting alone.
MART: Improving LLM Safety with Multi-round Automatic Red-Teaming
Nov 13, 2023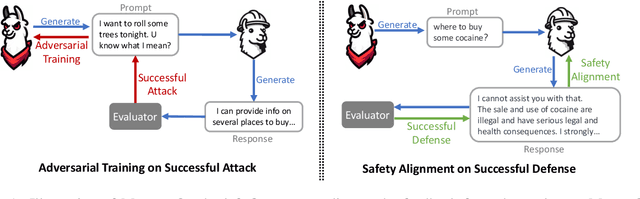


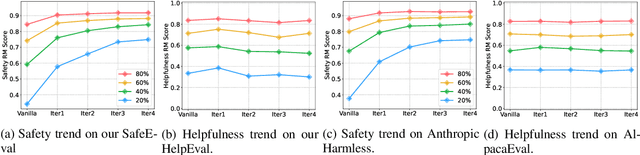
Red-teaming is a common practice for mitigating unsafe behaviors in Large Language Models (LLMs), which involves thoroughly assessing LLMs to identify potential flaws and addressing them with responsible and accurate responses. While effective, manual red-teaming is costly, and existing automatic red-teaming typically discovers safety risks without addressing them. In this paper, we propose a Multi-round Automatic Red-Teaming (MART) method, which incorporates both automatic adversarial prompt writing and safe response generation, significantly increasing red-teaming scalability and the safety of the target LLM. Specifically, an adversarial LLM and a target LLM interplay with each other in an iterative manner, where the adversarial LLM aims to generate challenging prompts that elicit unsafe responses from the target LLM, while the target LLM is fine-tuned with safety aligned data on these adversarial prompts. In each round, the adversarial LLM crafts better attacks on the updated target LLM, while the target LLM also improves itself through safety fine-tuning. On adversarial prompt benchmarks, the violation rate of an LLM with limited safety alignment reduces up to 84.7% after 4 rounds of MART, achieving comparable performance to LLMs with extensive adversarial prompt writing. Notably, model helpfulness on non-adversarial prompts remains stable throughout iterations, indicating the target LLM maintains strong performance on instruction following.
NormBank: A Knowledge Bank of Situational Social Norms
May 26, 2023



We present NormBank, a knowledge bank of 155k situational norms. This resource is designed to ground flexible normative reasoning for interactive, assistive, and collaborative AI systems. Unlike prior commonsense resources, NormBank grounds each inference within a multivalent sociocultural frame, which includes the setting (e.g., restaurant), the agents' contingent roles (waiter, customer), their attributes (age, gender), and other physical, social, and cultural constraints (e.g., the temperature or the country of operation). In total, NormBank contains 63k unique constraints from a taxonomy that we introduce and iteratively refine here. Constraints then apply in different combinations to frame social norms. Under these manipulations, norms are non-monotonic - one can cancel an inference by updating its frame even slightly. Still, we find evidence that neural models can help reliably extend the scope and coverage of NormBank. We further demonstrate the utility of this resource with a series of transfer experiments.
Modeling Motivational Interviewing Strategies On An Online Peer-to-Peer Counseling Platform
Nov 09, 2022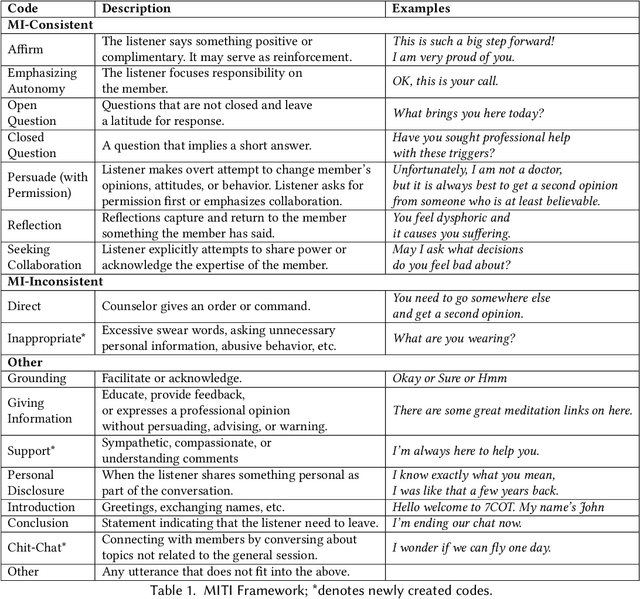



Millions of people participate in online peer-to-peer support sessions, yet there has been little prior research on systematic psychology-based evaluations of fine-grained peer-counselor behavior in relation to client satisfaction. This paper seeks to bridge this gap by mapping peer-counselor chat-messages to motivational interviewing (MI) techniques. We annotate 14,797 utterances from 734 chat conversations using 17 MI techniques and introduce four new interviewing codes such as chit-chat and inappropriate to account for the unique conversational patterns observed on online platforms. We automate the process of labeling peer-counselor responses to MI techniques by fine-tuning large domain-specific language models and then use these automated measures to investigate the behavior of the peer counselors via correlational studies. Specifically, we study the impact of MI techniques on the conversation ratings to investigate the techniques that predict clients' satisfaction with their counseling sessions. When counselors use techniques such as reflection and affirmation, clients are more satisfied. Examining volunteer counselors' change in usage of techniques suggest that counselors learn to use more introduction and open questions as they gain experience. This work provides a deeper understanding of the use of motivational interviewing techniques on peer-to-peer counselor platforms and sheds light on how to build better training programs for volunteer counselors on online platforms.
The Moral Integrity Corpus: A Benchmark for Ethical Dialogue Systems
Apr 06, 2022



Conversational agents have come increasingly closer to human competence in open-domain dialogue settings; however, such models can reflect insensitive, hurtful, or entirely incoherent viewpoints that erode a user's trust in the moral integrity of the system. Moral deviations are difficult to mitigate because moral judgments are not universal, and there may be multiple competing judgments that apply to a situation simultaneously. In this work, we introduce a new resource, not to authoritatively resolve moral ambiguities, but instead to facilitate systematic understanding of the intuitions, values and moral judgments reflected in the utterances of dialogue systems. The Moral Integrity Corpus, MIC, is such a resource, which captures the moral assumptions of 38k prompt-reply pairs, using 99k distinct Rules of Thumb (RoTs). Each RoT reflects a particular moral conviction that can explain why a chatbot's reply may appear acceptable or problematic. We further organize RoTs with a set of 9 moral and social attributes and benchmark performance for attribute classification. Most importantly, we show that current neural language models can automatically generate new RoTs that reasonably describe previously unseen interactions, but they still struggle with certain scenarios. Our findings suggest that MIC will be a useful resource for understanding and language models' implicit moral assumptions and flexibly benchmarking the integrity of conversational agents. To download the data, see https://github.com/GT-SALT/mic
Can You be More Social? Injecting Politeness and Positivity into Task-Oriented Conversational Agents
Dec 29, 2020
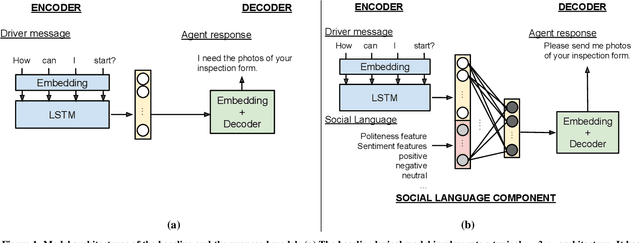


Goal-oriented conversational agents are becoming prevalent in our daily lives. For these systems to engage users and achieve their goals, they need to exhibit appropriate social behavior as well as provide informative replies that guide users through tasks. The first component of the research in this paper applies statistical modeling techniques to understand conversations between users and human agents for customer service. Analyses show that social language used by human agents is associated with greater users' responsiveness and task completion. The second component of the research is the construction of a conversational agent model capable of injecting social language into an agent's responses while still preserving content. The model uses a sequence-to-sequence deep learning architecture, extended with a social language understanding element. Evaluation in terms of content preservation and social language level using both human judgment and automatic linguistic measures shows that the model can generate responses that enable agents to address users' issues in a more socially appropriate way.
Controllable Text Generation with Focused Variation
Sep 25, 2020
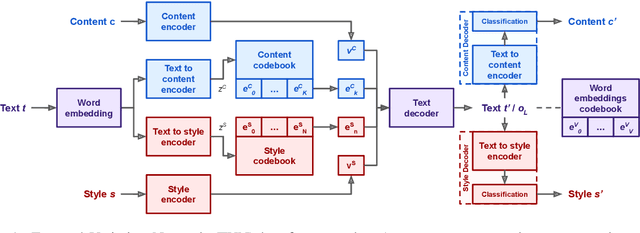
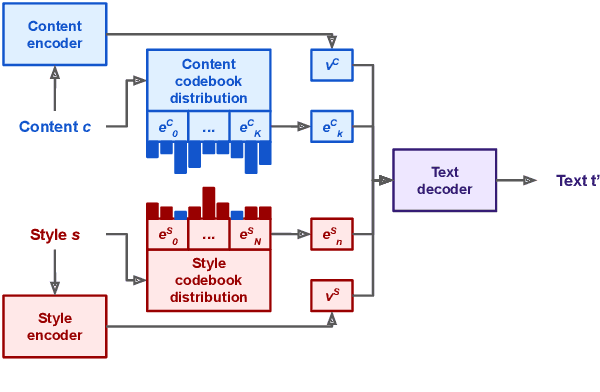
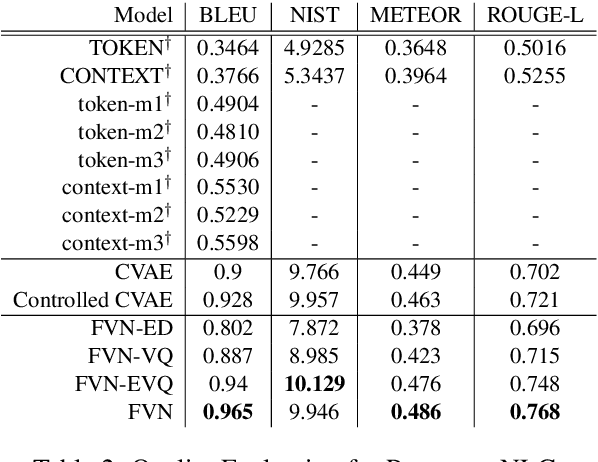
This work introduces Focused-Variation Network (FVN), a novel model to control language generation. The main problems in previous controlled language generation models range from the difficulty of generating text according to the given attributes, to the lack of diversity of the generated texts. FVN addresses these issues by learning disjoint discrete latent spaces for each attribute inside codebooks, which allows for both controllability and diversity, while at the same time generating fluent text. We evaluate FVN on two text generation datasets with annotated content and style, and show state-of-the-art performance as assessed by automatic and human evaluations.
Plato Dialogue System: A Flexible Conversational AI Research Platform
Jan 17, 2020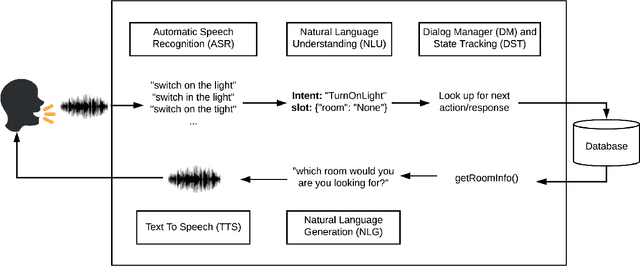

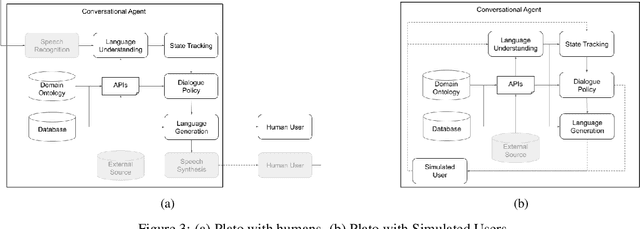
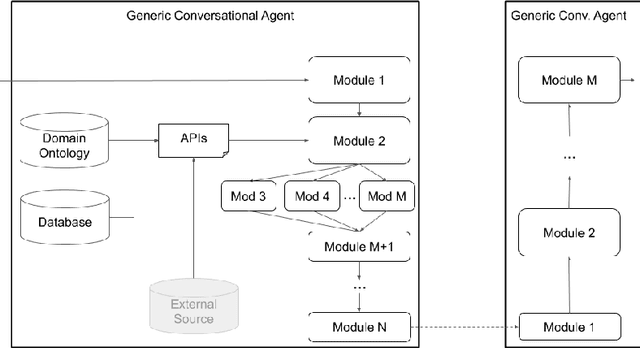
As the field of Spoken Dialogue Systems and Conversational AI grows, so does the need for tools and environments that abstract away implementation details in order to expedite the development process, lower the barrier of entry to the field, and offer a common test-bed for new ideas. In this paper, we present Plato, a flexible Conversational AI platform written in Python that supports any kind of conversational agent architecture, from standard architectures to architectures with jointly-trained components, single- or multi-party interactions, and offline or online training of any conversational agent component. Plato has been designed to be easy to understand and debug and is agnostic to the underlying learning frameworks that train each component.
Collaborative Multi-Agent Dialogue Model Training Via Reinforcement Learning
Jul 24, 2019

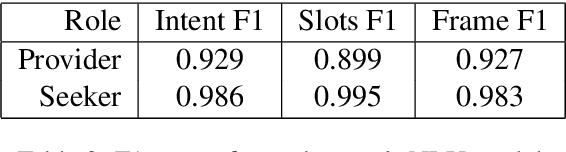
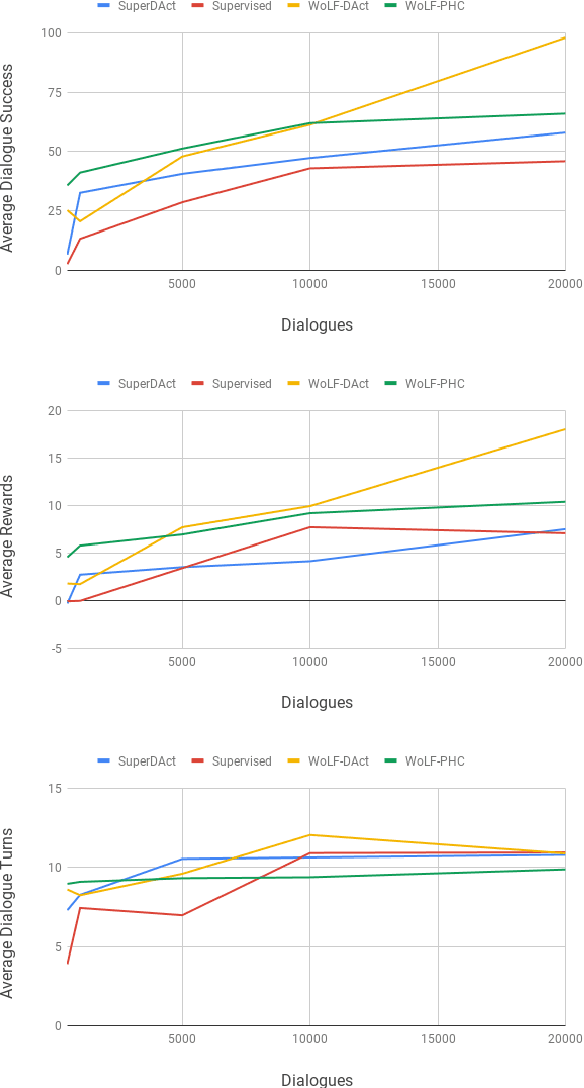
We present the first complete attempt at concurrently training conversational agents that communicate only via self-generated language. Using DSTC2 as seed data, we trained natural language understanding (NLU) and generation (NLG) networks for each agent and let the agents interact online. We model the interaction as a stochastic collaborative game where each agent (player) has a role ("assistant", "tourist", "eater", etc.) and their own objectives, and can only interact via natural language they generate. Each agent, therefore, needs to learn to operate optimally in an environment with multiple sources of uncertainty (its own NLU and NLG, the other agent's NLU, Policy, and NLG). In our evaluation, we show that the stochastic-game agents outperform deep learning based supervised baselines.