 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet It Flow: Agentic Crafting on Rock and Roll, Building the ROME Model within an Open Agentic Learning Ecosystem
Dec 31, 2025Agentic crafting requires LLMs to operate in real-world environments over multiple turns by taking actions, observing outcomes, and iteratively refining artifacts. Despite its importance, the open-source community lacks a principled, end-to-end ecosystem to streamline agent development. We introduce the Agentic Learning Ecosystem (ALE), a foundational infrastructure that optimizes the production pipeline for agent LLMs. ALE consists of three components: ROLL, a post-training framework for weight optimization; ROCK, a sandbox environment manager for trajectory generation; and iFlow CLI, an agent framework for efficient context engineering. We release ROME (ROME is Obviously an Agentic Model), an open-source agent grounded by ALE and trained on over one million trajectories. Our approach includes data composition protocols for synthesizing complex behaviors and a novel policy optimization algorithm, Interaction-based Policy Alignment (IPA), which assigns credit over semantic interaction chunks rather than individual tokens to improve long-horizon training stability. Empirically, we evaluate ROME within a structured setting and introduce Terminal Bench Pro, a benchmark with improved scale and contamination control. ROME demonstrates strong performance across benchmarks like SWE-bench Verified and Terminal Bench, proving the effectiveness of the ALE infrastructure.
Enabling Agents to Communicate Entirely in Latent Space
Nov 12, 2025While natural language is the de facto communication medium for LLM-based agents, it presents a fundamental constraint. The process of downsampling rich, internal latent states into discrete tokens inherently limits the depth and nuance of information that can be transmitted, thereby hindering collaborative problem-solving. Inspired by human mind-reading, we propose Interlat (Inter-agent Latent Space Communication), a paradigm that leverages the last hidden states of an LLM as a representation of its mind for direct transmission (termed latent communication). An additional compression process further compresses latent communication via entirely latent space reasoning. Experiments demonstrate that Interlat outperforms both fine-tuned chain-of-thought (CoT) prompting and single-agent baselines, promoting more exploratory behavior and enabling genuine utilization of latent information. Further compression not only substantially accelerates inference but also maintains competitive performance through an efficient information-preserving mechanism. We position this work as a feasibility study of entirely latent space inter-agent communication, and our results highlight its potential, offering valuable insights for future research.
Anatomy-Aware Low-Dose CT Denoising via Pretrained Vision Models and Semantic-Guided Contrastive Learning
Aug 11, 2025To reduce radiation exposure and improve the diagnostic efficacy of low-dose computed tomography (LDCT), numerous deep learning-based denoising methods have been developed to mitigate noise and artifacts. However, most of these approaches ignore the anatomical semantics of human tissues, which may potentially result in suboptimal denoising outcomes. To address this problem, we propose ALDEN, an anatomy-aware LDCT denoising method that integrates semantic features of pretrained vision models (PVMs) with adversarial and contrastive learning. Specifically, we introduce an anatomy-aware discriminator that dynamically fuses hierarchical semantic features from reference normal-dose CT (NDCT) via cross-attention mechanisms, enabling tissue-specific realism evaluation in the discriminator. In addition, we propose a semantic-guided contrastive learning module that enforces anatomical consistency by contrasting PVM-derived features from LDCT, denoised CT and NDCT, preserving tissue-specific patterns through positive pairs and suppressing artifacts via dual negative pairs. Extensive experiments conducted on two LDCT denoising datasets reveal that ALDEN achieves the state-of-the-art performance, offering superior anatomy preservation and substantially reducing over-smoothing issue of previous work. Further validation on a downstream multi-organ segmentation task (encompassing 117 anatomical structures) affirms the model's ability to maintain anatomical awareness.
Cross-View Multi-Modal Segmentation @ Ego-Exo4D Challenges 2025
Jun 06, 2025In this report, we present a cross-view multi-modal object segmentation approach for the object correspondence task in the Ego-Exo4D Correspondence Challenges 2025. Given object queries from one perspective (e.g., ego view), the goal is to predict the corresponding object masks in another perspective (e.g., exo view). To tackle this task, we propose a multimodal condition fusion module that enhances object localization by leveraging both visual masks and textual descriptions as segmentation conditions. Furthermore, to address the visual domain gap between ego and exo views, we introduce a cross-view object alignment module that enforces object-level consistency across perspectives, thereby improving the model's robustness to viewpoint changes. Our proposed method ranked second on the leaderboard of the large-scale Ego-Exo4D object correspondence benchmark. Code will be made available at https://github.com/lovelyqian/ObjectRelator.
Bridging Molecular Graphs and Large Language Models
Mar 05, 2025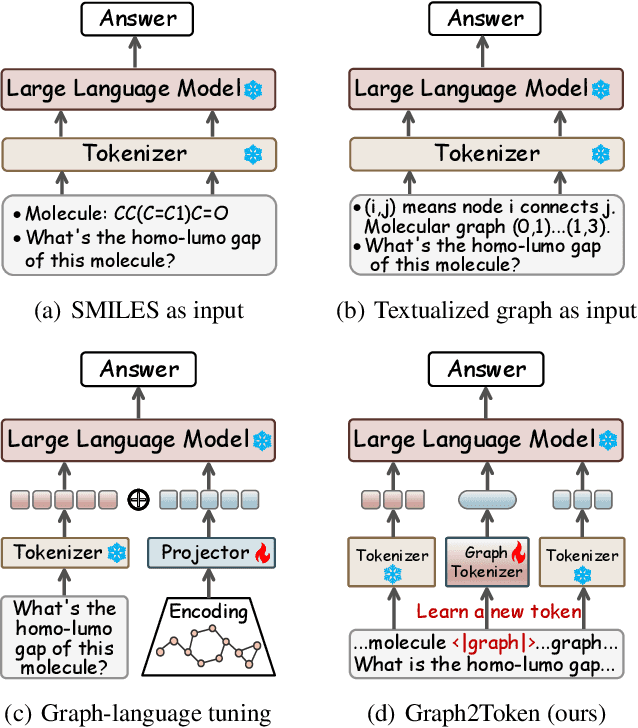
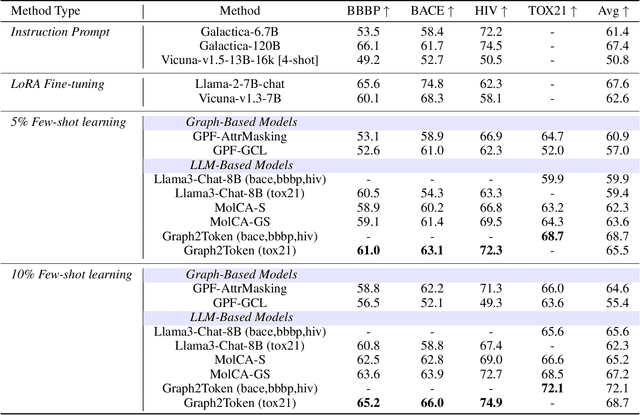
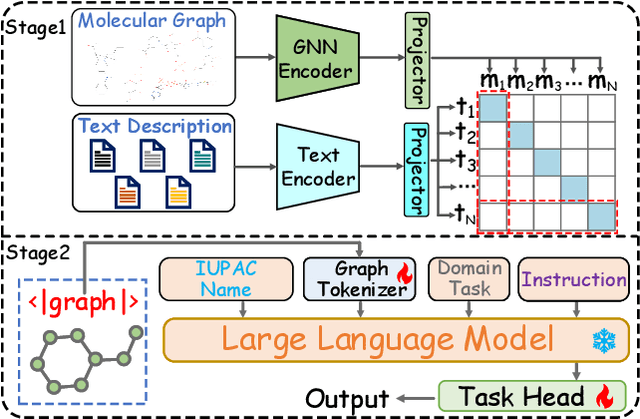
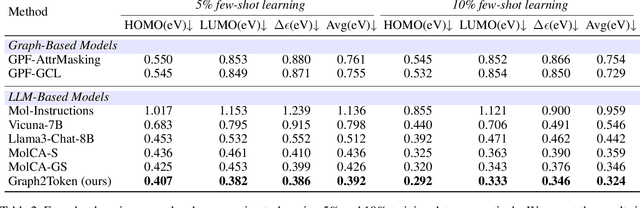
While Large Language Models (LLMs) have shown exceptional generalization capabilities, their ability to process graph data, such as molecular structures, remains limited. To bridge this gap, this paper proposes Graph2Token, an efficient solution that aligns graph tokens to LLM tokens. The key idea is to represent a graph token with the LLM token vocabulary, without fine-tuning the LLM backbone. To achieve this goal, we first construct a molecule-text paired dataset from multisources, including CHEBI and HMDB, to train a graph structure encoder, which reduces the distance between graphs and texts representations in the feature space. Then, we propose a novel alignment strategy that associates a graph token with LLM tokens. To further unleash the potential of LLMs, we collect molecular IUPAC name identifiers, which are incorporated into the LLM prompts. By aligning molecular graphs as special tokens, we can activate LLM generalization ability to molecular few-shot learning. Extensive experiments on molecular classification and regression tasks demonstrate the effectiveness of our proposed Graph2Token.
A General-Purpose Neuromorphic Sensor based on Spiketrum Algorithm: Hardware Details and Real-life Applications
Jan 30, 2025



Spiking Neural Networks (SNNs) offer a biologically inspired computational paradigm, enabling energy-efficient data processing through spike-based information transmission. Despite notable advancements in hardware for SNNs, spike encoding has largely remained software-dependent, limiting efficiency. This paper addresses the need for adaptable and resource-efficient spike encoding hardware by presenting an area-optimized hardware implementation of the Spiketrum algorithm, which encodes time-varying analogue signals into spatiotemporal spike patterns. Unlike earlier performance-optimized designs, which prioritize speed, our approach focuses on reducing hardware footprint, achieving a 52% reduction in Block RAMs (BRAMs), 31% fewer Digital Signal Processing (DSP) slices, and a 6% decrease in Look-Up Tables (LUTs). The proposed implementation has been verified on an FPGA and successfully integrated into an IC using TSMC180 technology. Experimental results demonstrate the system's effectiveness in real-world applications, including sound and ECG classification. This work highlights the trade-offs between performance and resource efficiency, offering a flexible, scalable solution for neuromorphic systems in power-sensitive applications like cochlear implants and neural devices.
ObjectRelator: Enabling Cross-View Object Relation Understanding in Ego-Centric and Exo-Centric Videos
Nov 28, 2024



In this paper, we focus on the Ego-Exo Object Correspondence task, an emerging challenge in the field of computer vision that aims to map objects across ego-centric and exo-centric views. We introduce ObjectRelator, a novel method designed to tackle this task, featuring two new modules: Multimodal Condition Fusion (MCFuse) and SSL-based Cross-View Object Alignment (XObjAlign). MCFuse effectively fuses language and visual conditions to enhance target object localization, while XObjAlign enforces consistency in object representations across views through a self-supervised alignment strategy. Extensive experiments demonstrate the effectiveness of ObjectRelator, achieving state-of-the-art performance on Ego2Exo and Exo2Ego tasks with minimal additional parameters. This work provides a foundation for future research in comprehensive cross-view object relation understanding highlighting the potential of leveraging multimodal guidance and cross-view alignment. Codes and models will be released to advance further research in this direction.
Application based Evaluation of an Efficient Spike-Encoder, "Spiketrum"
May 29, 2024



Spike-based encoders represent information as sequences of spikes or pulses, which are transmitted between neurons. A prevailing consensus suggests that spike-based approaches demonstrate exceptional capabilities in capturing the temporal dynamics of neural activity and have the potential to provide energy-efficient solutions for low-power applications. The Spiketrum encoder efficiently compresses input data using spike trains or code sets (for non-spiking applications) and is adaptable to both hardware and software implementations, with lossless signal reconstruction capability. The paper proposes and assesses Spiketrum's hardware, evaluating its output under varying spike rates and its classification performance with popular spiking and non-spiking classifiers, and also assessing the quality of information compression and hardware resource utilization. The paper extensively benchmarks both Spiketrum hardware and its software counterpart against state-of-the-art, biologically-plausible encoders. The evaluations encompass benchmarking criteria, including classification accuracy, training speed, and sparsity when using encoder outputs in pattern recognition and classification with both spiking and non-spiking classifiers. Additionally, they consider encoded output entropy and hardware resource utilization and power consumption of the hardware version of the encoders. Results demonstrate Spiketrum's superiority in most benchmarking criteria, making it a promising choice for various applications. It efficiently utilizes hardware resources with low power consumption, achieving high classification accuracy. This work also emphasizes the potential of encoders in spike-based processing to improve the efficiency and performance of neural computing systems.
CO3: Low-resource Contrastive Co-training for Generative Conversational Query Rewrite
Mar 18, 2024Generative query rewrite generates reconstructed query rewrites using the conversation history while rely heavily on gold rewrite pairs that are expensive to obtain. Recently, few-shot learning is gaining increasing popularity for this task, whereas these methods are sensitive to the inherent noise due to limited data size. Besides, both attempts face performance degradation when there exists language style shift between training and testing cases. To this end, we study low-resource generative conversational query rewrite that is robust to both noise and language style shift. The core idea is to utilize massive unlabeled data to make further improvements via a contrastive co-training paradigm. Specifically, we co-train two dual models (namely Rewriter and Simplifier) such that each of them provides extra guidance through pseudo-labeling for enhancing the other in an iterative manner. We also leverage contrastive learning with data augmentation, which enables our model pay more attention on the truly valuable information than the noise. Extensive experiments demonstrate the superiority of our model under both few-shot and zero-shot scenarios. We also verify the better generalization ability of our model when encountering language style shift.
How Can Large Language Models Understand Spatial-Temporal Data?
Jan 25, 2024


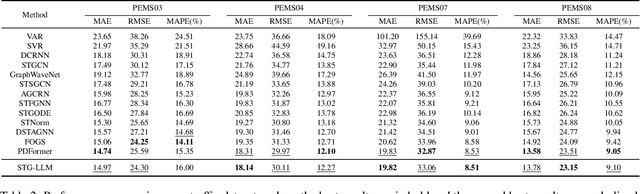
While Large Language Models (LLMs) dominate tasks like natural language processing and computer vision, harnessing their power for spatial-temporal forecasting remains challenging. The disparity between sequential text and complex spatial-temporal data hinders this application. To address this issue, this paper introduces STG-LLM, an innovative approach empowering LLMs for spatial-temporal forecasting. We tackle the data mismatch by proposing: 1) STG-Tokenizer: This spatial-temporal graph tokenizer transforms intricate graph data into concise tokens capturing both spatial and temporal relationships; 2) STG-Adapter: This minimalistic adapter, consisting of linear encoding and decoding layers, bridges the gap between tokenized data and LLM comprehension. By fine-tuning only a small set of parameters, it can effectively grasp the semantics of tokens generated by STG-Tokenizer, while preserving the original natural language understanding capabilities of LLMs. Extensive experiments on diverse spatial-temporal benchmark datasets show that STG-LLM successfully unlocks LLM potential for spatial-temporal forecasting. Remarkably, our approach achieves competitive performance on par with dedicated SOTA methods.