 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRPE: Expanding The Reasoning Capability of Large Language Model for Code Generation
May 15, 2025



We introduce CRPE (Code Reasoning Process Enhancer), an innovative three-stage framework for data synthesis and model training that advances the development of sophisticated code reasoning capabilities in large language models (LLMs). Building upon existing system-1 models, CRPE addresses the fundamental challenge of enhancing LLMs' analytical and logical processing in code generation tasks. Our framework presents a methodologically rigorous yet implementable approach to cultivating advanced code reasoning abilities in language models. Through the implementation of CRPE, we successfully develop an enhanced COT-Coder that demonstrates marked improvements in code generation tasks. Evaluation results on LiveCodeBench (20240701-20240901) demonstrate that our COT-Coder-7B-StepDPO, derived from Qwen2.5-Coder-7B-Base, with a pass@1 accuracy of 21.88, exceeds all models with similar or even larger sizes. Furthermore, our COT-Coder-32B-StepDPO, based on Qwen2.5-Coder-32B-Base, exhibits superior performance with a pass@1 accuracy of 35.08, outperforming GPT4O on the benchmark. Overall, CRPE represents a comprehensive, open-source method that encompasses the complete pipeline from instruction data acquisition through expert code reasoning data synthesis, culminating in an autonomous reasoning enhancement mechanism.
PMMT: Preference Alignment in Multilingual Machine Translation via LLM Distillation
Oct 15, 2024Translation is important for cross-language communication, and many efforts have been made to improve its accuracy. However, less investment is conducted in aligning translations with human preferences, such as translation tones or styles. In this paper, a new method is proposed to effectively generate large-scale multilingual parallel corpora with specific translation preferences using Large Language Models (LLMs). Meanwhile, an automatic pipeline is designed to distill human preferences into smaller Machine Translation (MT) models for efficiently and economically supporting large-scale calls in online services. Experiments indicate that the proposed method takes the lead in translation tasks with aligned human preferences by a large margin. Meanwhile, on popular public benchmarks like WMT and Flores, on which our models were not trained, the proposed method also shows a competitive performance compared to SOTA works.
Building Decision Making Models Through Language Model Regime
Aug 12, 2024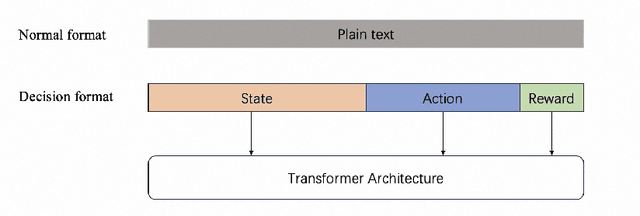
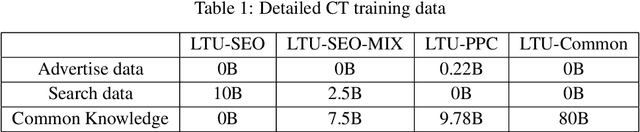
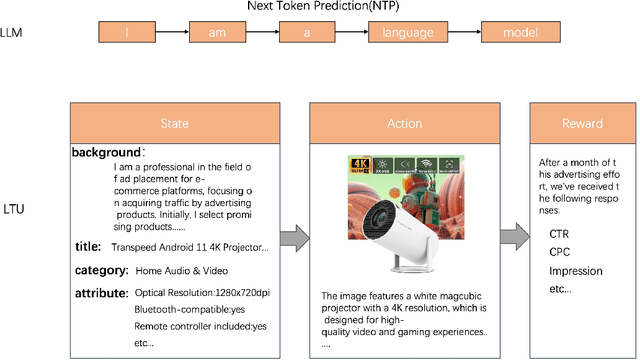

We propose a novel approach for decision making problems leveraging the generalization capabilities of large language models (LLMs). Traditional methods such as expert systems, planning algorithms, and reinforcement learning often exhibit limited generalization, typically requiring the training of new models for each unique task. In contrast, LLMs demonstrate remarkable success in generalizing across varied language tasks, inspiring a new strategy for training decision making models. Our approach, referred to as "Learning then Using" (LTU), entails a two-stage process. Initially, the \textit{learning} phase develops a robust foundational decision making model by integrating diverse knowledge from various domains and decision making contexts. The subsequent \textit{using} phase refines this foundation model for specific decision making scenarios. Distinct from other studies that employ LLMs for decision making through supervised learning, our LTU method embraces a versatile training methodology that combines broad pre-training with targeted fine-tuning. Experiments in e-commerce domains such as advertising and search optimization have shown that LTU approach outperforms traditional supervised learning regimes in decision making capabilities and generalization. The LTU approach is the first practical training architecture for both single-step and multi-step decision making tasks combined with LLMs, which can be applied beyond game and robot domains. It provides a robust and adaptable framework for decision making, enhances the effectiveness and flexibility of various systems in tackling various challenges.
CO3: Low-resource Contrastive Co-training for Generative Conversational Query Rewrite
Mar 18, 2024Generative query rewrite generates reconstructed query rewrites using the conversation history while rely heavily on gold rewrite pairs that are expensive to obtain. Recently, few-shot learning is gaining increasing popularity for this task, whereas these methods are sensitive to the inherent noise due to limited data size. Besides, both attempts face performance degradation when there exists language style shift between training and testing cases. To this end, we study low-resource generative conversational query rewrite that is robust to both noise and language style shift. The core idea is to utilize massive unlabeled data to make further improvements via a contrastive co-training paradigm. Specifically, we co-train two dual models (namely Rewriter and Simplifier) such that each of them provides extra guidance through pseudo-labeling for enhancing the other in an iterative manner. We also leverage contrastive learning with data augmentation, which enables our model pay more attention on the truly valuable information than the noise. Extensive experiments demonstrate the superiority of our model under both few-shot and zero-shot scenarios. We also verify the better generalization ability of our model when encountering language style shift.
A unified multichannel far-field speech recognition system: combining neural beamforming with attention based end-to-end model
Jan 05, 2024Far-field speech recognition is a challenging task that conventionally uses signal processing beamforming to attack noise and interference problem. But the performance has been found usually limited due to heavy reliance on environmental assumption. In this paper, we propose a unified multichannel far-field speech recognition system that combines the neural beamforming and transformer-based Listen, Spell, Attend (LAS) speech recognition system, which extends the end-to-end speech recognition system further to include speech enhancement. Such framework is then jointly trained to optimize the final objective of interest. Specifically, factored complex linear projection (fCLP) has been adopted to form the neural beamforming. Several pooling strategies to combine look directions are then compared in order to find the optimal approach. Moreover, information of the source direction is also integrated in the beamforming to explore the usefulness of source direction as a prior, which is usually available especially in multi-modality scenario. Experiments on different microphone array geometry are conducted to evaluate the robustness against spacing variance of microphone array. Large in-house databases are used to evaluate the effectiveness of the proposed framework and the proposed method achieve 19.26\% improvement when compared with a strong baseline.
Improving Audio-Visual Speech Recognition by Lip-Subword Correlation Based Visual Pre-training and Cross-Modal Fusion Encoder
Aug 14, 2023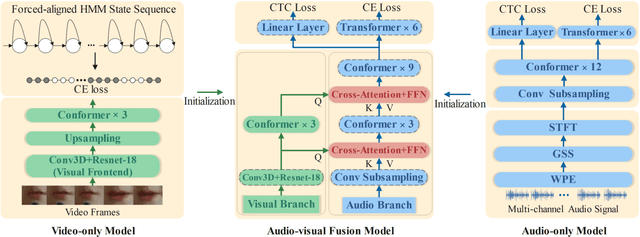
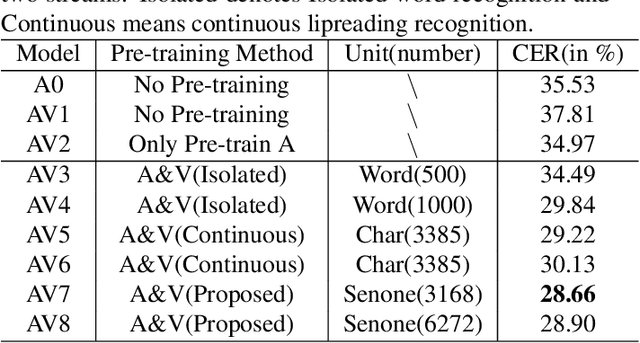
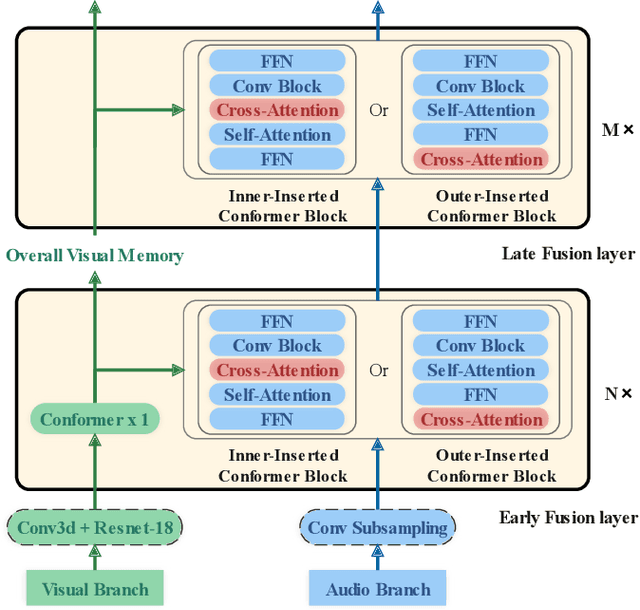
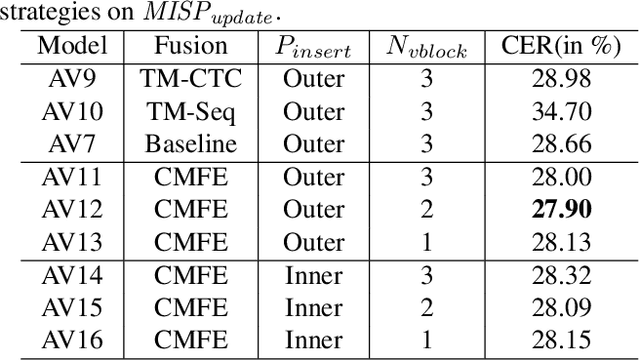
In recent research, slight performance improvement is observed from automatic speech recognition systems to audio-visual speech recognition systems in the end-to-end framework with low-quality videos. Unmatching convergence rates and specialized input representations between audio and visual modalities are considered to cause the problem. In this paper, we propose two novel techniques to improve audio-visual speech recognition (AVSR) under a pre-training and fine-tuning training framework. First, we explore the correlation between lip shapes and syllable-level subword units in Mandarin to establish good frame-level syllable boundaries from lip shapes. This enables accurate alignment of video and audio streams during visual model pre-training and cross-modal fusion. Next, we propose an audio-guided cross-modal fusion encoder (CMFE) neural network to utilize main training parameters for multiple cross-modal attention layers to make full use of modality complementarity. Experiments on the MISP2021-AVSR data set show the effectiveness of the two proposed techniques. Together, using only a relatively small amount of training data, the final system achieves better performances than state-of-the-art systems with more complex front-ends and back-ends.
Network Pruning Spaces
Apr 19, 2023Network pruning techniques, including weight pruning and filter pruning, reveal that most state-of-the-art neural networks can be accelerated without a significant performance drop. This work focuses on filter pruning which enables accelerated inference with any off-the-shelf deep learning library and hardware. We propose the concept of \emph{network pruning spaces} that parametrize populations of subnetwork architectures. Based on this concept, we explore the structure aspect of subnetworks that result in minimal loss of accuracy in different pruning regimes and arrive at a series of observations by comparing subnetwork distributions. We conjecture through empirical studies that there exists an optimal FLOPs-to-parameter-bucket ratio related to the design of original network in a pruning regime. Statistically, the structure of a winning subnetwork guarantees an approximately optimal ratio in this regime. Upon our conjectures, we further refine the initial pruning space to reduce the cost of searching a good subnetwork architecture. Our experimental results on ImageNet show that the subnetwork we found is superior to those from the state-of-the-art pruning methods under comparable FLOPs.
McQueen: a Benchmark for Multimodal Conversational Query Rewrite
Oct 23, 2022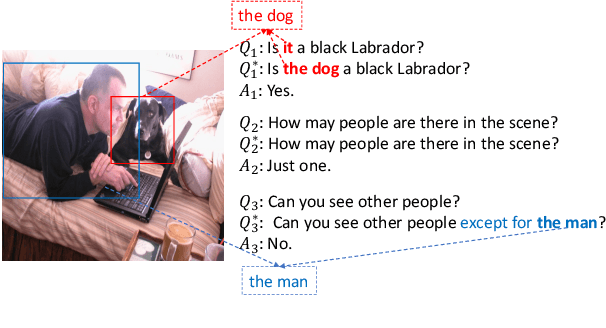
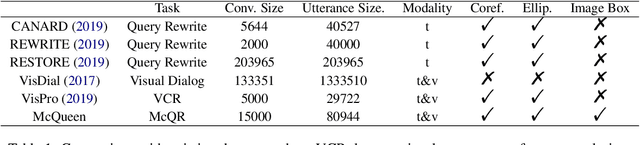

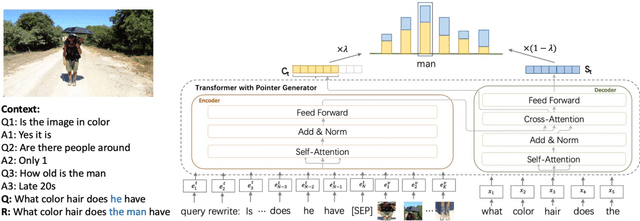
The task of query rewrite aims to convert an in-context query to its fully-specified version where ellipsis and coreference are completed and referred-back according to the history context. Although much progress has been made, less efforts have been paid to real scenario conversations that involve drawing information from more than one modalities. In this paper, we propose the task of multimodal conversational query rewrite (McQR), which performs query rewrite under the multimodal visual conversation setting. We collect a large-scale dataset named McQueen based on manual annotation, which contains 15k visual conversations and over 80k queries where each one is associated with a fully-specified rewrite version. In addition, for entities appearing in the rewrite, we provide the corresponding image box annotation. We then use the McQueen dataset to benchmark a state-of-the-art method for effectively tackling the McQR task, which is based on a multimodal pre-trained model with pointer generator. Extensive experiments are performed to demonstrate the effectiveness of our model on this task\footnote{The dataset and code of this paper are both available in \url{https://github.com/yfyuan01/MQR}
Bootstrap Latent Representations for Multi-modal Recommendation
Jul 13, 2022


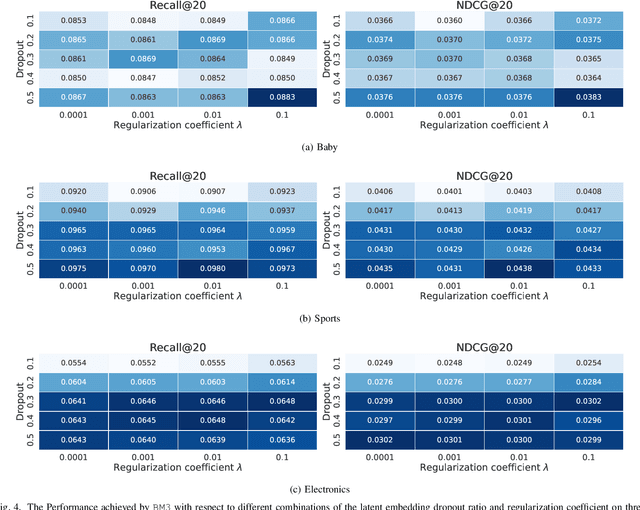
This paper studies the multi-modal recommendation problem, where the item multi-modality information (eg. images and textual descriptions) is exploited to improve the recommendation accuracy. Besides the user-item interaction graph, existing state-of-the-art methods usually use auxiliary graphs (eg. user-user or item-item relation graph) to augment the learned representations of users and/or items. These representations are often propagated and aggregated on auxiliary graphs using graph convolutional networks, which can be prohibitively expensive in computation and memory, especially for large graphs. Moreover, existing multi-modal recommendation methods usually leverage randomly sampled negative examples in Bayesian Personalized Ranking (BPR) loss to guide the learning of user/item representations, which increases the computational cost on large graphs and may also bring noisy supervision signals into the training process. To tackle the above issues, we propose a novel self-supervised multi-modal recommendation model, dubbed BM3, which requires neither augmentations from auxiliary graphs nor negative samples. Specifically, BM3 first bootstraps latent contrastive views from the representations of users and items with a simple dropout augmentation. It then jointly optimizes three multi-modal objectives to learn the representations of users and items by reconstructing the user-item interaction graph and aligning modality features under both inter- and intra-modality perspectives. BM3 alleviates both the need for contrasting with negative examples and the complex graph augmentation from an additional target network for contrastive view generation. We show BM3 outperforms prior recommendation models on three datasets with number of nodes ranging from 20K to 200K, while achieving a 2-9X reduction in training time. Our code is available at https://github.com/enoche/BM3.
iEmoTTS: Toward Robust Cross-Speaker Emotion Transfer and Control for Speech Synthesis based on Disentanglement between Prosody and Timbre
Jun 29, 2022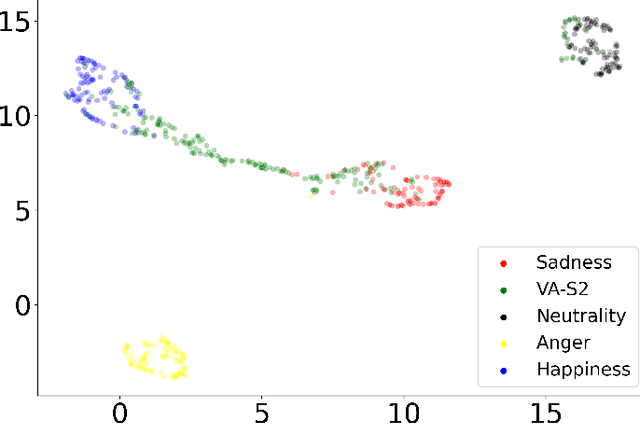
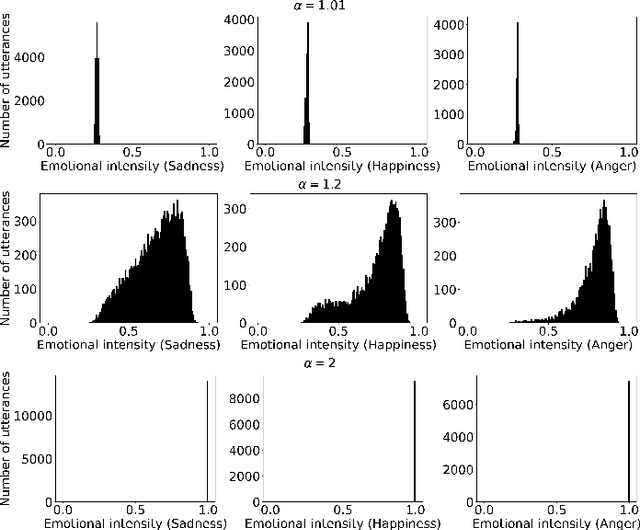
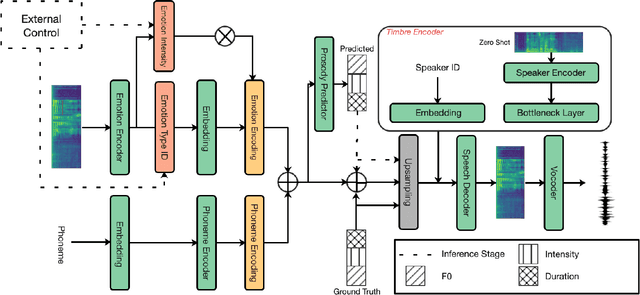
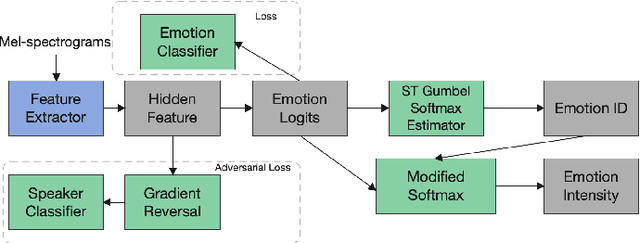
The capability of generating speech with specific type of emotion is desired for many applications of human-computer interaction. Cross-speaker emotion transfer is a common approach to generating emotional speech when speech with emotion labels from target speakers is not available for model training. This paper presents a novel cross-speaker emotion transfer system, named iEmoTTS. The system is composed of an emotion encoder, a prosody predictor, and a timbre encoder. The emotion encoder extracts the identity of emotion type as well as the respective emotion intensity from the mel-spectrogram of input speech. The emotion intensity is measured by the posterior probability that the input utterance carries that emotion. The prosody predictor is used to provide prosodic features for emotion transfer. The timber encoder provides timbre-related information for the system. Unlike many other studies which focus on disentangling speaker and style factors of speech, the iEmoTTS is designed to achieve cross-speaker emotion transfer via disentanglement between prosody and timbre. Prosody is considered as the main carrier of emotion-related speech characteristics and timbre accounts for the essential characteristics for speaker identification. Zero-shot emotion transfer, meaning that speech of target speakers are not seen in model training, is also realized with iEmoTTS. Extensive experiments of subjective evaluation have been carried out. The results demonstrate the effectiveness of iEmoTTS as compared with other recently proposed systems of cross-speaker emotion transfer. It is shown that iEmoTTS can produce speech with designated emotion type and controllable emotion intensity. With appropriate information bottleneck capacity, iEmoTTS is able to effectively transfer emotion information to a new speaker. Audio samples are publicly available\footnote{https://patrick-g-zhang.github.io/iemotts/}.