 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Codec Probing from Semantic and Phonetic Perspectives
Mar 11, 2026Speech tokenizers are essential for connecting speech to large language models (LLMs) in multimodal systems. These tokenizers are expected to preserve both semantic and acoustic information for downstream understanding and generation. However, emerging evidence suggests that what is termed "semantic" in speech representations does not align with text-derived semantics: a mismatch that can degrade multimodal LLM performance. In this paper, we systematically analyze the information encoded by several widely used speech tokenizers, disentangling their semantic and phonetic content through word-level probing tasks, layerwise representation analysis, and cross-modal alignment metrics such as CKA. Our results show that current tokenizers primarily capture phonetic rather than lexical-semantic structure, and we derive practical implications for the design of next-generation speech tokenization methods.
Beyond Video-to-SFX: Video to Audio Synthesis with Environmentally Aware Speech
Sep 19, 2025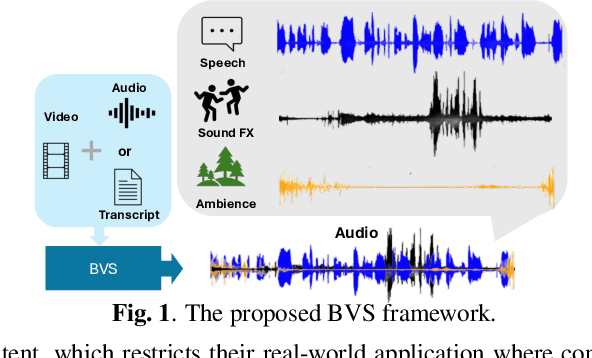



The generation of realistic, context-aware audio is important in real-world applications such as video game development. While existing video-to-audio (V2A) methods mainly focus on Foley sound generation, they struggle to produce intelligible speech. Meanwhile, current environmental speech synthesis approaches remain text-driven and fail to temporally align with dynamic video content. In this paper, we propose Beyond Video-to-SFX (BVS), a method to generate synchronized audio with environmentally aware intelligible speech for given videos. We introduce a two-stage modeling method: (1) stage one is a video-guided audio semantic (V2AS) model to predict unified audio semantic tokens conditioned on phonetic cues; (2) stage two is a video-conditioned semantic-to-acoustic (VS2A) model that refines semantic tokens into detailed acoustic tokens. Experiments demonstrate the effectiveness of BVS in scenarios such as video-to-context-aware speech synthesis and immersive audio background conversion, with ablation studies further validating our design. Our demonstration is available at~\href{https://xinleiniu.github.io/BVS-demo/}{BVS-Demo}.
Gotta Hear Them All: Sound Source Aware Vision to Audio Generation
Nov 26, 2024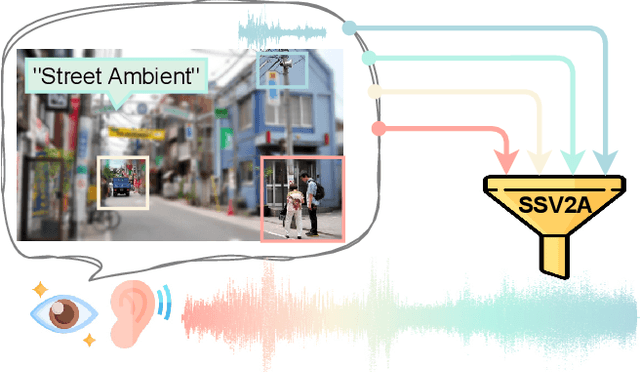
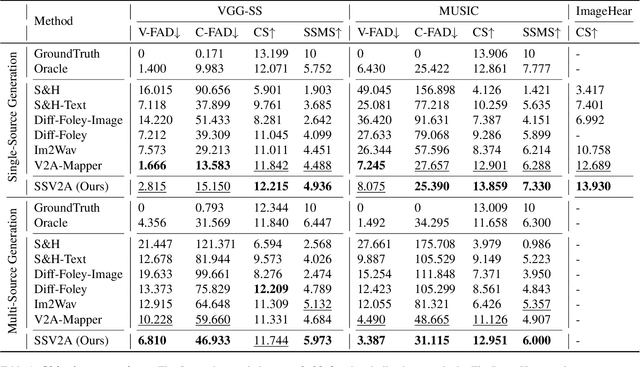
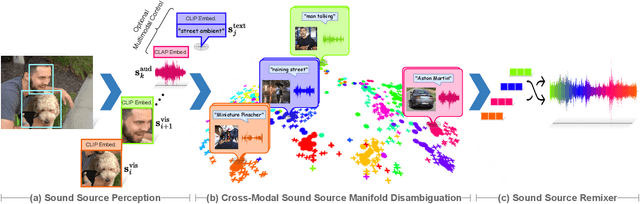
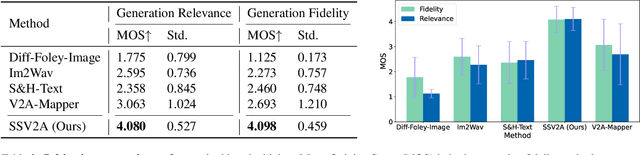
Vision-to-audio (V2A) synthesis has broad applications in multimedia. Recent advancements of V2A methods have made it possible to generate relevant audios from inputs of videos or still images. However, the immersiveness and expressiveness of the generation are limited. One possible problem is that existing methods solely rely on the global scene and overlook details of local sounding objects (i.e., sound sources). To address this issue, we propose a Sound Source-Aware V2A (SSV2A) generator. SSV2A is able to locally perceive multimodal sound sources from a scene with visual detection and cross-modality translation. It then contrastively learns a Cross-Modal Sound Source (CMSS) Manifold to semantically disambiguate each source. Finally, we attentively mix their CMSS semantics into a rich audio representation, from which a pretrained audio generator outputs the sound. To model the CMSS manifold, we curate a novel single-sound-source visual-audio dataset VGGS3 from VGGSound. We also design a Sound Source Matching Score to measure localized audio relevance. This is to our knowledge the first work to address V2A generation at the sound-source level. Extensive experiments show that SSV2A surpasses state-of-the-art methods in both generation fidelity and relevance. We further demonstrate SSV2A's ability to achieve intuitive V2A control by compositing vision, text, and audio conditions. Our SSV2A generation can be tried and heard at https://ssv2a.github.io/SSV2A-demo .
Diff-SAGe: End-to-End Spatial Audio Generation Using Diffusion Models
Oct 15, 2024
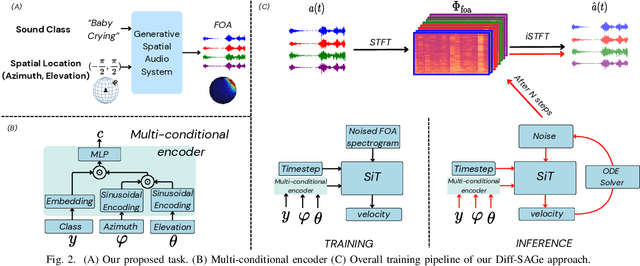
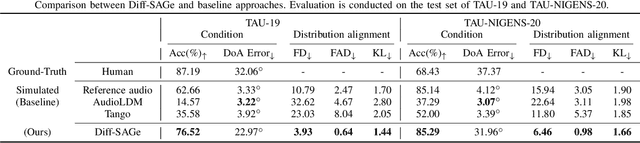
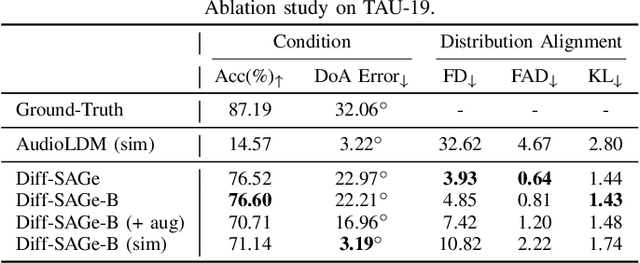
Spatial audio is a crucial component in creating immersive experiences. Traditional simulation-based approaches to generate spatial audio rely on expertise, have limited scalability, and assume independence between semantic and spatial information. To address these issues, we explore end-to-end spatial audio generation. We introduce and formulate a new task of generating first-order Ambisonics (FOA) given a sound category and sound source spatial location. We propose Diff-SAGe, an end-to-end, flow-based diffusion-transformer model for this task. Diff-SAGe utilizes a complex spectrogram representation for FOA, preserving the phase information crucial for accurate spatial cues. Additionally, a multi-conditional encoder integrates the input conditions into a unified representation, guiding the generation of FOA waveforms from noise. Through extensive evaluations on two datasets, we demonstrate that our method consistently outperforms traditional simulation-based baselines across both objective and subjective metrics.
STCMOT: Spatio-Temporal Cohesion Learning for UAV-Based Multiple Object Tracking
Sep 17, 2024



Multiple object tracking (MOT) in Unmanned Aerial Vehicle (UAV) videos is important for diverse applications in computer vision. Current MOT trackers rely on accurate object detection results and precise matching of target reidentification (ReID). These methods focus on optimizing target spatial attributes while overlooking temporal cues in modelling object relationships, especially for challenging tracking conditions such as object deformation and blurring, etc. To address the above-mentioned issues, we propose a novel Spatio-Temporal Cohesion Multiple Object Tracking framework (STCMOT), which utilizes historical embedding features to model the representation of ReID and detection features in a sequential order. Concretely, a temporal embedding boosting module is introduced to enhance the discriminability of individual embedding based on adjacent frame cooperation. While the trajectory embedding is then propagated by a temporal detection refinement module to mine salient target locations in the temporal field. Extensive experiments on the VisDrone2019 and UAVDT datasets demonstrate our STCMOT sets a new state-of-the-art performance in MOTA and IDF1 metrics. The source codes are released at https://github.com/ydhcg-BoBo/STCMOT.
Rethinking Mamba in Speech Processing by Self-Supervised Models
Sep 11, 2024
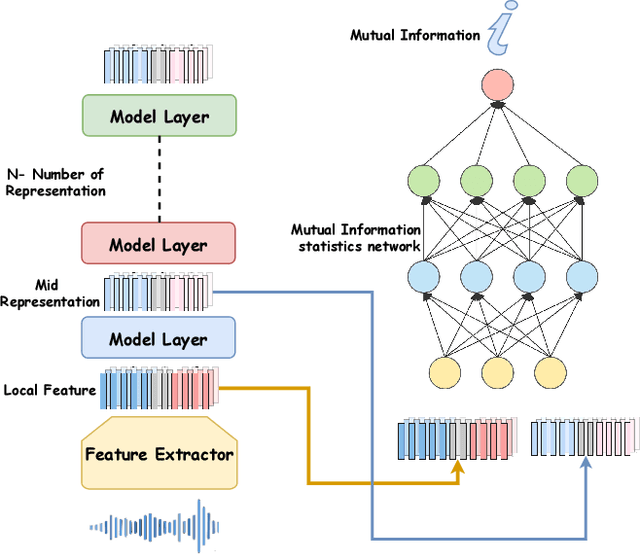
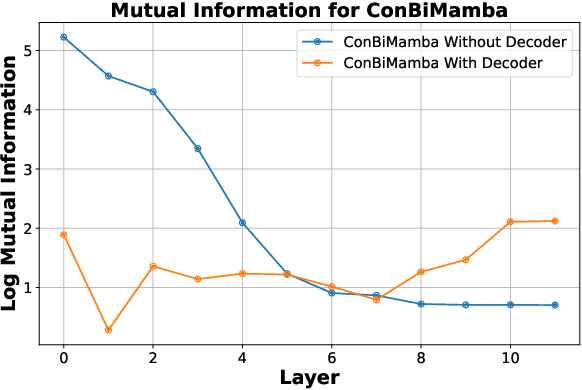
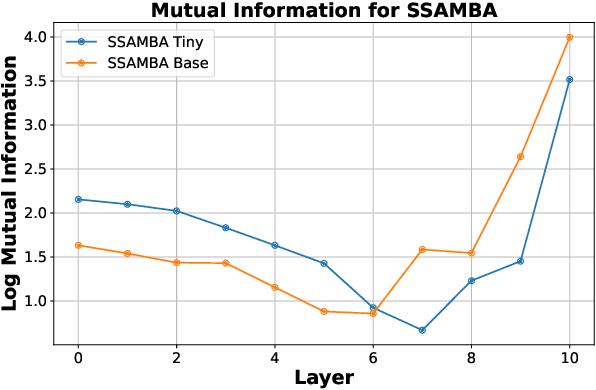
The Mamba-based model has demonstrated outstanding performance across tasks in computer vision, natural language processing, and speech processing. However, in the realm of speech processing, the Mamba-based model's performance varies across different tasks. For instance, in tasks such as speech enhancement and spectrum reconstruction, the Mamba model performs well when used independently. However, for tasks like speech recognition, additional modules are required to surpass the performance of attention-based models. We propose the hypothesis that the Mamba-based model excels in "reconstruction" tasks within speech processing. However, for "classification tasks" such as Speech Recognition, additional modules are necessary to accomplish the "reconstruction" step. To validate our hypothesis, we analyze the previous Mamba-based Speech Models from an information theory perspective. Furthermore, we leveraged the properties of HuBERT in our study. We trained a Mamba-based HuBERT model, and the mutual information patterns, along with the model's performance metrics, confirmed our assumptions.
A unified multichannel far-field speech recognition system: combining neural beamforming with attention based end-to-end model
Jan 05, 2024Far-field speech recognition is a challenging task that conventionally uses signal processing beamforming to attack noise and interference problem. But the performance has been found usually limited due to heavy reliance on environmental assumption. In this paper, we propose a unified multichannel far-field speech recognition system that combines the neural beamforming and transformer-based Listen, Spell, Attend (LAS) speech recognition system, which extends the end-to-end speech recognition system further to include speech enhancement. Such framework is then jointly trained to optimize the final objective of interest. Specifically, factored complex linear projection (fCLP) has been adopted to form the neural beamforming. Several pooling strategies to combine look directions are then compared in order to find the optimal approach. Moreover, information of the source direction is also integrated in the beamforming to explore the usefulness of source direction as a prior, which is usually available especially in multi-modality scenario. Experiments on different microphone array geometry are conducted to evaluate the robustness against spacing variance of microphone array. Large in-house databases are used to evaluate the effectiveness of the proposed framework and the proposed method achieve 19.26\% improvement when compared with a strong baseline.
V2A-Mapper: A Lightweight Solution for Vision-to-Audio Generation by Connecting Foundation Models
Aug 21, 2023Building artificial intelligence (AI) systems on top of a set of foundation models (FMs) is becoming a new paradigm in AI research. Their representative and generative abilities learnt from vast amounts of data can be easily adapted and transferred to a wide range of downstream tasks without extra training from scratch. However, leveraging FMs in cross-modal generation remains under-researched when audio modality is involved. On the other hand, automatically generating semantically-relevant sound from visual input is an important problem in cross-modal generation studies. To solve this vision-to-audio (V2A) generation problem, existing methods tend to design and build complex systems from scratch using modestly sized datasets. In this paper, we propose a lightweight solution to this problem by leveraging foundation models, specifically CLIP, CLAP, and AudioLDM. We first investigate the domain gap between the latent space of the visual CLIP and the auditory CLAP models. Then we propose a simple yet effective mapper mechanism (V2A-Mapper) to bridge the domain gap by translating the visual input between CLIP and CLAP spaces. Conditioned on the translated CLAP embedding, pretrained audio generative FM AudioLDM is adopted to produce high-fidelity and visually-aligned sound. Compared to previous approaches, our method only requires a quick training of the V2A-Mapper. We further analyze and conduct extensive experiments on the choice of the V2A-Mapper and show that a generative mapper is better at fidelity and variability (FD) while a regression mapper is slightly better at relevance (CS). Both objective and subjective evaluation on two V2A datasets demonstrate the superiority of our proposed method compared to current state-of-the-art approaches - trained with 86% fewer parameters but achieving 53% and 19% improvement in FD and CS, respectively.
Low latency transformers for speech processing
Feb 27, 2023



The transformer is a widely-used building block in modern neural networks. However, when applied to audio data, the transformer's acausal behaviour, which we term Acausal Attention (AA), has generally limited its application to offline tasks. In this paper we introduce Streaming Attention (SA), which operates causally with fixed latency, and requires lower compute and memory resources than AA to train. Next, we introduce Low Latency Streaming Attention (LLSA), a method which combines multiple SA layers without latency build-up proportional to the layer count. Comparative analysis between AA, SA and LLSA on Automatic Speech Recognition (ASR) and Speech Emotion Recognition (SER) tasks are presented. The results show that causal SA-based networks with fixed latencies of a few seconds (e.g. 1.8 seconds) and LLSA networks with latencies as short as 300 ms can perform comparably with acausal (AA) networks. We conclude that SA and LLSA methods retain many of the benefits of conventional acausal transformers, but with latency characteristics that make them practical to run in real-time streaming applications.