 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePast, Present, and Future of Spatial Audio and Room Acoustics
Mar 17, 2025The study of spatial audio and room acoustics aims to create immersive audio experiences by modeling the physics and psychoacoustics of how sound behaves in space. In the long history of this research area, various key technologies have been developed based both on theoretical advancements and practical innovations. We highlight historical achievements, initiative activities, recent advancements, and future outlooks in the research area of spatial audio recording and reproduction, and room acoustic simulation, modeling, analysis, and control.
Diff-SAGe: End-to-End Spatial Audio Generation Using Diffusion Models
Oct 15, 2024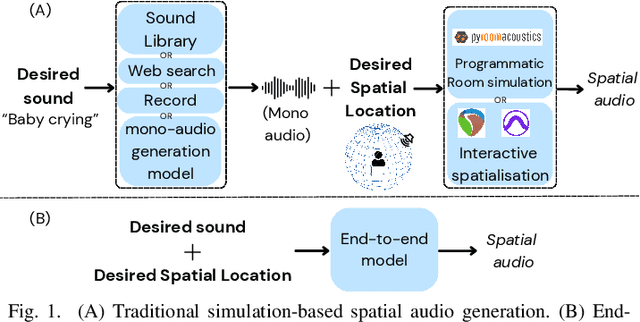
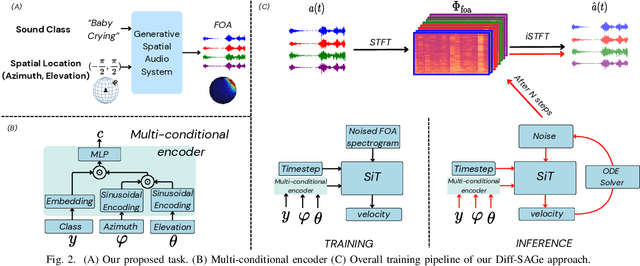
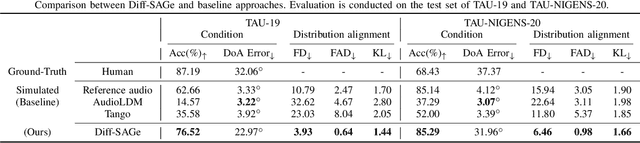
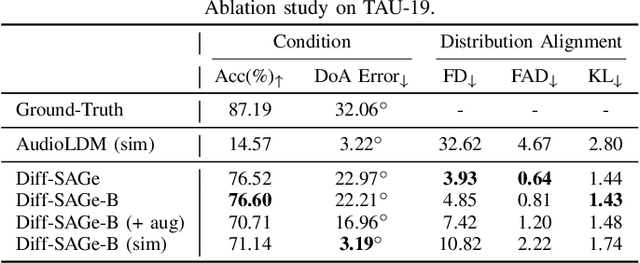
Spatial audio is a crucial component in creating immersive experiences. Traditional simulation-based approaches to generate spatial audio rely on expertise, have limited scalability, and assume independence between semantic and spatial information. To address these issues, we explore end-to-end spatial audio generation. We introduce and formulate a new task of generating first-order Ambisonics (FOA) given a sound category and sound source spatial location. We propose Diff-SAGe, an end-to-end, flow-based diffusion-transformer model for this task. Diff-SAGe utilizes a complex spectrogram representation for FOA, preserving the phase information crucial for accurate spatial cues. Additionally, a multi-conditional encoder integrates the input conditions into a unified representation, guiding the generation of FOA waveforms from noise. Through extensive evaluations on two datasets, we demonstrate that our method consistently outperforms traditional simulation-based baselines across both objective and subjective metrics.
Improved Panning on Non-Equidistant Loudspeakers with Direct Sound Level Compensation
Oct 27, 2023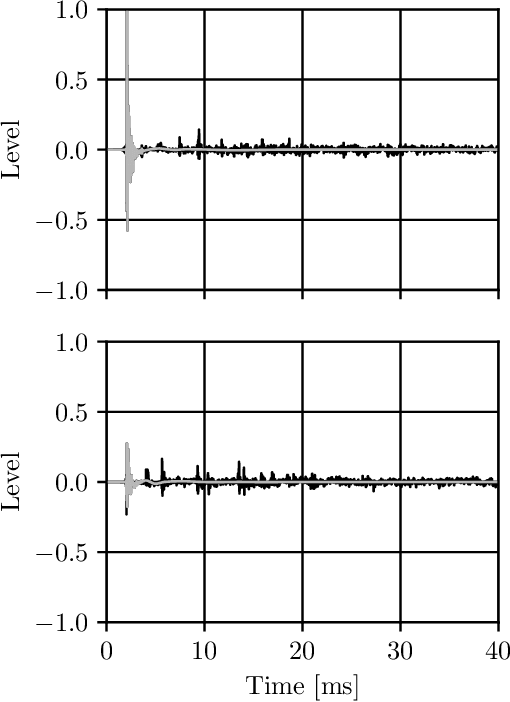
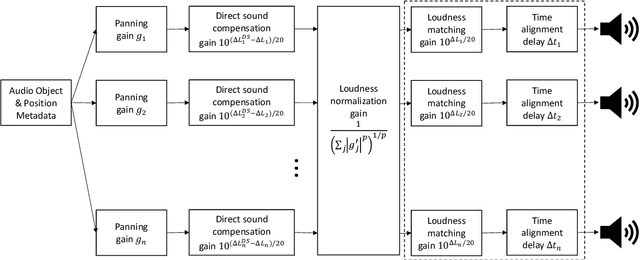
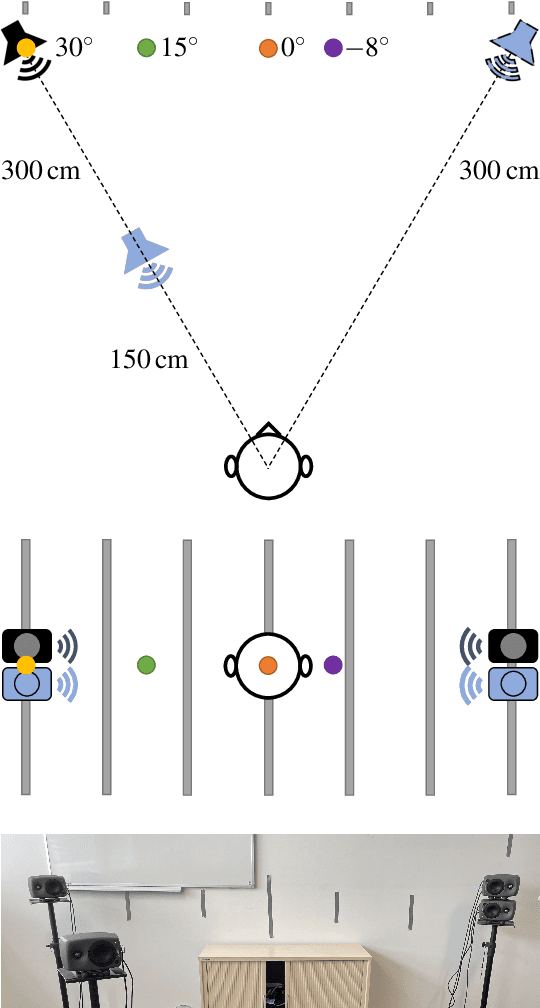
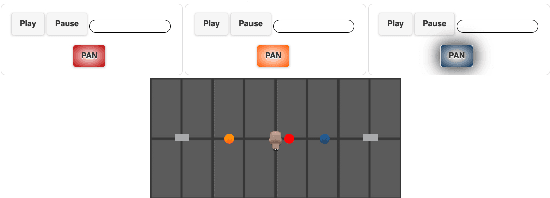
Loudspeaker rendering techniques that create phantom sound sources often assume an equidistant loudspeaker layout. Typical home setups might not fulfill this condition as loudspeakers deviate from canonical positions, thus requiring a corresponding calibration. The standard approach is to compensate for delays and to match the loudness of each loudspeaker at the listener's location. It was found that a shift of the phantom image occurs when this calibration procedure is applied and one of a pair of loudspeakers is significantly closer to the listener than the other. In this paper, a novel approach to panning on non-equidistant loudspeaker layouts is presented whereby the panning position is governed by the direct sound and the perceived loudness is governed by the full impulse response. Subjective listening tests are presented that validate the approach and quantify the perceived effect of the compensation. In a setup where the standard calibration leads to an average error of 10 degrees, the proposed direct sound compensation largely returns the phantom source to its intended position.
* 10 pages. Accepted for presentation in AES Convention 155 (2023)