 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating data replication in text-to-audio generative diffusion models through anti-memorization guidance
Sep 18, 2025A persistent challenge in generative audio models is data replication, where the model unintentionally generates parts of its training data during inference. In this work, we address this issue in text-to-audio diffusion models by exploring the use of anti-memorization strategies. We adopt Anti-Memorization Guidance (AMG), a technique that modifies the sampling process of pre-trained diffusion models to discourage memorization. Our study explores three types of guidance within AMG, each designed to reduce replication while preserving generation quality. We use Stable Audio Open as our backbone, leveraging its fully open-source architecture and training dataset. Our comprehensive experimental analysis suggests that AMG significantly mitigates memorization in diffusion-based text-to-audio generation without compromising audio fidelity or semantic alignment.
Diffused Responsibility: Analyzing the Energy Consumption of Generative Text-to-Audio Diffusion Models
May 12, 2025


Text-to-audio models have recently emerged as a powerful technology for generating sound from textual descriptions. However, their high computational demands raise concerns about energy consumption and environmental impact. In this paper, we conduct an analysis of the energy usage of 7 state-of-the-art text-to-audio diffusion-based generative models, evaluating to what extent variations in generation parameters affect energy consumption at inference time. We also aim to identify an optimal balance between audio quality and energy consumption by considering Pareto-optimal solutions across all selected models. Our findings provide insights into the trade-offs between performance and environmental impact, contributing to the development of more efficient generative audio models.
Physics-Informed Neural Network-Driven Sparse Field Discretization Method for Near-Field Acoustic Holography
May 01, 2025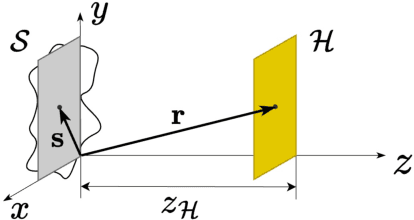
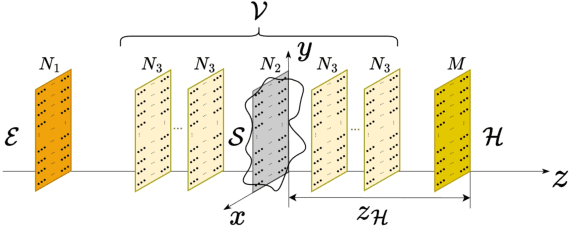
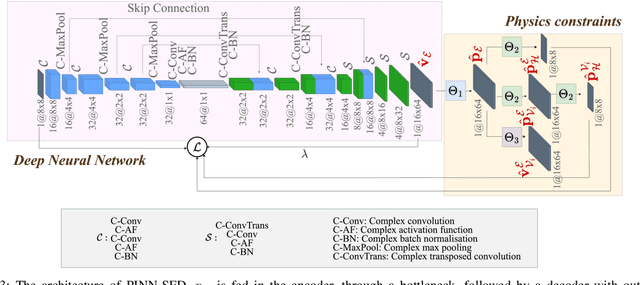
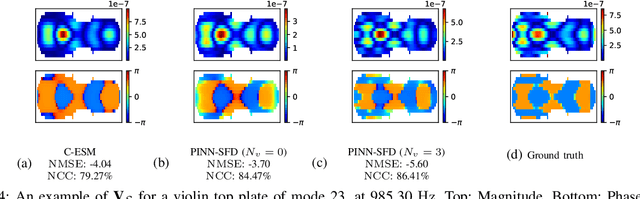
We propose the Physics-Informed Neural Network-driven Sparse Field Discretization method (PINN-SFD), a novel self-supervised, physics-informed deep learning approach for addressing the Near-Field Acoustic Holography (NAH) problem. Unlike existing deep learning methods for NAH, which are predominantly supervised by large datasets, our approach does not require a training phase and it is physics-informed. The wave propagation field is discretized into sparse regions, a process referred to as field discretization, which includes a series of set of source planes, to address the inverse problem. Our method employs the discretized Kirchhoff-Helmholtz integral as the wave propagation model. By incorporating virtual planes, additional constraints are enforced near the actual sound source, improving the reconstruction process. Optimization is carried out using Physics-Informed Neural Networks (PINNs), where physics-based constraints are integrated into the loss functions to account for both direct (from equivalent source plane to hologram plane) and additional (from virtual planes to hologram plane) wave propagation paths. Additionally, sparsity is enforced on the velocity of the equivalent sources. Our comprehensive validation across various rectangular and violin top plates, covering a wide range of vibrational modes, demonstrates that PINN-SFD consistently outperforms the conventional Compressive-Equivalent Source Method (C-ESM), particularly in terms of reconstruction accuracy for complex vibrational patterns. Significantly, this method demonstrates reduced sensitivity to regularization parameters compared to C-ESM.
DiffusionRIR: Room Impulse Response Interpolation using Diffusion Models
Apr 29, 2025Room Impulse Responses (RIRs) characterize acoustic environments and are crucial in multiple audio signal processing tasks. High-quality RIR estimates drive applications such as virtual microphones, sound source localization, augmented reality, and data augmentation. However, obtaining RIR measurements with high spatial resolution is resource-intensive, making it impractical for large spaces or when dense sampling is required. This research addresses the challenge of estimating RIRs at unmeasured locations within a room using Denoising Diffusion Probabilistic Models (DDPM). Our method leverages the analogy between RIR matrices and image inpainting, transforming RIR data into a format suitable for diffusion-based reconstruction. Using simulated RIR data based on the image method, we demonstrate our approach's effectiveness on microphone arrays of different curvatures, from linear to semi-circular. Our method successfully reconstructs missing RIRs, even in large gaps between microphones. Under these conditions, it achieves accurate reconstruction, significantly outperforming baseline Spline Cubic Interpolation in terms of Normalized Mean Square Error and Cosine Distance between actual and interpolated RIRs. This research highlights the potential of using generative models for effective RIR interpolation, paving the way for generating additional data from limited real-world measurements.
Mind the Prompt: Prompting Strategies in Audio Generations for Improving Sound Classification
Apr 04, 2025



This paper investigates the design of effective prompt strategies for generating realistic datasets using Text-To-Audio (TTA) models. We also analyze different techniques for efficiently combining these datasets to enhance their utility in sound classification tasks. By evaluating two sound classification datasets with two TTA models, we apply a range of prompt strategies. Our findings reveal that task-specific prompt strategies significantly outperform basic prompt approaches in data generation. Furthermore, merging datasets generated using different TTA models proves to enhance classification performance more effectively than merely increasing the training dataset size. Overall, our results underscore the advantages of these methods as effective data augmentation techniques using synthetic data.
Past, Present, and Future of Spatial Audio and Room Acoustics
Mar 17, 2025The study of spatial audio and room acoustics aims to create immersive audio experiences by modeling the physics and psychoacoustics of how sound behaves in space. In the long history of this research area, various key technologies have been developed based both on theoretical advancements and practical innovations. We highlight historical achievements, initiative activities, recent advancements, and future outlooks in the research area of spatial audio recording and reproduction, and room acoustic simulation, modeling, analysis, and control.
Towards HRTF Personalization using Denoising Diffusion Models
Jan 06, 2025
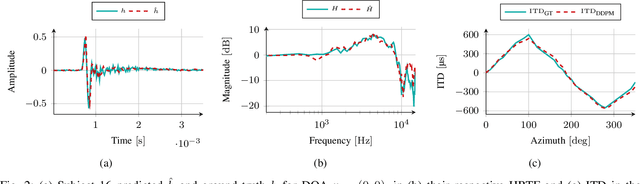
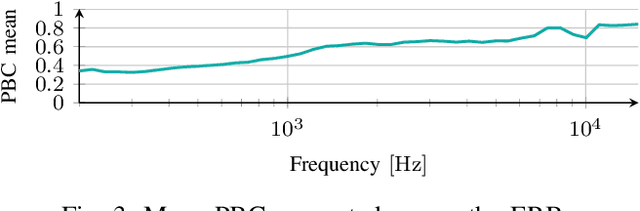
Head-Related Transfer Functions (HRTFs) have fundamental applications for realistic rendering in immersive audio scenarios. However, they are strongly subject-dependent as they vary considerably depending on the shape of the ears, head and torso. Thus, personalization procedures are required for accurate binaural rendering. Recently, Denoising Diffusion Probabilistic Models (DDPMs), a class of generative learning techniques, have been applied to solve a variety of signal processing-related problems. In this paper, we propose a first approach for using DDPM conditioned on anthropometric measurements to generate personalized Head-Related Impulse Response (HRIR), the time-domain representation of HRTF. The results show the feasibility of DDPMs for HRTF personalization obtaining performance in line with state-of-the-art models.
A Zero-Shot Physics-Informed Dictionary Learning Approach for Sound Field Reconstruction
Dec 24, 2024


Sound field reconstruction aims to estimate pressure fields in areas lacking direct measurements. Existing techniques often rely on strong assumptions or face challenges related to data availability or the explicit modeling of physical properties. To bridge these gaps, this study introduces a zero-shot, physics-informed dictionary learning approach to perform sound field reconstruction. Our method relies only on a few sparse measurements to learn a dictionary, without the need for additional training data. Moreover, by enforcing the Helmholtz equation during the optimization process, the proposed approach ensures that the reconstructed sound field is represented as a linear combination of a few physically meaningful atoms. Evaluations on real-world data show that our approach achieves comparable performance to state-of-the-art dictionary learning techniques, with the advantage of requiring only a few observations of the sound field and no training on a dataset.
MambaFoley: Foley Sound Generation using Selective State-Space Models
Sep 13, 2024



Recent advancements in deep learning have led to widespread use of techniques for audio content generation, notably employing Denoising Diffusion Probabilistic Models (DDPM) across various tasks. Among these, Foley Sound Synthesis is of particular interest for its role in applications for the creation of multimedia content. Given the temporal-dependent nature of sound, it is crucial to design generative models that can effectively handle the sequential modeling of audio samples. Selective State Space Models (SSMs) have recently been proposed as a valid alternative to previously proposed techniques, demonstrating competitive performance with lower computational complexity. In this paper, we introduce MambaFoley, a diffusion-based model that, to the best of our knowledge, is the first to leverage the recently proposed SSM known as Mamba for the Foley sound generation task. To evaluate the effectiveness of the proposed method, we compare it with a state-of-the-art Foley sound generative model using both objective and subjective analyses.
A Physics-Informed Neural Network-Based Approach for the Spatial Upsampling of Spherical Microphone Arrays
Jul 26, 2024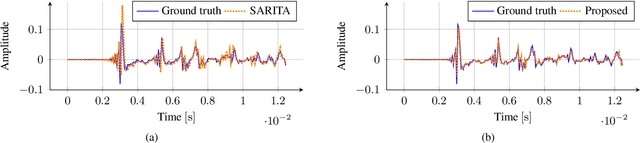
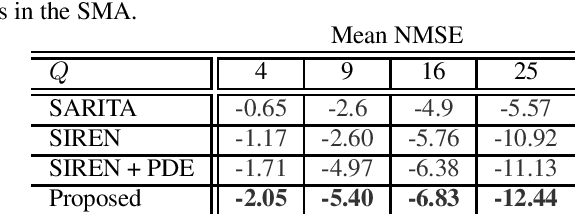
Spherical microphone arrays are convenient tools for capturing the spatial characteristics of a sound field. However, achieving superior spatial resolution requires arrays with numerous capsules, consequently leading to expensive devices. To address this issue, we present a method for spatially upsampling spherical microphone arrays with a limited number of capsules. Our approach exploits a physics-informed neural network with Rowdy activation functions, leveraging physical constraints to provide high-order microphone array signals, starting from low-order devices. Results show that, within its domain of application, our approach outperforms a state of the art method based on signal processing for spherical microphone arrays upsampling.