 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Multichannel Wiener Filtering for Wireless Acoustic Sensor Networks
Mar 10, 2026In a wireless acoustic sensor network (WASN), devices (i.e., nodes) can collaborate through distributed algorithms to collectively perform audio signal processing tasks. This paper focuses on the distributed estimation of node-specific desired speech signals using network-wide Wiener filtering. The objective is to match the performance of a centralized system that would have access to all microphone signals, while reducing the communication bandwidth usage of the algorithm. Existing solutions, such as the distributed adaptive node-specific signal estimation (DANSE) algorithm, converge towards the multichannel Wiener filter (MWF) which solves a centralized linear minimum mean square error (LMMSE) signal estimation problem. However, they do so iteratively, which can be slow and impractical. Many solutions also assume that all nodes observe the same set of sources of interest, which is often not the case in practice. To overcome these limitations, we propose the distributed multichannel Wiener filter (dMWF) for fully connected WASNs. The dMWF is non-iterative and optimal even when nodes observe different sets of sources. In this algorithm, nodes exchange neighbor-pair-specific, low-dimensional (fused) signals estimating the contribution of sources observed by both nodes in the pair. We formally prove the optimality of dMWF and demonstrate its performance in simulated speech enhancement experiments. The proposed algorithm is shown to outperform DANSE in terms of objective metrics after short operation times, highlighting the benefit of its iterationless design.
Accelerated Interactive Auralization of Highly Reverberant Spaces using Graphics Hardware
Sep 04, 2025



Interactive acoustic auralization allows users to explore virtual acoustic environments in real-time, enabling the acoustic recreation of concert hall or Historical Worship Spaces (HWS) that are either no longer accessible, acoustically altered, or impractical to visit. Interactive acoustic synthesis requires real-time convolution of input signals with a set of synthesis filters that model the space-time acoustic response of the space. The acoustics in concert halls and HWS are both characterized by a long reverberation time, resulting in synthesis filters containing many filter taps. As a result, the convolution process can be computationally demanding, introducing significant latency that limits the real-time interactivity of the auralization system. In this paper, the implementation of a real-time multichannel loudspeaker-based auralization system is presented. This system is capable of synthesizing the acoustics of highly reverberant spaces in real-time using GPU-acceleration. A comparison between traditional CPU-based convolution and GPU-accelerated convolution is presented, showing that the latter can achieve real-time performance with significantly lower latency. Additionally, the system integrates acoustic synthesis with acoustic feedback cancellation on the GPU, creating a unified loudspeaker-based auralization framework that minimizes processing latency.
On Time Delay Interpolation for Improved Acoustic Reflector Localization
Sep 04, 2025



The localization of acoustic reflectors is a fundamental component in various applications, including room acoustics analysis, sound source localization, and acoustic scene analysis. Time Delay Estimation (TDE) is essential for determining the position of reflectors relative to a sensor array. Traditional TDE algorithms generally yield time delays that are integer multiples of the operating sampling period, potentially lacking sufficient time resolution. To achieve subsample TDE accuracy, various interpolation methods, including parabolic, Gaussian, frequency, and sinc interpolation, have been proposed. This paper presents a comprehensive study on time delay interpolation to achieve subsample accuracy for acoustic reflector localization in reverberant conditions. We derive the Whittaker-Shannon interpolation formula from the previously proposed sinc interpolation in the context of short-time windowed TDE for acoustic reflector localization. Simulations show that sinc and Whittaker-Shannon interpolation outperform existing methods in terms of time delay error and positional error for critically sampled and band-limited reflections. Performance is evaluated on real-world measurements from the MYRiAD dataset, showing that sinc and Whittaker-Shannon interpolation consistently provide reliable performance across different sensor-source pairs and loudspeaker positions. These results can enhance the precision of acoustic reflector localization systems, vital for applications such as room acoustics analysis, sound source localization, and acoustic scene analysis.
Tracking of Spatially Dynamic Room Impulse Responses Along Locally Linearized Trajectories
Jun 13, 2025Measuring room impulse responses (RIRs) at multiple spatial points is a time-consuming task, while simulations require detailed knowledge of the room's acoustic environment. In prior work, we proposed a method for estimating the early part of RIRs along a linear trajectory in a time-varying acoustic scenario involving a static sound source and a microphone moving at constant velocity. This approach relies on measured RIRs at the start and end points of the trajectory and assumes that the time intervals occupied by the direct sound and individual reflections along the trajectory are non-overlapping. The method's applicability is therefore restricted to relatively small areas within a room, and its performance has yet to be validated with real-world data. In this paper, we propose a practical extension of the method to more realistic scenarios by segmenting longer trajectories into smaller linear intervals where the assumptions approximately hold. Applying the method piecewise along these segments extends its applicability to more complex room environments. We demonstrate its effectiveness using the trajectoRIR database, which includes moving microphone recordings and RIR measurements at discrete points along a controlled L-shaped trajectory in a real room.
Sound Field Reconstruction Using Physics-Informed Boundary Integral Networks
Jun 04, 2025



Sound field reconstruction refers to the problem of estimating the acoustic pressure field over an arbitrary region of space, using only a limited set of measurements. Physics-informed neural networks have been adopted to solve the problem by incorporating in the training loss function the governing partial differential equation, either the Helmholtz or the wave equation. In this work, we introduce a boundary integral network for sound field reconstruction. Relying on the Kirchhoff-Helmholtz boundary integral equation to model the sound field in a given region of space, we employ a shallow neural network to retrieve the pressure distribution on the boundary of the considered domain, enabling to accurately retrieve the acoustic pressure inside of it. Assuming the positions of measurement microphones are known, we train the model by minimizing the mean squared error between the estimated and measured pressure at those locations. Experimental results indicate that the proposed model outperforms existing physics-informed data-driven techniques.
Deep, data-driven modeling of room acoustics: literature review and research perspectives
Apr 22, 2025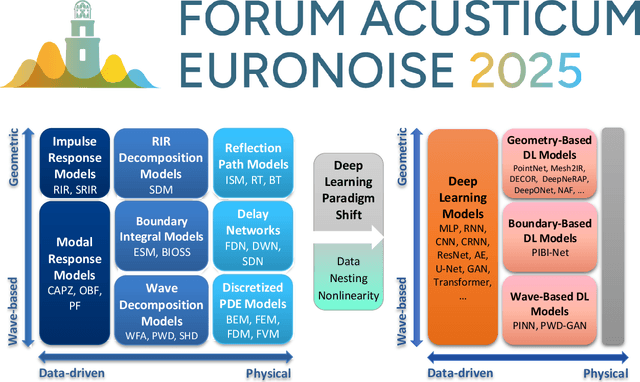
Our everyday auditory experience is shaped by the acoustics of the indoor environments in which we live. Room acoustics modeling is aimed at establishing mathematical representations of acoustic wave propagation in such environments. These representations are relevant to a variety of problems ranging from echo-aided auditory indoor navigation to restoring speech understanding in cocktail party scenarios. Many disciplines in science and engineering have recently witnessed a paradigm shift powered by deep learning (DL), and room acoustics research is no exception. The majority of deep, data-driven room acoustics models are inspired by DL-based speech and image processing, and hence lack the intrinsic space-time structure of acoustic wave propagation. More recently, DL-based models for room acoustics that include either geometric or wave-based information have delivered promising results, primarily for the problem of sound field reconstruction. In this review paper, we will provide an extensive and structured literature review on deep, data-driven modeling in room acoustics. Moreover, we position these models in a framework that allows for a conceptual comparison with traditional physical and data-driven models. Finally, we identify strengths and shortcomings of deep, data-driven room acoustics models and outline the main challenges for further research.
The trajectoRIR Database: Room Acoustic Recordings Along a Trajectory of Moving Microphones
Mar 29, 2025



Data availability is essential to develop acoustic signal processing algorithms, especially when it comes to data-driven approaches that demand large and diverse training datasets. For this reason, an increasing number of databases have been published in recent years, including either room impulse responses (RIRs) or recordings of moving audio. In this paper we introduce the trajectoRIR database, an extensive, multi-array collection of both dynamic and stationary acoustic recordings along a controlled trajectory in a room. Specifically, the database features recordings using moving microphones and stationary RIRs spatially sampling the room acoustics along an L-shaped, 3.74-meter-long trajectory. This combination makes trajectoRIR unique and applicable in various tasks ranging from sound source localization and tracking to spatially dynamic sound field reconstruction and system identification. The recording room has a reverberation time of 0.5 seconds, and the three different microphone configurations employed include a dummy head, with additional reference microphones located next to the ears, 3 first-order Ambisonics microphones, two circular arrays of 16 and 4 channels, and a 12-channel linear array. The motion of the microphones was achieved using a robotic cart traversing a rail at three speeds: [0.2,0.4,0.8] m/s. Audio signals were reproduced using two stationary loudspeakers. The collected database features 8648 stationary RIRs, as well as perfect sweeps, speech, music, and stationary noise recorded during motion. MATLAB and Python scripts are included to access the recorded audio as well as to retrieve geometrical information.
A Comparative Analysis of Generalised Echo and Interference Cancelling and Extended Multichannel Wiener Filtering for Combined Noise Reduction and Acoustic Echo Cancellation
Mar 05, 2025
Two algorithms for combined acoustic echo cancellation (AEC) and noise reduction (NR) are analysed, namely the generalised echo and interference canceller (GEIC) and the extended multichannel Wiener filter (MWFext). Previously, these algorithms have been examined for linear echo paths, and assuming access to voice activity detectors (VADs) that separately detect desired speech and echo activity. However, algorithms implementing VADs may introduce detection errors. Therefore, in this paper, the previous analyses are extended by 1) modelling general nonlinear echo paths by means of the generalised Bussgang decomposition, and 2) modelling VAD error effects in each specific algorithm, thereby also allowing to model specific VAD assumptions. It is found and verified with simulations that, generally, the MWFext achieves a higher NR performance, while the GEIC achieves a more robust AEC performance.
A Zero-Shot Physics-Informed Dictionary Learning Approach for Sound Field Reconstruction
Dec 24, 2024


Sound field reconstruction aims to estimate pressure fields in areas lacking direct measurements. Existing techniques often rely on strong assumptions or face challenges related to data availability or the explicit modeling of physical properties. To bridge these gaps, this study introduces a zero-shot, physics-informed dictionary learning approach to perform sound field reconstruction. Our method relies only on a few sparse measurements to learn a dictionary, without the need for additional training data. Moreover, by enforcing the Helmholtz equation during the optimization process, the proposed approach ensures that the reconstructed sound field is represented as a linear combination of a few physically meaningful atoms. Evaluations on real-world data show that our approach achieves comparable performance to state-of-the-art dictionary learning techniques, with the advantage of requiring only a few observations of the sound field and no training on a dataset.
Integrated Minimum Mean Squared Error Algorithms for Combined Acoustic Echo Cancellation and Noise Reduction
Dec 05, 2024



In many speech recording applications, noise and acoustic echo corrupt the desired speech. Consequently, combined noise reduction (NR) and acoustic echo cancellation (AEC) is required. Generally, a cascade approach is followed, i.e., the AEC and NR are designed in isolation by selecting a separate signal model, formulating a separate cost function, and using a separate solution strategy. The AEC and NR are then cascaded one after the other, not accounting for their interaction. In this paper, however, an integrated approach is proposed to consider this interaction in a general multi-microphone/multi-loudspeaker setup. Therefore, a single signal model of either the microphone signal vector or the extended signal vector, obtained by stacking microphone and loudspeaker signals, is selected, a single mean squared error cost function is formulated, and a common solution strategy is used. Using this microphone signal model, a multi channel Wiener filter (MWF) is derived. Using the extended signal model, an extended MWF (MWFext) is derived, and several equivalent expressions are found, which nevertheless are interpretable as cascade algorithms. Specifically, the MWFext is shown to be equivalent to algorithms where the AEC precedes the NR (AEC NR), the NR precedes the AEC (NR-AEC), and the extended NR (NRext) precedes the AEC and post-filter (PF) (NRext-AECPF). Under rank-deficiency conditions the MWFext is non-unique, such that this equivalence amounts to the expressions being specific, not necessarily minimum-norm solutions for this MWFext. The practical performances nonetheless differ due to non-stationarities and imperfect correlation matrix estimation, resulting in the AEC-NR and NRext-AEC-PF attaining best overall performance.