 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Multichannel Wiener Filtering for Wireless Acoustic Sensor Networks
Mar 10, 2026In a wireless acoustic sensor network (WASN), devices (i.e., nodes) can collaborate through distributed algorithms to collectively perform audio signal processing tasks. This paper focuses on the distributed estimation of node-specific desired speech signals using network-wide Wiener filtering. The objective is to match the performance of a centralized system that would have access to all microphone signals, while reducing the communication bandwidth usage of the algorithm. Existing solutions, such as the distributed adaptive node-specific signal estimation (DANSE) algorithm, converge towards the multichannel Wiener filter (MWF) which solves a centralized linear minimum mean square error (LMMSE) signal estimation problem. However, they do so iteratively, which can be slow and impractical. Many solutions also assume that all nodes observe the same set of sources of interest, which is often not the case in practice. To overcome these limitations, we propose the distributed multichannel Wiener filter (dMWF) for fully connected WASNs. The dMWF is non-iterative and optimal even when nodes observe different sets of sources. In this algorithm, nodes exchange neighbor-pair-specific, low-dimensional (fused) signals estimating the contribution of sources observed by both nodes in the pair. We formally prove the optimality of dMWF and demonstrate its performance in simulated speech enhancement experiments. The proposed algorithm is shown to outperform DANSE in terms of objective metrics after short operation times, highlighting the benefit of its iterationless design.
DNN-Based Online Source Counting Based on Spatial Generalized Magnitude Squared Coherence
Jan 28, 2026The number of active sound sources is a key parameter in many acoustic signal processing tasks, such as source localization, source separation, and multi-microphone speech enhancement. This paper proposes a novel method for online source counting by detecting changes in the number of active sources based on spatial coherence. The proposed method exploits the fact that a single coherent source in spatially white background noise yields high spatial coherence, whereas only noise results in low spatial coherence. By applying a spatial whitening operation, the source counting problem is reformulated as a change detection task, aiming to identify the time frames when the number of active sources changes. The method leverages the generalized magnitude-squared coherence as a measure to quantify spatial coherence, providing features for a compact neural network trained to detect source count changes framewise. Simulation results with binaural hearing aids in reverberant acoustic scenes with up to 4 speakers and background noise demonstrate the effectiveness of the proposed method for online source counting.
Reference Microphone Selection for Guided Source Separation based on the Normalized L-p Norm
Oct 31, 2025



Guided Source Separation (GSS) is a popular front-end for distant automatic speech recognition (ASR) systems using spatially distributed microphones. When considering spatially distributed microphones, the choice of reference microphone may have a large influence on the quality of the output signal and the downstream ASR performance. In GSS-based speech enhancement, reference microphone selection is typically performed using the signal-to-noise ratio (SNR), which is optimal for noise reduction but may neglect differences in early-to-late-reverberant ratio (ELR) across microphones. In this paper, we propose two reference microphone selection methods for GSS-based speech enhancement that are based on the normalized $\ell_p$-norm, either using only the normalized $\ell_p$-norm or combining the normalized $\ell_p$-norm and the SNR to account for both differences in SNR and ELR across microphones. Experimental evaluation using a CHiME-8 distant ASR system shows that the proposed $\ell_p$-norm-based methods outperform the baseline method, reducing the macro-average word error rate.
I-DCCRN-VAE: An Improved Deep Representation Learning Framework for Complex VAE-based Single-channel Speech Enhancement
Oct 14, 2025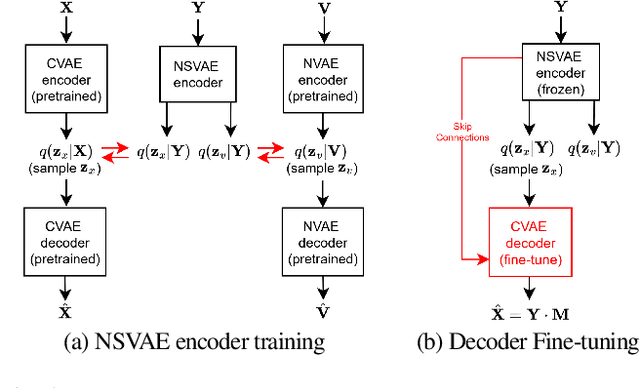
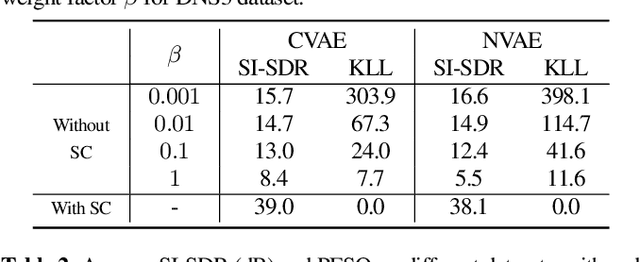

Recently, a complex variational autoencoder (VAE)-based single-channel speech enhancement system based on the DCCRN architecture has been proposed. In this system, a noise suppression VAE (NSVAE) learns to extract clean speech representations from noisy speech using pretrained clean speech and noise VAEs with skip connections. In this paper, we improve DCCRN-VAE by incorporating three key modifications: 1) removing the skip connections in the pretrained VAEs to encourage more informative speech and noise latent representations; 2) using $\beta$-VAE in pretraining to better balance reconstruction and latent space regularization; and 3) a NSVAE generating both speech and noise latent representations. Experiments show that the proposed system achieves comparable performance as the DCCRN and DCCRN-VAE baselines on the matched DNS3 dataset but outperforms the baselines on mismatched datasets (WSJ0-QUT, Voicebank-DEMEND), demonstrating improved generalization ability. In addition, an ablation study shows that a similar performance can be achieved with classical fine-tuning instead of adversarial training, resulting in a simpler training pipeline.
A Steered Response Power Method for Sound Source Localization With Generic Acoustic Models
Sep 19, 2025The steered response power (SRP) method is one of the most popular approaches for acoustic source localization with microphone arrays. It is often based on simplifying acoustic assumptions, such as an omnidirectional sound source in the far field of the microphone array(s), free field propagation, and spatially uncorrelated noise. In reality, however, there are many acoustic scenarios where such assumptions are violated. This paper proposes a generalization of the conventional SRP method that allows to apply generic acoustic models for localization with arbitrary microphone constellations. These models may consider, for instance, level differences in distributed microphones, the directivity of sources and receivers, or acoustic shadowing effects. Moreover, also measured acoustic transfer functions may be applied as acoustic model. We show that the delay-and-sum beamforming of the conventional SRP is not optimal for localization with generic acoustic models. To this end, we propose a generalized SRP beamforming criterion that considers generic acoustic models and spatially correlated noise, and derive an optimal SRP beamformer. Furthermore, we propose and analyze appropriate frequency weightings. Unlike the conventional SRP, the proposed method can jointly exploit observed level and time differences between the microphone signals to infer the source location. Realistic simulations of three different microphone setups with speech under various noise conditions indicate that the proposed method can significantly reduce the mean localization error compared to the conventional SRP and, in particular, a reduction of more than 60% can be archived in noisy conditions.
Investigation of Speech and Noise Latent Representations in Single-channel VAE-based Speech Enhancement
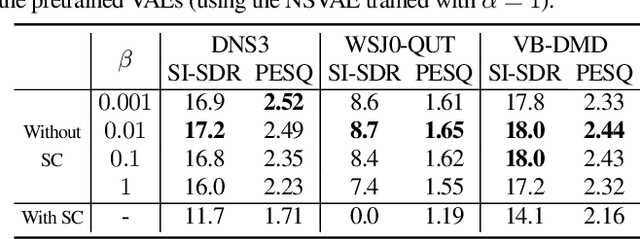
Aug 07, 2025Recently, a variational autoencoder (VAE)-based single-channel speech enhancement system using Bayesian permutation training has been proposed, which uses two pretrained VAEs to obtain latent representations for speech and noise. Based on these pretrained VAEs, a noisy VAE learns to generate speech and noise latent representations from noisy speech for speech enhancement. Modifying the pretrained VAE loss terms affects the pretrained speech and noise latent representations. In this paper, we investigate how these different representations affect speech enhancement performance. Experiments on the DNS3, WSJ0-QUT, and VoiceBank-DEMAND datasets show that a latent space where speech and noise representations are clearly separated significantly improves performance over standard VAEs, which produce overlapping speech and noise representations.
Closed-Form Successive Relative Transfer Function Vector Estimation based on Blind Oblique Projection Incorporating Noise Whitening
Aug 06, 2025Relative transfer functions (RTFs) of sound sources play a crucial role in beamforming, enabling effective noise and interference suppression. This paper addresses the challenge of online estimating the RTF vectors of multiple sound sources in noisy and reverberant environments, for the specific scenario where sources activate successively. While the RTF vector of the first source can be estimated straightforwardly, the main challenge arises in estimating the RTF vectors of subsequent sources during segments where multiple sources are simultaneously active. The blind oblique projection (BOP) method has been proposed to estimate the RTF vector of a newly activating source by optimally blocking this source. However, this method faces several limitations: high computational complexity due to its reliance on iterative gradient descent optimization, the introduction of random additional vectors, which can negatively impact performance, and the assumption of high signal-to-noise ratio (SNR). To overcome these limitations, in this paper we propose three extensions to the BOP method. First, we derive a closed-form solution for optimizing the BOP cost function, significantly reducing computational complexity. Second, we introduce orthogonal additional vectors instead of random vectors, enhancing RTF vector estimation accuracy. Third, we incorporate noise handling techniques inspired by covariance subtraction and whitening, increasing robustness in low SNR conditions. To provide a frame-by-frame estimate of the source activity pattern, required by both the conventional BOP method and the proposed method, we propose a spatial-coherence-based online source counting method. Simulations are performed with real-world reverberant noisy recordings featuring 3 successively activating speakers, with and without a-priori knowledge of the source activity pattern.
Binaural Localization Model for Speech in Noise
Jul 26, 2025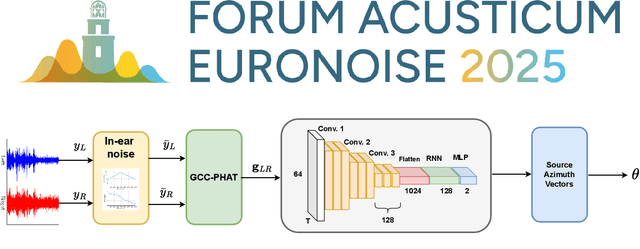
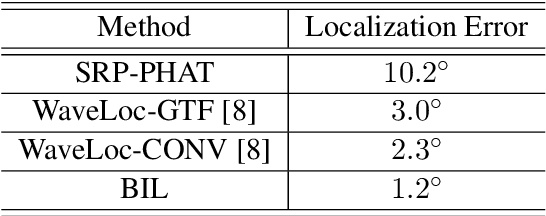
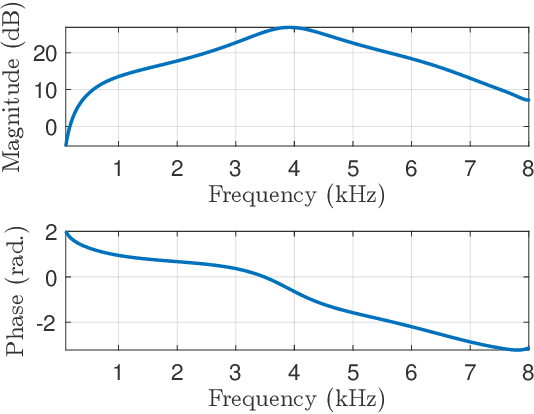
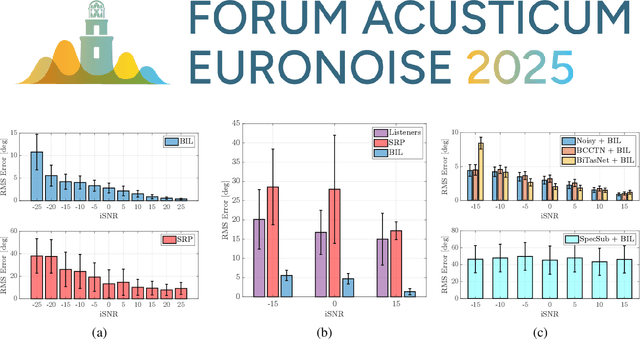
Binaural acoustic source localization is important to human listeners for spatial awareness, communication and safety. In this paper, an end-to-end binaural localization model for speech in noise is presented. A lightweight convolutional recurrent network that localizes sound in the frontal azimuthal plane for noisy reverberant binaural signals is introduced. The model incorporates additive internal ear noise to represent the frequency-dependent hearing threshold of a typical listener. The localization performance of the model is compared with the steered response power algorithm, and the use of the model as a measure of interaural cue preservation for binaural speech enhancement methods is studied. A listening test was performed to compare the performance of the model with human localization of speech in noisy conditions.
Soft-Constrained Spatially Selective Active Noise Control for Open-fitting Hearables
Jul 16, 2025Recent advances in spatially selective active noise control (SSANC) using multiple microphones have enabled hearables to suppress undesired noise while preserving desired speech from a specific direction. Aiming to achieve minimal speech distortion, a hard constraint has been used in previous work in the optimization problem to compute the control filter. In this work, we propose a soft-constrained SSANC system that uses a frequency-independent parameter to trade off between speech distortion and noise reduction. We derive both time- and frequency-domain formulations, and show that conventional active noise control and hard-constrained SSANC represent two limiting cases of the proposed design. We evaluate the system through simulations using a pair of open-fitting hearables in an anechoic environment with one speech source and two noise sources. The simulation results validate the theoretical derivations and demonstrate that for a broad range of the trade-off parameter, the signal-to-noise ratio and the speech quality and intelligibility in terms of PESQ and ESTOI can be substantially improved compared to the hard-constrained design.
Incremental Averaging Method to Improve Graph-Based Time-Difference-of-Arrival Estimation
Jul 09, 2025Estimating the position of a speech source based on time-differences-of-arrival (TDOAs) is often adversely affected by background noise and reverberation. A popular method to estimate the TDOA between a microphone pair involves maximizing a generalized cross-correlation with phase transform (GCC-PHAT) function. Since the TDOAs across different microphone pairs satisfy consistency relations, generally only a small subset of microphone pairs are used for source position estimation. Although the set of microphone pairs is often determined based on a reference microphone, recently a more robust method has been proposed to determine the set of microphone pairs by computing the minimum spanning tree (MST) of a signal graph of GCC-PHAT function reliabilities. To reduce the influence of noise and reverberation on the TDOA estimation accuracy, in this paper we propose to compute the GCC-PHAT functions of the MST based on an average of multiple cross-power spectral densities (CPSDs) using an incremental method. In each step of the method, we increase the number of CPSDs over which we average by considering CPSDs computed indirectly via other microphones from previous steps. Using signals recorded in a noisy and reverberant laboratory with an array of spatially distributed microphones, the performance of the proposed method is evaluated in terms of TDOA estimation error and 2D source position estimation error. Experimental results for different source and microphone configurations and three reverberation conditions show that the proposed method considering multiple CPSDs improves the TDOA estimation and source position estimation accuracy compared to the reference microphone- and MST-based methods that rely on a single CPSD as well as steered-response power-based source position estimation.