 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArray Geometry-Robust Attention-Based Neural Beamformer for Moving Speakers
Feb 05, 2024Recently, a mask-based beamformer with attention-based spatial covariance matrix aggregator (ASA) was proposed, which was demonstrated to track moving sources accurately. However, the deep neural network model used in this algorithm is limited to a specific channel configuration, requiring a different model in case a different channel permutation, channel count, or microphone array geometry is considered. Addressing this limitation, in this paper, we investigate three approaches to improve the robustness of the ASA-based tracking method against such variations: incorporating random channel configurations during the training process, employing the transform-average-concatenate (TAC) method to process multi-channel input features (allowing for any channel count and enabling permutation invariance), and utilizing input features that are robust against variations of the channel configuration. Our experiments, conducted using the CHiME-3 and DEMAND datasets, demonstrate improved robustness against mismatches in channel permutations, channel counts, and microphone array geometries compared to the conventional ASA-based tracking method without compromising performance in matched conditions, suggesting that the mask-based beamformer with ASA integrating the proposed approaches has the potential to track moving sources for arbitrary microphone arrays.
Speaker-conditioning Single-channel Target Speaker Extraction using Conformer-based Architectures
May 27, 2022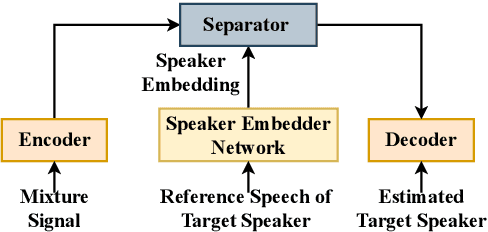
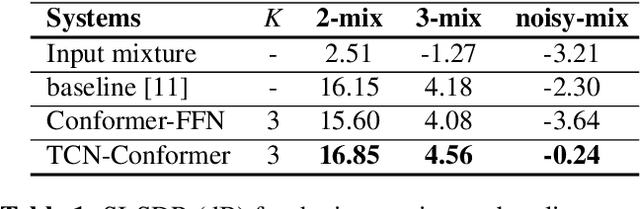
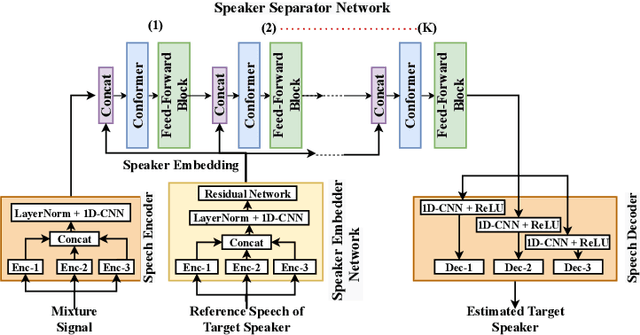
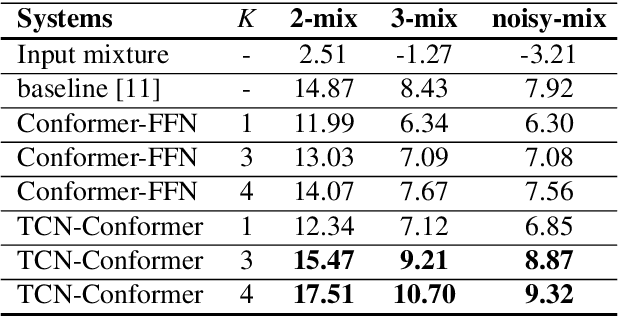
Target speaker extraction aims at extracting the target speaker from a mixture of multiple speakers exploiting auxiliary information about the target speaker. In this paper, we consider a complete time-domain target speaker extraction system consisting of a speaker embedder network and a speaker separator network which are jointly trained in an end-to-end learning process. We propose two different architectures for the speaker separator network which are based on the convolutional augmented transformer (conformer). The first architecture uses stacks of conformer and external feed-forward blocks (Conformer-FFN), while the second architecture uses stacks of temporal convolutional network (TCN) and conformer blocks (TCN-Conformer). Experimental results for 2-speaker mixtures, 3-speaker mixtures, and noisy mixtures of 2-speakers show that among the proposed separator networks, the TCN-Conformer significantly improves the target speaker extraction performance compared to the Conformer-FFN and a TCN-based baseline system.
Dictionary-Based Fusion of Contact and Acoustic Microphones for Wind Noise Reduction
May 18, 2022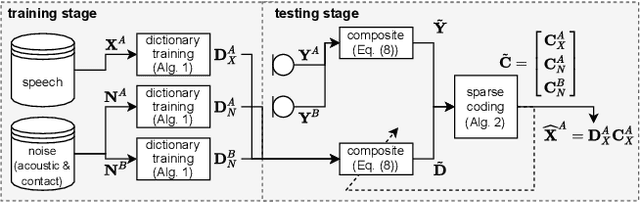
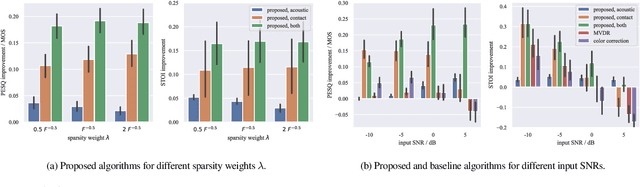
In mobile speech communication applications, wind noise can lead to a severe reduction of speech quality and intelligibility. Since the performance of speech enhancement algorithms using acoustic microphones tends to substantially degrade in extremely challenging scenarios, auxiliary sensors such as contact microphones can be used. Although contact microphones offer a much lower recorded wind noise level, they come at the cost of speech distortion and additional noise components. Aiming at exploiting the advantages of acoustic and contact microphones for wind noise reduction, in this paper we propose to extend conventional single-microphone dictionary-based speech enhancement approaches by simultaneously modeling the acoustic and contact microphone signals. We propose to train a single speech dictionary and two noise dictionaries and use a relative transfer function to model the relationship between the speech components at the microphones. Simulation results show that the proposed approach yields improvements in both speech quality and intelligibility compared to several baseline approaches, most notably approaches using only the contact microphones or only the acoustic microphone.
Deep Multi-Frame MVDR Filtering for Binaural Noise Reduction
May 18, 2022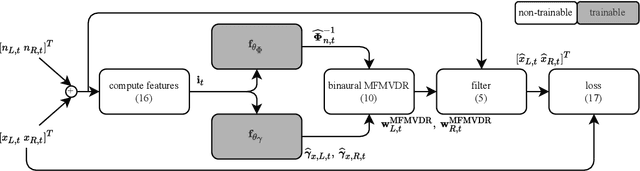
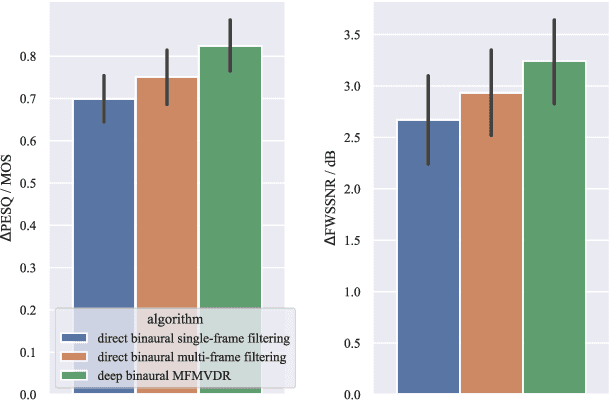
To improve speech intelligibility and speech quality in noisy environments, binaural noise reduction algorithms for head-mounted assistive listening devices are of crucial importance. Several binaural noise reduction algorithms such as the well-known binaural minimum variance distortionless response (MVDR) beamformer have been proposed, which exploit spatial correlations of both the target speech and the noise components. Furthermore, for single-microphone scenarios, multi-frame algorithms such as the multi-frame MVDR (MFMVDR) filter have been proposed, which exploit temporal instead of spatial correlations. In this contribution, we propose a binaural extension of the MFMVDR filter, which exploits both spatial and temporal correlations. The binaural MFMVDR filters are embedded in an end-to-end deep learning framework, where the required parameters, i.e., the speech spatio-temporal correlation vectors as well as the (inverse) noise spatio-temporal covariance matrix, are estimated by temporal convolutional networks (TCNs) that are trained by minimizing the mean spectral absolute error loss function. Simulation results comprising measured binaural room impulses and diverse noise sources at signal-to-noise ratios from -5 dB to 20 dB demonstrate the advantage of utilizing the binaural MFMVDR filter structure over directly estimating the binaural multi-frame filter coefficients with TCNs.
Joint Multi-Channel Dereverberation and Noise Reduction Using a Unified Convolutional Beamformer With Sparse Priors
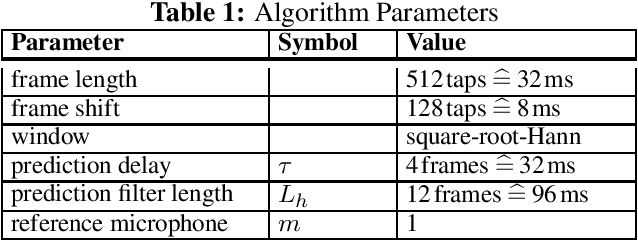
Jun 03, 2021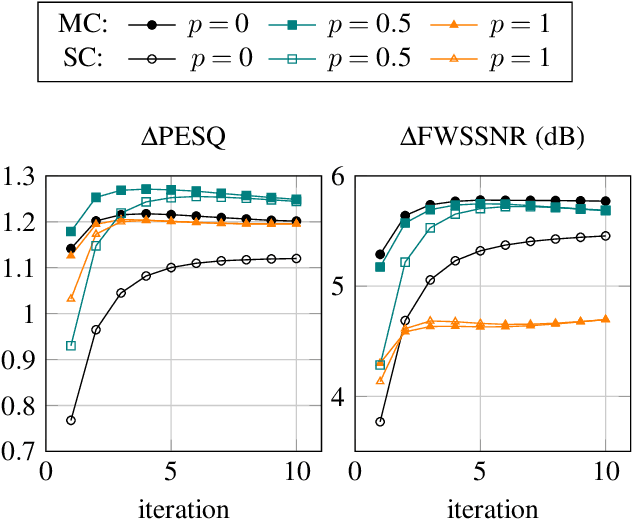
Recently, the convolutional weighted power minimization distortionless response (WPD) beamformer was proposed, which unifies multi-channel weighted prediction error dereverberation and minimum power distortionless response beamforming. To optimize the convolutional filter, the desired speech component is modeled with a time-varying Gaussian model, which promotes the sparsity of the desired speech component in the short-time Fourier transform domain compared to the noisy microphone signals. In this paper we generalize the convolutional WPD beamformer by using an lp-norm cost function, introducing an adjustable shape parameter which enables to control the sparsity of the desired speech component. Experiments based on the REVERB challenge dataset show that the proposed method outperforms the conventional convolutional WPD beamformer in terms of objective speech quality metrics.
Speaker-conditioned Target Speaker Extraction based on Customized LSTM Cells
Apr 09, 2021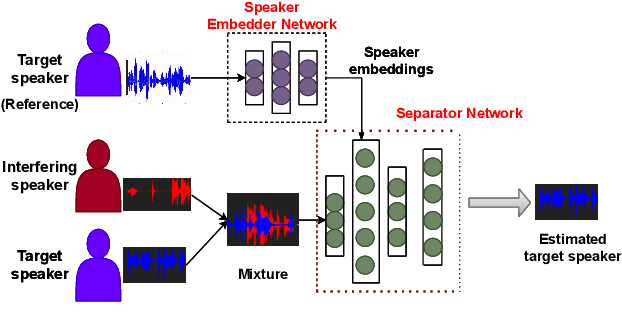
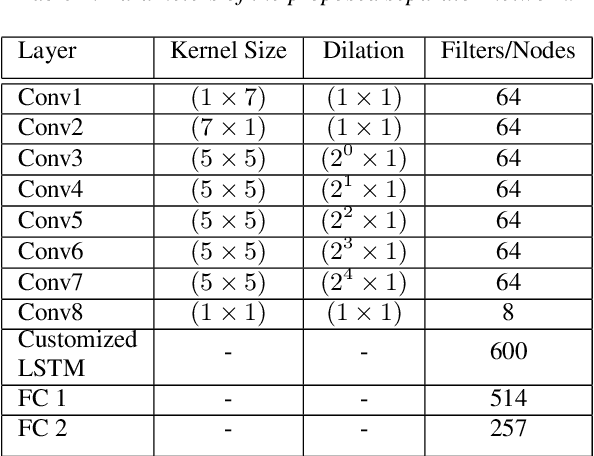
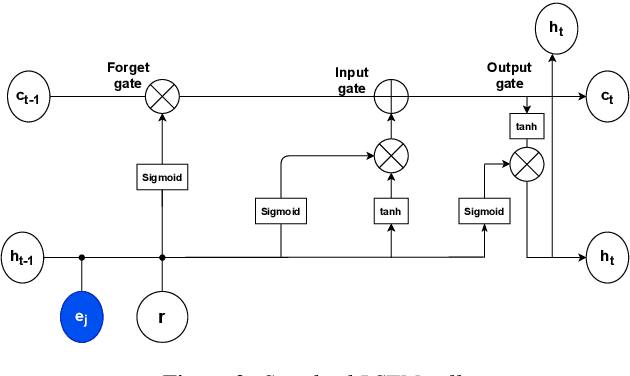
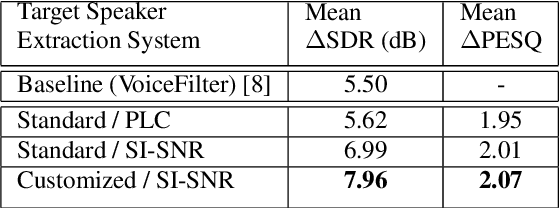
Speaker-conditioned target speaker extraction systems rely on auxiliary information about the target speaker to extract the target speaker signal from a mixture of multiple speakers. Typically, a deep neural network is applied to isolate the relevant target speaker characteristics. In this paper, we focus on a single-channel target speaker extraction system based on a CNN-LSTM separator network and a speaker embedder network requiring reference speech of the target speaker. In the LSTM layer of the separator network, we propose to customize the LSTM cells in order to only remember the specific voice patterns corresponding to the target speaker by modifying the information processing in the forget gate. Experimental results for two-speaker mixtures using the Librispeech dataset show that this customization significantly improves the target speaker extraction performance compared to using standard LSTM cells.