 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReference Microphone Selection for Guided Source Separation based on the Normalized L-p Norm
Oct 31, 2025



Guided Source Separation (GSS) is a popular front-end for distant automatic speech recognition (ASR) systems using spatially distributed microphones. When considering spatially distributed microphones, the choice of reference microphone may have a large influence on the quality of the output signal and the downstream ASR performance. In GSS-based speech enhancement, reference microphone selection is typically performed using the signal-to-noise ratio (SNR), which is optimal for noise reduction but may neglect differences in early-to-late-reverberant ratio (ELR) across microphones. In this paper, we propose two reference microphone selection methods for GSS-based speech enhancement that are based on the normalized $\ell_p$-norm, either using only the normalized $\ell_p$-norm or combining the normalized $\ell_p$-norm and the SNR to account for both differences in SNR and ELR across microphones. Experimental evaluation using a CHiME-8 distant ASR system shows that the proposed $\ell_p$-norm-based methods outperform the baseline method, reducing the macro-average word error rate.
Dissecting the Segmentation Model of End-to-End Diarization with Vector Clustering
Jun 13, 2025



End-to-End Neural Diarization with Vector Clustering is a powerful and practical approach to perform Speaker Diarization. Multiple enhancements have been proposed for the segmentation model of these pipelines, but their synergy had not been thoroughly evaluated. In this work, we provide an in-depth analysis on the impact of major architecture choices on the performance of the pipeline. We investigate different encoders (SincNet, pretrained and finetuned WavLM), different decoders (LSTM, Mamba, and Conformer), different losses (multilabel and multiclass powerset), and different chunk sizes. Through in-depth experiments covering nine datasets, we found that the finetuned WavLM-based encoder always results in the best systems by a wide margin. The LSTM decoder is outclassed by Mamba- and Conformer-based decoders, and while we found Mamba more robust to other architecture choices, it is slightly inferior to our best architecture, which uses a Conformer encoder. We found that multilabel and multiclass powerset losses do not have the same distribution of errors. We confirmed that the multiclass loss helps almost all models attain superior performance, except when finetuning WavLM, in which case, multilabel is the superior choice. We also evaluated the impact of the chunk size on all aforementioned architecture choices and found that newer architectures tend to better handle long chunk sizes, which can greatly improve pipeline performance. Our best system achieved state-of-the-art results on five widely used speaker diarization datasets.
Description and Discussion on DCASE 2025 Challenge Task 4: Spatial Semantic Segmentation of Sound Scenes
Jun 12, 2025


Spatial Semantic Segmentation of Sound Scenes (S5) aims to enhance technologies for sound event detection and separation from multi-channel input signals that mix multiple sound events with spatial information. This is a fundamental basis of immersive communication. The ultimate goal is to separate sound event signals with 6 Degrees of Freedom (6DoF) information into dry sound object signals and metadata about the object type (sound event class) and representing spatial information, including direction. However, because several existing challenge tasks already provide some of the subset functions, this task for this year focuses on detecting and separating sound events from multi-channel spatial input signals. This paper outlines the S5 task setting of the Detection and Classification of Acoustic Scenes and Events (DCASE) 2025 Challenge Task 4 and the DCASE2025 Task 4 Dataset, newly recorded and curated for this task. We also report experimental results for an S5 system trained and evaluated on this dataset. The full version of this paper will be published after the challenge results are made public.
TS-SUPERB: A Target Speech Processing Benchmark for Speech Self-Supervised Learning Models
May 10, 2025Self-supervised learning (SSL) models have significantly advanced speech processing tasks, and several benchmarks have been proposed to validate their effectiveness. However, previous benchmarks have primarily focused on single-speaker scenarios, with less exploration of target-speaker tasks in noisy, multi-talker conditions -- a more challenging yet practical case. In this paper, we introduce the Target-Speaker Speech Processing Universal Performance Benchmark (TS-SUPERB), which includes four widely recognized target-speaker processing tasks that require identifying the target speaker and extracting information from the speech mixture. In our benchmark, the speaker embedding extracted from enrollment speech is used as a clue to condition downstream models. The benchmark result reveals the importance of evaluating SSL models in target speaker scenarios, demonstrating that performance cannot be easily inferred from related single-speaker tasks. Moreover, by using a unified SSL-based target speech encoder, consisting of a speaker encoder and an extractor module, we also investigate joint optimization across TS tasks to leverage mutual information and demonstrate its effectiveness.
30+ Years of Source Separation Research: Achievements and Future Challenges
Jan 21, 2025Source separation (SS) of acoustic signals is a research field that emerged in the mid-1990s and has flourished ever since. On the occasion of ICASSP's 50th anniversary, we review the major contributions and advancements in the past three decades in the speech, audio, and music SS research field. We will cover both single- and multi-channel SS approaches. We will also look back on key efforts to foster a culture of scientific evaluation in the research field, including challenges, performance metrics, and datasets. We will conclude by discussing current trends and future research directions.
Mamba-based Segmentation Model for Speaker Diarization
Oct 10, 2024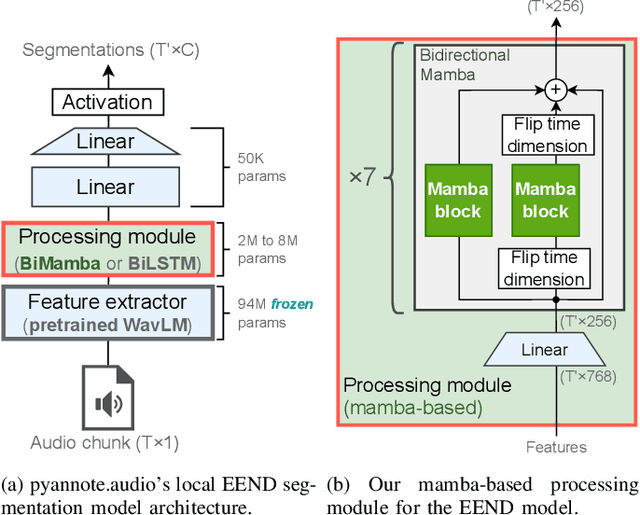
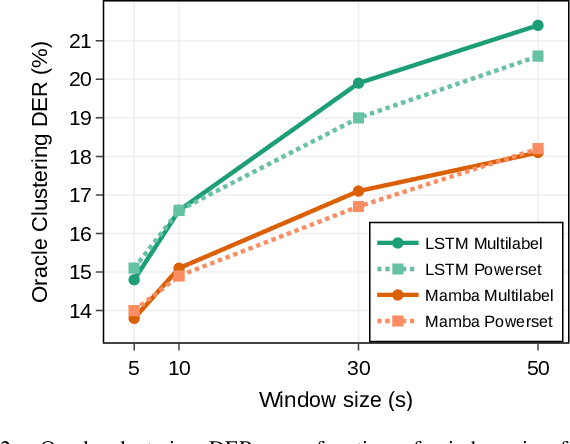
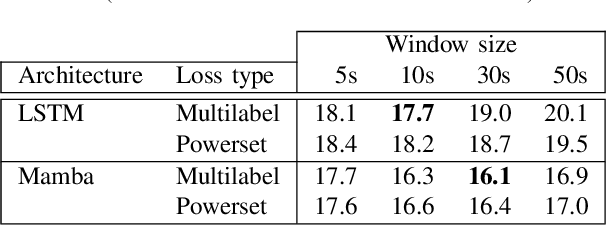
Mamba is a newly proposed architecture which behaves like a recurrent neural network (RNN) with attention-like capabilities. These properties are promising for speaker diarization, as attention-based models have unsuitable memory requirements for long-form audio, and traditional RNN capabilities are too limited. In this paper, we propose to assess the potential of Mamba for diarization by comparing the state-of-the-art neural segmentation of the pyannote pipeline with our proposed Mamba-based variant. Mamba's stronger processing capabilities allow usage of longer local windows, which significantly improve diarization quality by making the speaker embedding extraction more reliable. We find Mamba to be a superior alternative to both traditional RNN and the tested attention-based model. Our proposed Mamba-based system achieves state-of-the-art performance on three widely used diarization datasets.
NTT Multi-Speaker ASR System for the DASR Task of CHiME-8 Challenge
Sep 09, 2024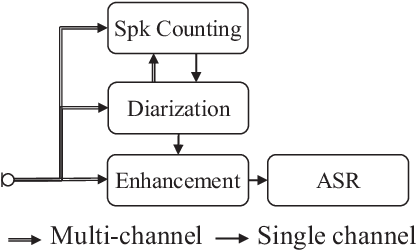
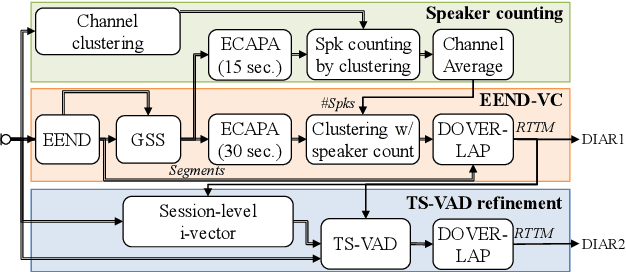

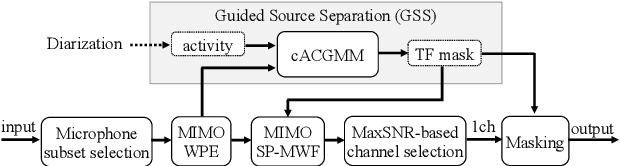
We present a distant automatic speech recognition (DASR) system developed for the CHiME-8 DASR track. It consists of a diarization first pipeline. For diarization, we use end-to-end diarization with vector clustering (EEND-VC) followed by target speaker voice activity detection (TS-VAD) refinement. To deal with various numbers of speakers, we developed a new multi-channel speaker counting approach. We then apply guided source separation (GSS) with several improvements to the baseline system. Finally, we perform ASR using a combination of systems built from strong pre-trained models. Our proposed system achieves a macro tcpWER of 21.3 % on the dev set, which is a 57 % relative improvement over the baseline.
Interaural time difference loss for binaural target sound extraction
Aug 01, 2024

Binaural target sound extraction (TSE) aims to extract a desired sound from a binaural mixture of arbitrary sounds while preserving the spatial cues of the desired sound. Indeed, for many applications, the target sound signal and its spatial cues carry important information about the sound source. Binaural TSE can be realized with a neural network trained to output only the desired sound given a binaural mixture and an embedding characterizing the desired sound class as inputs. Conventional TSE systems are trained using signal-level losses, which measure the difference between the extracted and reference signals for the left and right channels. In this paper, we propose adding explicit spatial losses to better preserve the spatial cues of the target sound. In particular, we explore losses aiming at preserving the interaural level (ILD), phase (IPD), and time differences (ITD). We show experimentally that adding such spatial losses, particularly our newly proposed ITD loss, helps preserve better spatial cues while maintaining the signal-level metrics.
Rethinking Processing Distortions: Disentangling the Impact of Speech Enhancement Errors on Speech Recognition Performance
Apr 23, 2024



It is challenging to improve automatic speech recognition (ASR) performance in noisy conditions with a single-channel speech enhancement (SE) front-end. This is generally attributed to the processing distortions caused by the nonlinear processing of single-channel SE front-ends. However, the causes of such degraded ASR performance have not been fully investigated. How to design single-channel SE front-ends in a way that significantly improves ASR performance remains an open research question. In this study, we investigate a signal-level numerical metric that can explain the cause of degradation in ASR performance. To this end, we propose a novel analysis scheme based on the orthogonal projection-based decomposition of SE errors. This scheme manually modifies the ratio of the decomposed interference, noise, and artifact errors, and it enables us to directly evaluate the impact of each error type on ASR performance. Our analysis reveals the particularly detrimental effect of artifact errors on ASR performance compared to the other types of errors. This provides us with a more principled definition of processing distortions that cause the ASR performance degradation. Then, we study two practical approaches for reducing the impact of artifact errors. First, we prove that the simple observation adding (OA) post-processing (i.e., interpolating the enhanced and observed signals) can monotonically improve the signal-to-artifact ratio. Second, we propose a novel training objective, called artifact-boosted signal-to-distortion ratio (AB-SDR), which forces the model to estimate the enhanced signals with fewer artifact errors. Through experiments, we confirm that both the OA and AB-SDR approaches are effective in decreasing artifact errors caused by single-channel SE front-ends, allowing them to significantly improve ASR performance.
Target Speech Extraction with Pre-trained Self-supervised Learning Models
Feb 17, 2024
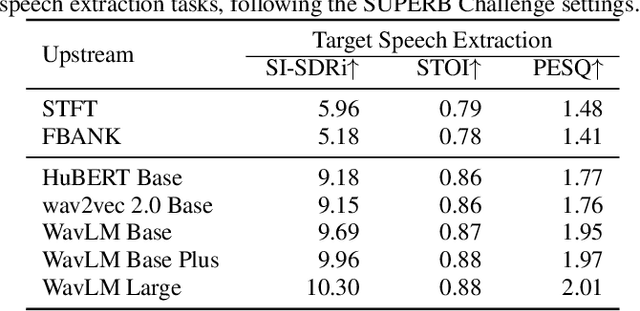
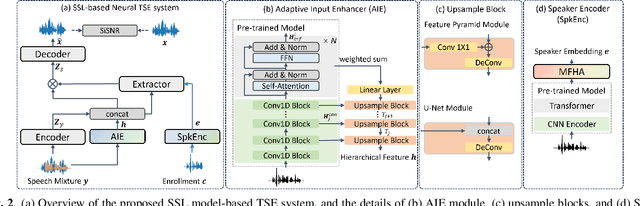
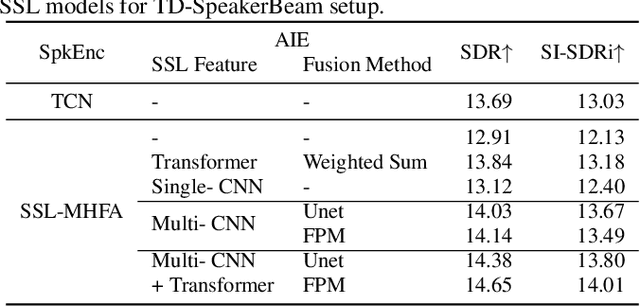
Pre-trained self-supervised learning (SSL) models have achieved remarkable success in various speech tasks. However, their potential in target speech extraction (TSE) has not been fully exploited. TSE aims to extract the speech of a target speaker in a mixture guided by enrollment utterances. We exploit pre-trained SSL models for two purposes within a TSE framework, i.e., to process the input mixture and to derive speaker embeddings from the enrollment. In this paper, we focus on how to effectively use SSL models for TSE. We first introduce a novel TSE downstream task following the SUPERB principles. This simple experiment shows the potential of SSL models for TSE, but extraction performance remains far behind the state-of-the-art. We then extend a powerful TSE architecture by incorporating two SSL-based modules: an Adaptive Input Enhancer (AIE) and a speaker encoder. Specifically, the proposed AIE utilizes intermediate representations from the CNN encoder by adjusting the time resolution of CNN encoder and transformer blocks through progressive upsampling, capturing both fine-grained and hierarchical features. Our method outperforms current TSE systems achieving a SI-SDR improvement of 14.0 dB on LibriMix. Moreover, we can further improve performance by 0.7 dB by fine-tuning the whole model including the SSL model parameters.