 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBUT Systems for WildSpoof Challenge: SASV in the Wild
Dec 14, 2025
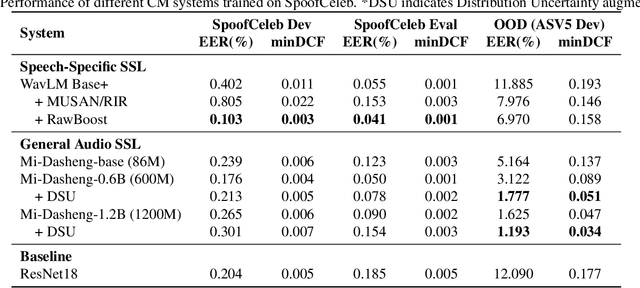

This paper presents the BUT submission to the WildSpoof Challenge, focusing on the Spoofing-robust Automatic Speaker Verification (SASV) track. We propose a SASV framework designed to bridge the gap between general audio understanding and specialized speech analysis. Our subsystem integrates diverse Self-Supervised Learning front-ends ranging from general audio models (e.g., Dasheng) to speech-specific encoders (e.g., WavLM). These representations are aggregated via a lightweight Multi-Head Factorized Attention back-end for corresponding subtasks. Furthermore, we introduce a feature domain augmentation strategy based on Distribution Uncertainty to explicitly model and mitigate the domain shift caused by unseen neural vocoders and recording environments. By fusing these robust CM scores with state-of-the-art ASV systems, our approach achieves superior minimization of the a-DCFs and EERs.
BUT Systems for Environmental Sound Deepfake Detection in the ESDD 2026 Challenge
Dec 09, 2025This paper describes the BUT submission to the ESDD 2026 Challenge, specifically focusing on Track 1: Environmental Sound Deepfake Detection with Unseen Generators. To address the critical challenge of generalizing to audio generated by unseen synthesis algorithms, we propose a robust ensemble framework leveraging diverse Self-Supervised Learning (SSL) models. We conduct a comprehensive analysis of general audio SSL models (including BEATs, EAT, and Dasheng) and speech-specific SSLs. These front-ends are coupled with a lightweight Multi-Head Factorized Attention (MHFA) back-end to capture discriminative representations. Furthermore, we introduce a feature domain augmentation strategy based on distribution uncertainty modeling to enhance model robustness against unseen spectral distortions. All models are trained exclusively on the official EnvSDD data, without using any external resources. Experimental results demonstrate the effectiveness of our approach: our best single system achieved Equal Error Rates (EER) of 0.00\%, 4.60\%, and 4.80\% on the Development, Progress (Track 1), and Final Evaluation sets, respectively. The fusion system further improved generalization, yielding EERs of 0.00\%, 3.52\%, and 4.38\% across the same partitions.
TS-SUPERB: A Target Speech Processing Benchmark for Speech Self-Supervised Learning Models
May 10, 2025



Self-supervised learning (SSL) models have significantly advanced speech processing tasks, and several benchmarks have been proposed to validate their effectiveness. However, previous benchmarks have primarily focused on single-speaker scenarios, with less exploration of target-speaker tasks in noisy, multi-talker conditions -- a more challenging yet practical case. In this paper, we introduce the Target-Speaker Speech Processing Universal Performance Benchmark (TS-SUPERB), which includes four widely recognized target-speaker processing tasks that require identifying the target speaker and extracting information from the speech mixture. In our benchmark, the speaker embedding extracted from enrollment speech is used as a clue to condition downstream models. The benchmark result reveals the importance of evaluating SSL models in target speaker scenarios, demonstrating that performance cannot be easily inferred from related single-speaker tasks. Moreover, by using a unified SSL-based target speech encoder, consisting of a speaker encoder and an extractor module, we also investigate joint optimization across TS tasks to leverage mutual information and demonstrate its effectiveness.
Challenging margin-based speaker embedding extractors by using the variational information bottleneck
Jun 18, 2024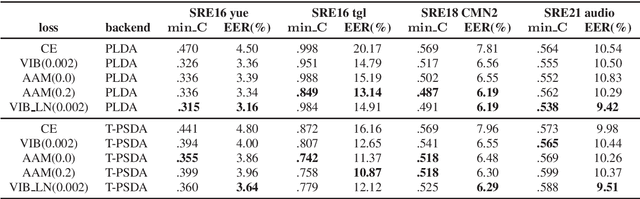
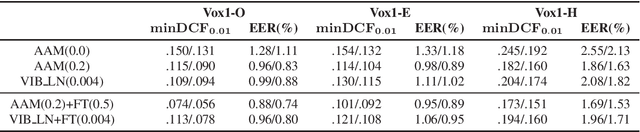
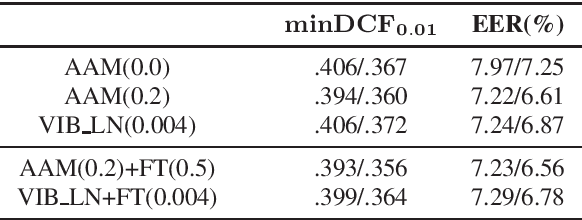
Speaker embedding extractors are typically trained using a classification loss over the training speakers. During the last few years, the standard softmax/cross-entropy loss has been replaced by the margin-based losses, yielding significant improvements in speaker recognition accuracy. Motivated by the fact that the margin merely reduces the logit of the target speaker during training, we consider a probabilistic framework that has a similar effect. The variational information bottleneck provides a principled mechanism for making deterministic nodes stochastic, resulting in an implicit reduction of the posterior of the target speaker. We experiment with a wide range of speaker recognition benchmarks and scoring methods and report competitive results to those obtained with the state-of-the-art Additive Angular Margin loss.
Probing Self-supervised Learning Models with Target Speech Extraction
Feb 17, 2024Large-scale pre-trained self-supervised learning (SSL) models have shown remarkable advancements in speech-related tasks. However, the utilization of these models in complex multi-talker scenarios, such as extracting a target speaker in a mixture, is yet to be fully evaluated. In this paper, we introduce target speech extraction (TSE) as a novel downstream task to evaluate the feature extraction capabilities of pre-trained SSL models. TSE uniquely requires both speaker identification and speech separation, distinguishing it from other tasks in the Speech processing Universal PERformance Benchmark (SUPERB) evaluation. Specifically, we propose a TSE downstream model composed of two lightweight task-oriented modules based on the same frozen SSL model. One module functions as a speaker encoder to obtain target speaker information from an enrollment speech, while the other estimates the target speaker's mask to extract its speech from the mixture. Experimental results on the Libri2mix datasets reveal the relevance of the TSE downstream task to probe SSL models, as its performance cannot be simply deduced from other related tasks such as speaker verification and separation.
Target Speech Extraction with Pre-trained Self-supervised Learning Models
Feb 17, 2024
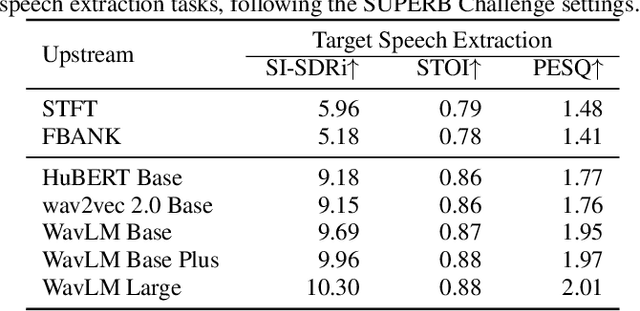
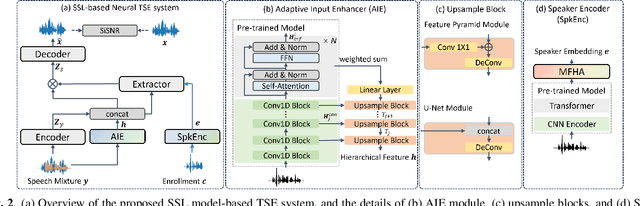
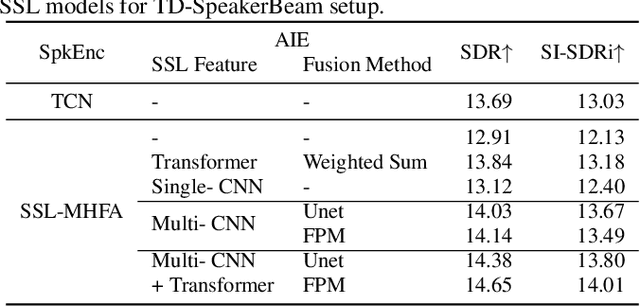
Pre-trained self-supervised learning (SSL) models have achieved remarkable success in various speech tasks. However, their potential in target speech extraction (TSE) has not been fully exploited. TSE aims to extract the speech of a target speaker in a mixture guided by enrollment utterances. We exploit pre-trained SSL models for two purposes within a TSE framework, i.e., to process the input mixture and to derive speaker embeddings from the enrollment. In this paper, we focus on how to effectively use SSL models for TSE. We first introduce a novel TSE downstream task following the SUPERB principles. This simple experiment shows the potential of SSL models for TSE, but extraction performance remains far behind the state-of-the-art. We then extend a powerful TSE architecture by incorporating two SSL-based modules: an Adaptive Input Enhancer (AIE) and a speaker encoder. Specifically, the proposed AIE utilizes intermediate representations from the CNN encoder by adjusting the time resolution of CNN encoder and transformer blocks through progressive upsampling, capturing both fine-grained and hierarchical features. Our method outperforms current TSE systems achieving a SI-SDR improvement of 14.0 dB on LibriMix. Moreover, we can further improve performance by 0.7 dB by fine-tuning the whole model including the SSL model parameters.
Extracting speaker and emotion information from self-supervised speech models via channel-wise correlations
Oct 15, 2022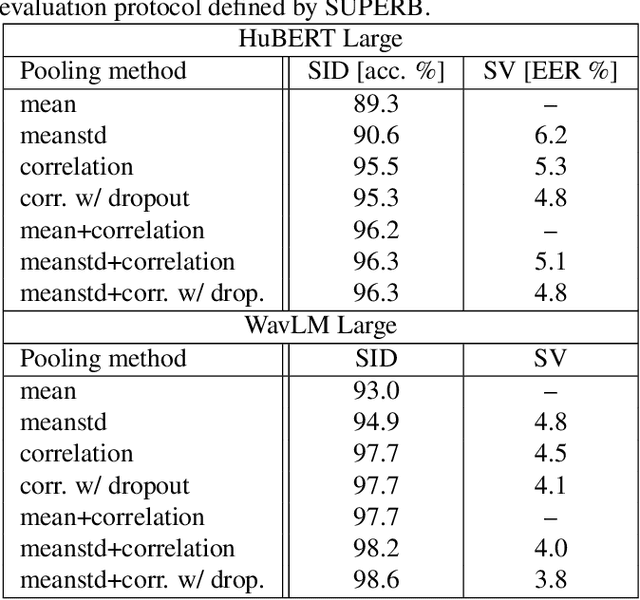
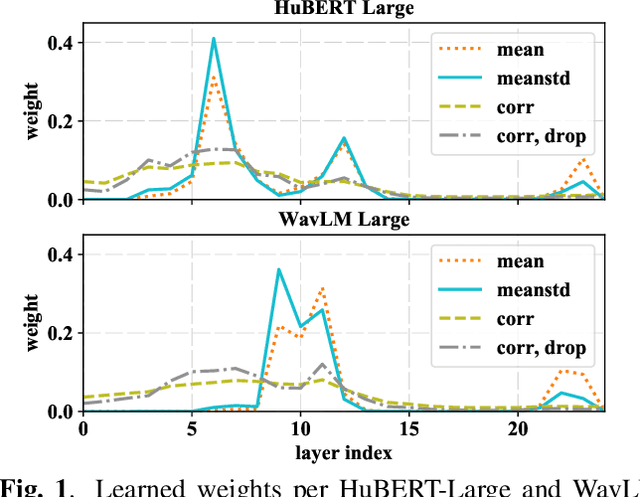
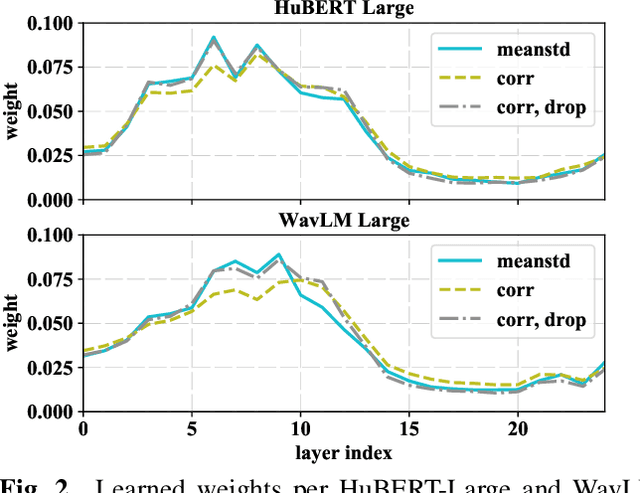
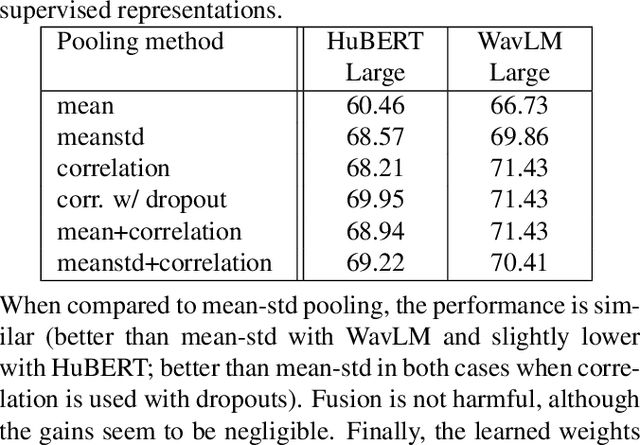
Self-supervised learning of speech representations from large amounts of unlabeled data has enabled state-of-the-art results in several speech processing tasks. Aggregating these speech representations across time is typically approached by using descriptive statistics, and in particular, using the first- and second-order statistics of representation coefficients. In this paper, we examine an alternative way of extracting speaker and emotion information from self-supervised trained models, based on the correlations between the coefficients of the representations - correlation pooling. We show improvements over mean pooling and further gains when the pooling methods are combined via fusion. The code is available at github.com/Lamomal/s3prl_correlation.
An attention-based backend allowing efficient fine-tuning of transformer models for speaker verification
Oct 03, 2022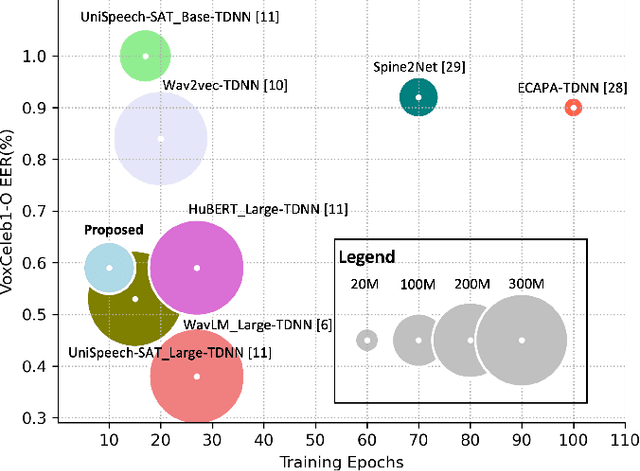

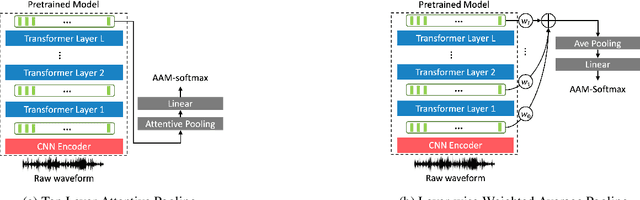

In recent years, self-supervised learning paradigm has received extensive attention due to its great success in various down-stream tasks. However, the fine-tuning strategies for adapting those pre-trained models to speaker verification task have yet to be fully explored. In this paper, we analyze several feature extraction approaches built on top of a pre-trained model, as well as regularization and learning rate schedule to stabilize the fine-tuning process and further boost performance: multi-head factorized attentive pooling is proposed to factorize the comparison of speaker representations into multiple phonetic clusters. We regularize towards the parameters of the pre-trained model and we set different learning rates for each layer of the pre-trained model during fine-tuning. The experimental results show our method can significantly shorten the training time to 4 hours and achieve SOTA performance: 0.59%, 0.79% and 1.77% EER on Vox1-O, Vox1-E and Vox1-H, respectively.
Analyzing speaker verification embedding extractors and back-ends under language and channel mismatch
Mar 19, 2022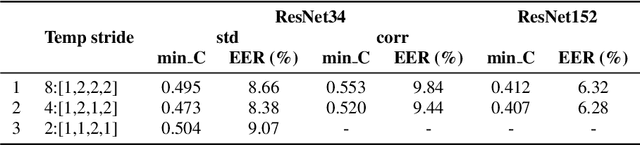
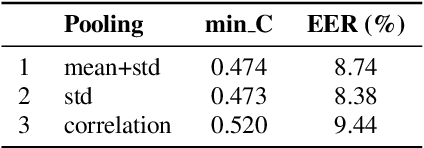
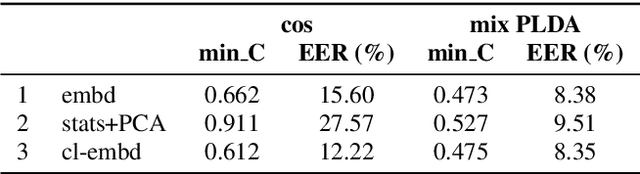
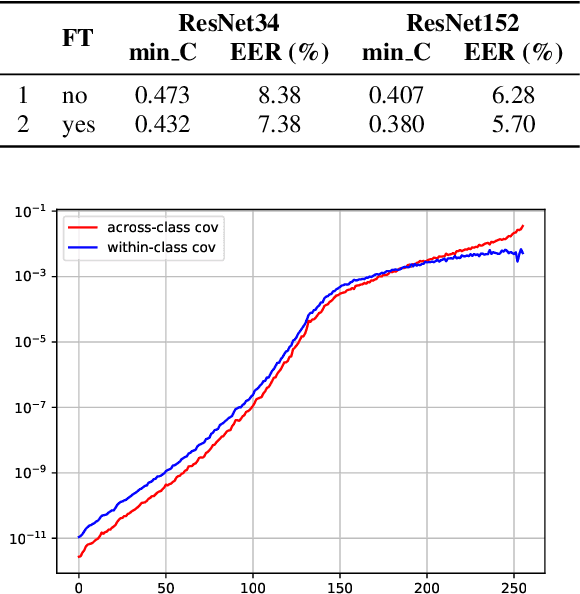
In this paper, we analyze the behavior and performance of speaker embeddings and the back-end scoring model under domain and language mismatch. We present our findings regarding ResNet-based speaker embedding architectures and show that reduced temporal stride yields improved performance. We then consider a PLDA back-end and show how a combination of small speaker subspace, language-dependent PLDA mixture, and nuisance-attribute projection can have a drastic impact on the performance of the system. Besides, we present an efficient way of scoring and fusing class posterior logit vectors recently shown to perform well for speaker verification task. The experiments are performed using the NIST SRE 2021 setup.
Self-supervised speaker embeddings
Apr 23, 2019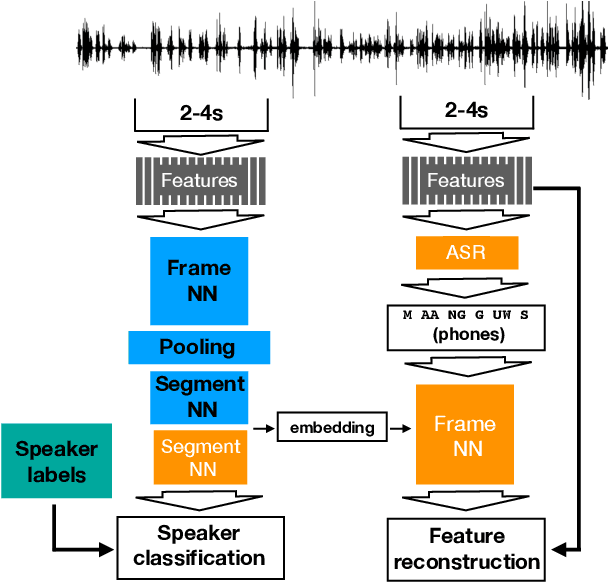
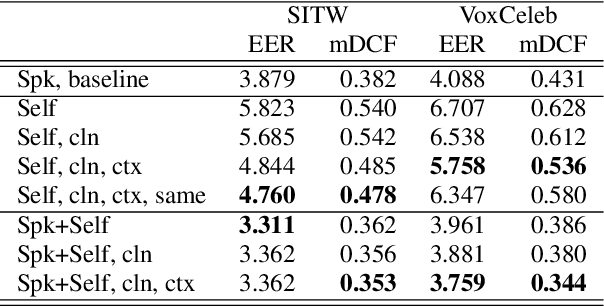
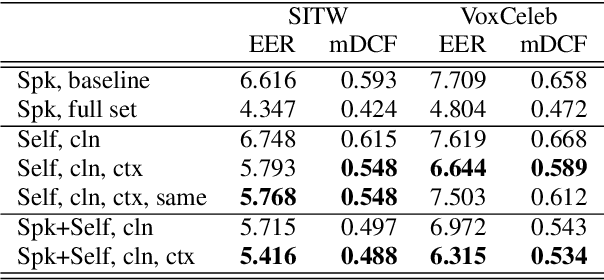
Contrary to i-vectors, speaker embeddings such as x-vectors are incapable of leveraging unlabelled utterances, due to the classification loss over training speakers. In this paper, we explore an alternative training strategy to enable the use of unlabelled utterances in training. We propose to train speaker embedding extractors via reconstructing the frames of a target speech segment, given the inferred embedding of another speech segment of the same utterance. We do this by attaching to the standard speaker embedding extractor a decoder network, which we feed not merely with the speaker embedding, but also with the estimated phone sequence of the target frame sequence. The reconstruction loss can be used either as a single objective, or be combined with the standard speaker classification loss. In the latter case, it acts as a regularizer, encouraging generalizability to speakers unseen during training. In all cases, the proposed architectures are trained from scratch and in an end-to-end fashion. We demonstrate the benefits from the proposed approach on VoxCeleb and Speakers in the wild, and we report notable improvements over the baseline.