 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTarget Speech Extraction with Pre-trained Self-supervised Learning Models
Paper and Code

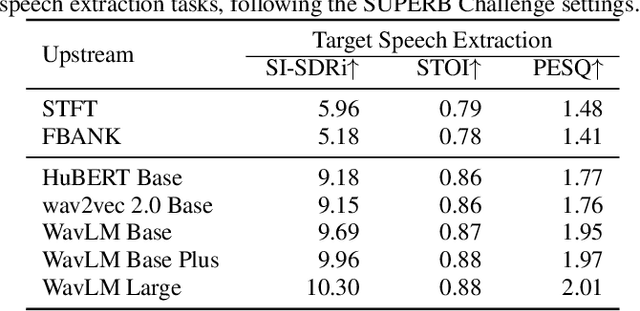
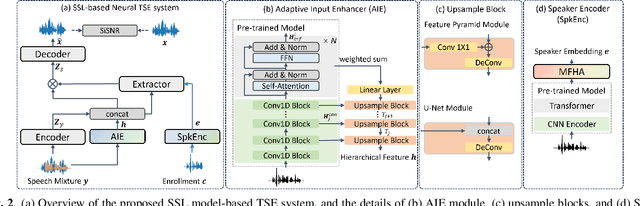
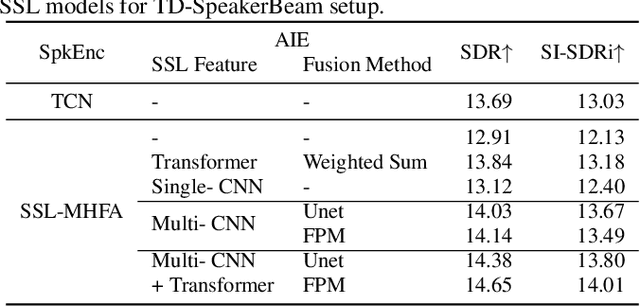
Pre-trained self-supervised learning (SSL) models have achieved remarkable success in various speech tasks. However, their potential in target speech extraction (TSE) has not been fully exploited. TSE aims to extract the speech of a target speaker in a mixture guided by enrollment utterances. We exploit pre-trained SSL models for two purposes within a TSE framework, i.e., to process the input mixture and to derive speaker embeddings from the enrollment. In this paper, we focus on how to effectively use SSL models for TSE. We first introduce a novel TSE downstream task following the SUPERB principles. This simple experiment shows the potential of SSL models for TSE, but extraction performance remains far behind the state-of-the-art. We then extend a powerful TSE architecture by incorporating two SSL-based modules: an Adaptive Input Enhancer (AIE) and a speaker encoder. Specifically, the proposed AIE utilizes intermediate representations from the CNN encoder by adjusting the time resolution of CNN encoder and transformer blocks through progressive upsampling, capturing both fine-grained and hierarchical features. Our method outperforms current TSE systems achieving a SI-SDR improvement of 14.0 dB on LibriMix. Moreover, we can further improve performance by 0.7 dB by fine-tuning the whole model including the SSL model parameters.