 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing speaker verification embedding extractors and back-ends under language and channel mismatch
Mar 19, 2022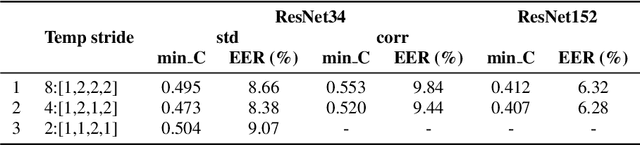
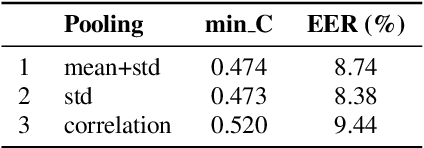
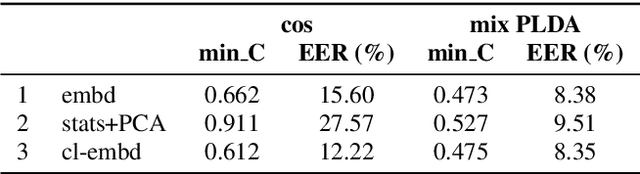
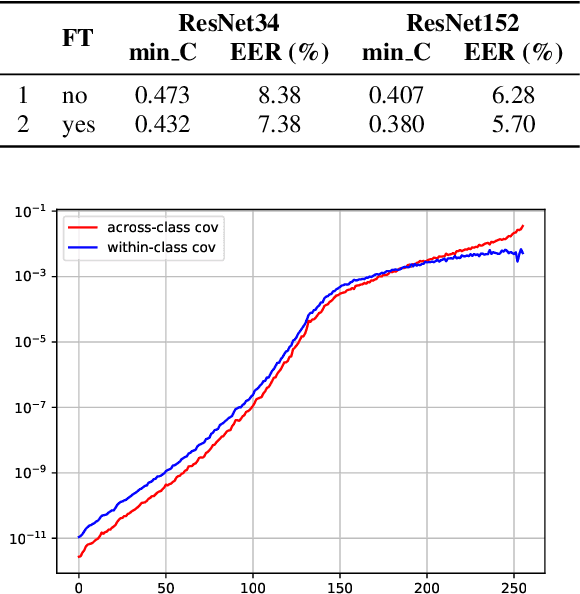
In this paper, we analyze the behavior and performance of speaker embeddings and the back-end scoring model under domain and language mismatch. We present our findings regarding ResNet-based speaker embedding architectures and show that reduced temporal stride yields improved performance. We then consider a PLDA back-end and show how a combination of small speaker subspace, language-dependent PLDA mixture, and nuisance-attribute projection can have a drastic impact on the performance of the system. Besides, we present an efficient way of scoring and fusing class posterior logit vectors recently shown to perform well for speaker verification task. The experiments are performed using the NIST SRE 2021 setup.
A Speaker Verification Backend with Robust Performance across Conditions
Feb 02, 2021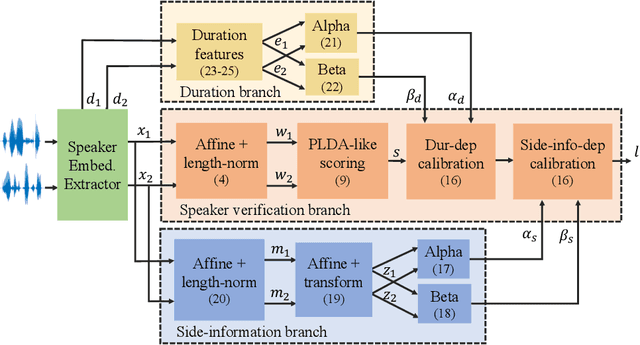
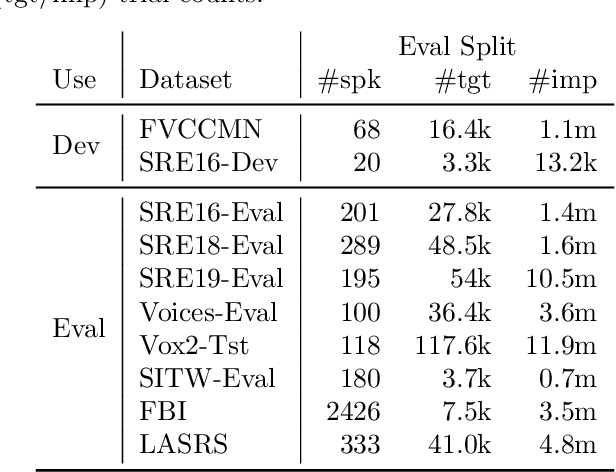
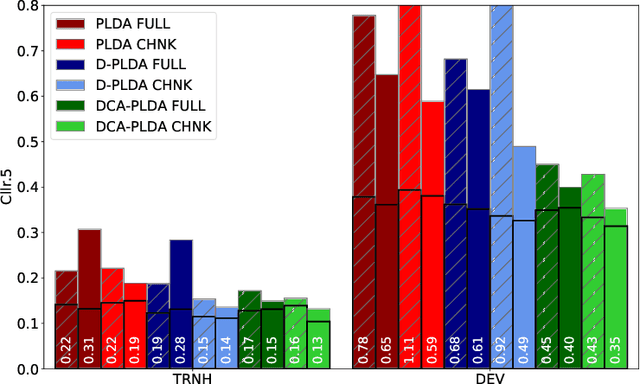
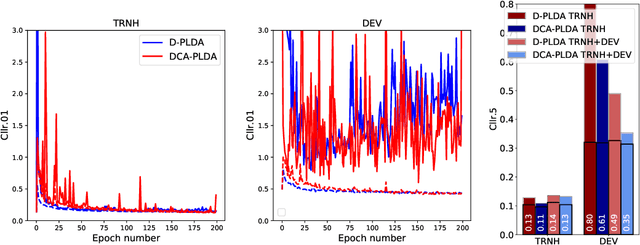
In this paper, we address the problem of speaker verification in conditions unseen or unknown during development. A standard method for speaker verification consists of extracting speaker embeddings with a deep neural network and processing them through a backend composed of probabilistic linear discriminant analysis (PLDA) and global logistic regression score calibration. This method is known to result in systems that work poorly on conditions different from those used to train the calibration model. We propose to modify the standard backend, introducing an adaptive calibrator that uses duration and other automatically extracted side-information to adapt to the conditions of the inputs. The backend is trained discriminatively to optimize binary cross-entropy. When trained on a number of diverse datasets that are labeled only with respect to speaker, the proposed backend consistently and, in some cases, dramatically improves calibration, compared to the standard PLDA approach, on a number of held-out datasets, some of which are markedly different from the training data. Discrimination performance is also consistently improved. We show that joint training of the PLDA and the adaptive calibrator is essential -- the same benefits cannot be achieved when freezing PLDA and fine-tuning the calibrator. To our knowledge, the results in this paper are the first evidence in the literature that it is possible to develop a speaker verification system with robust out-of-the-box performance on a large variety of conditions.
Large-Scale Speaker Diarization of Radio Broadcast Archives
Jun 28, 2019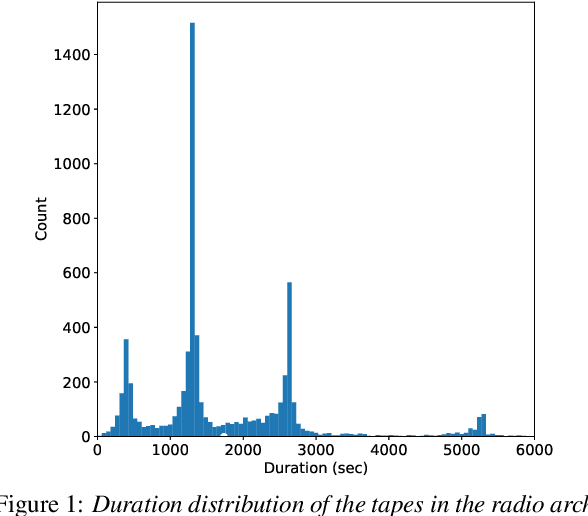
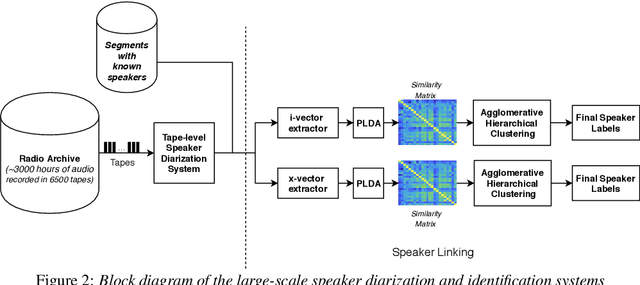

This paper describes our initial efforts to build a large-scale speaker diarization (SD) and identification system on a recently digitized radio broadcast archive from the Netherlands which has more than 6500 audio tapes with 3000 hours of Frisian-Dutch speech recorded between 1950-2016. The employed large-scale diarization scheme involves two stages: (1) tape-level speaker diarization providing pseudo-speaker identities and (2) speaker linking to relate pseudo-speakers appearing in multiple tapes. Having access to the speaker models of several frequently appearing speakers from the previously collected FAME! speech corpus, we further perform speaker identification by linking these known speakers to the pseudo-speakers identified at the first stage. In this work, we present a recently created longitudinal and multilingual SD corpus designed for large-scale SD research and evaluate the performance of a new speaker linking system using x-vectors with PLDA to quantify cross-tape speaker similarity on this corpus. The performance of this speaker linking system is evaluated on a small subset of the archive which is manually annotated with speaker information. The speaker linking performance reported on this subset (53 hours) and the whole archive (3000 hours) is compared to quantify the impact of scaling up in the amount of speech data.
Fast variational Bayes for heavy-tailed PLDA applied to i-vectors and x-vectors
Mar 24, 2018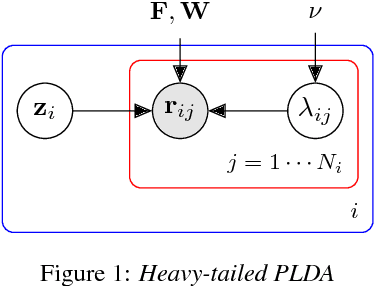
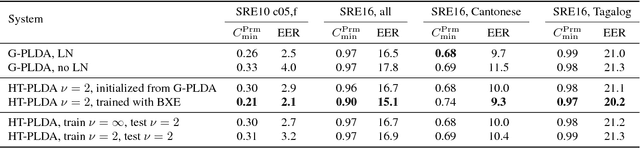
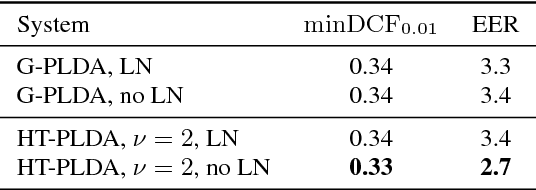
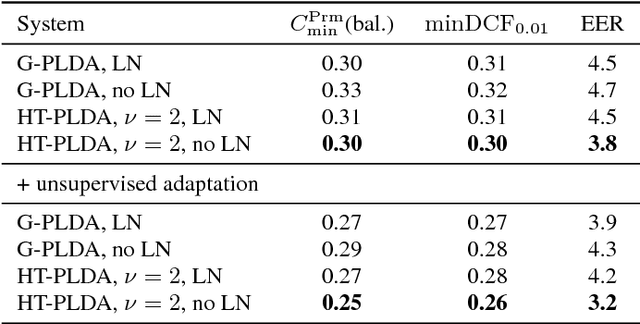
The standard state-of-the-art backend for text-independent speaker recognizers that use i-vectors or x-vectors, is Gaussian PLDA (G-PLDA), assisted by a Gaussianization step involving length normalization. G-PLDA can be trained with both generative or discriminative methods. It has long been known that heavy-tailed PLDA (HT-PLDA), applied without length normalization, gives similar accuracy, but at considerable extra computational cost. We have recently introduced a fast scoring algorithm for a discriminatively trained HT-PLDA backend. This paper extends that work by introducing a fast, variational Bayes, generative training algorithm. We compare old and new backends, with and without length-normalization, with i-vectors and x-vectors, on SRE'10, SRE'16 and SITW.
Gaussian meta-embeddings for efficient scoring of a heavy-tailed PLDA model
Feb 27, 2018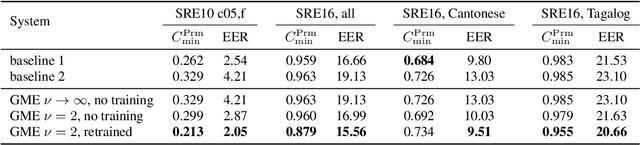
Embeddings in machine learning are low-dimensional representations of complex input patterns, with the property that simple geometric operations like Euclidean distances and dot products can be used for classification and comparison tasks. The proposed meta-embeddings are special embeddings that live in more general inner product spaces. They are designed to propagate uncertainty to the final output in speaker recognition and similar applications. The familiar Gaussian PLDA model (GPLDA) can be re-formulated as an extractor for Gaussian meta-embeddings (GMEs), such that likelihood ratio scores are given by Hilbert space inner products between Gaussian likelihood functions. GMEs extracted by the GPLDA model have fixed precisions and do not propagate uncertainty. We show that a generalization to heavy-tailed PLDA gives GMEs with variable precisions, which do propagate uncertainty. Experiments on NIST SRE 2010 and 2016 show that the proposed method applied to i-vectors without length normalization is up to 20% more accurate than GPLDA applied to length-normalized ivectors.
A Generative Model for Score Normalization in Speaker Recognition
Sep 28, 2017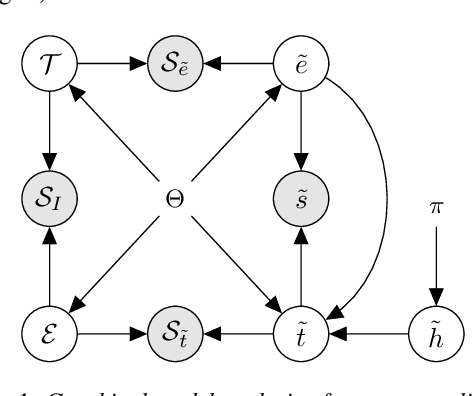
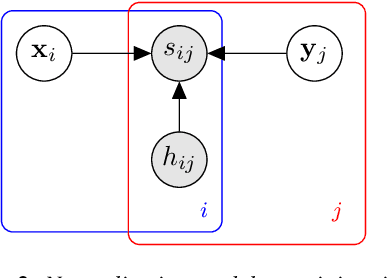
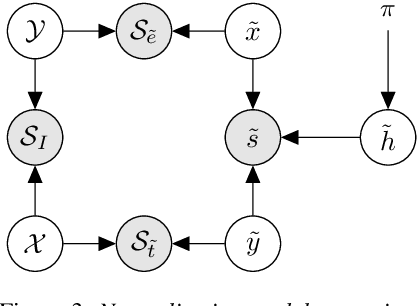
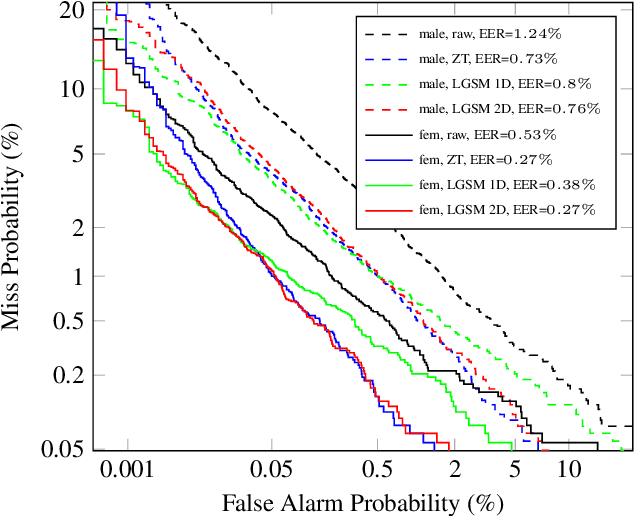
We propose a theoretical framework for thinking about score normalization, which confirms that normalization is not needed under (admittedly fragile) ideal conditions. If, however, these conditions are not met, e.g. under data-set shift between training and runtime, our theory reveals dependencies between scores that could be exploited by strategies such as score normalization. Indeed, it has been demonstrated over and over experimentally, that various ad-hoc score normalization recipes do work. We present a first attempt at using probability theory to design a generative score-space normalization model which gives similar improvements to ZT-norm on the text-dependent RSR 2015 database.
Generative, Fully Bayesian, Gaussian, Openset Pattern Classifier
Jul 24, 2013This report works out the details of a closed-form, fully Bayesian, multiclass, openset, generative pattern classifier using multivariate Gaussian likelihoods, with conjugate priors. The generative model has a common within-class covariance, which is proportional to the between-class covariance in the conjugate prior. The scalar proportionality constant is the only plugin parameter. All other model parameters are intergated out in closed form. An expression is given for the model evidence, which can be used to make plugin estimates for the proportionality constant. Pattern recognition is done via the predictive likeihoods of classes for which training data is available, as well as a predicitve likelihood for any as yet unseen class.
The PAV algorithm optimizes binary proper scoring rules
Apr 08, 2013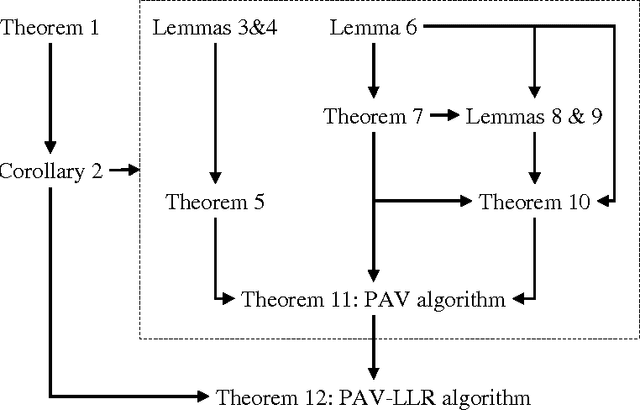
There has been much recent interest in application of the pool-adjacent-violators (PAV) algorithm for the purpose of calibrating the probabilistic outputs of automatic pattern recognition and machine learning algorithms. Special cost functions, known as proper scoring rules form natural objective functions to judge the goodness of such calibration. We show that for binary pattern classifiers, the non-parametric optimization of calibration, subject to a monotonicity constraint, can be solved by PAV and that this solution is optimal for all regular binary proper scoring rules. This extends previous results which were limited to convex binary proper scoring rules. We further show that this result holds not only for calibration of probabilities, but also for calibration of log-likelihood-ratios, in which case optimality holds independently of the prior probabilities of the pattern classes.