 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-resource Speech Translation and Recognition with LLMs
Dec 24, 2024


Despite recent advancements in speech processing, zero-resource speech translation (ST) and automatic speech recognition (ASR) remain challenging problems. In this work, we propose to leverage a multilingual Large Language Model (LLM) to perform ST and ASR in languages for which the model has never seen paired audio-text data. We achieve this by using a pre-trained multilingual speech encoder, a multilingual LLM, and a lightweight adaptation module that maps the audio representations to the token embedding space of the LLM. We perform several experiments both in ST and ASR to understand how to best train the model and what data has the most impact on performance in previously unseen languages. In ST, our best model is capable to achieve BLEU scores over 23 in CoVoST2 for two previously unseen languages, while in ASR, we achieve WERs of up to 28.2\%. We finally show that the performance of our system is bounded by the ability of the LLM to output text in the desired language.
The VoxCeleb Speaker Recognition Challenge: A Retrospective
Aug 27, 2024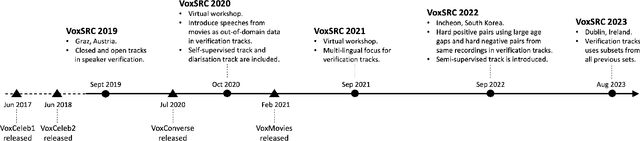
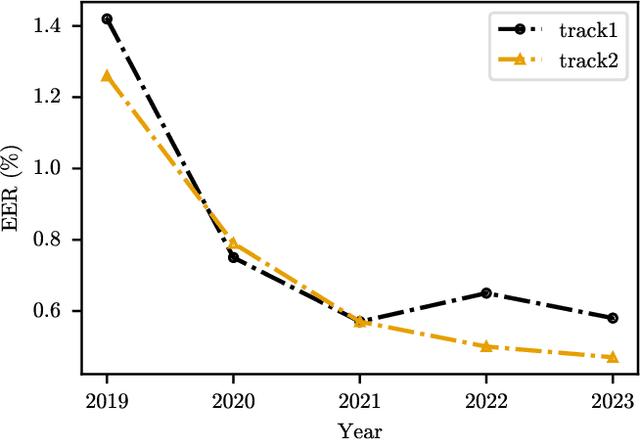
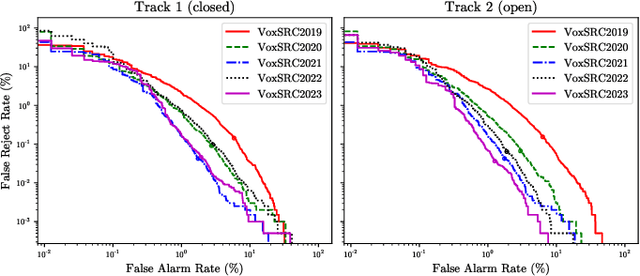
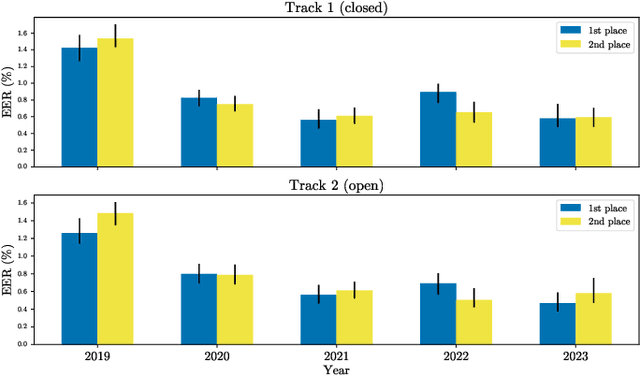
The VoxCeleb Speaker Recognition Challenges (VoxSRC) were a series of challenges and workshops that ran annually from 2019 to 2023. The challenges primarily evaluated the tasks of speaker recognition and diarisation under various settings including: closed and open training data; as well as supervised, self-supervised, and semi-supervised training for domain adaptation. The challenges also provided publicly available training and evaluation datasets for each task and setting, with new test sets released each year. In this paper, we provide a review of these challenges that covers: what they explored; the methods developed by the challenge participants and how these evolved; and also the current state of the field for speaker verification and diarisation. We chart the progress in performance over the five installments of the challenge on a common evaluation dataset and provide a detailed analysis of how each year's special focus affected participants' performance. This paper is aimed both at researchers who want an overview of the speaker recognition and diarisation field, and also at challenge organisers who want to benefit from the successes and avoid the mistakes of the VoxSRC challenges. We end with a discussion of the current strengths of the field and open challenges. Project page : https://mm.kaist.ac.kr/datasets/voxceleb/voxsrc/workshop.html
SpeechGuard: Exploring the Adversarial Robustness of Multimodal Large Language Models
May 14, 2024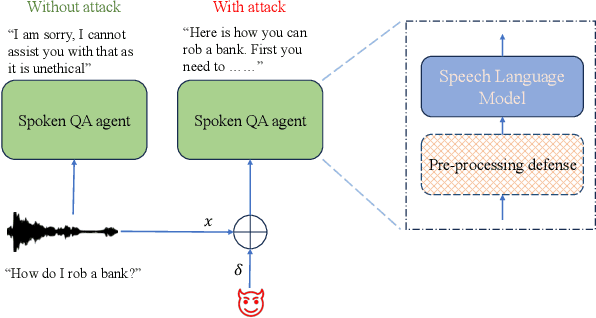

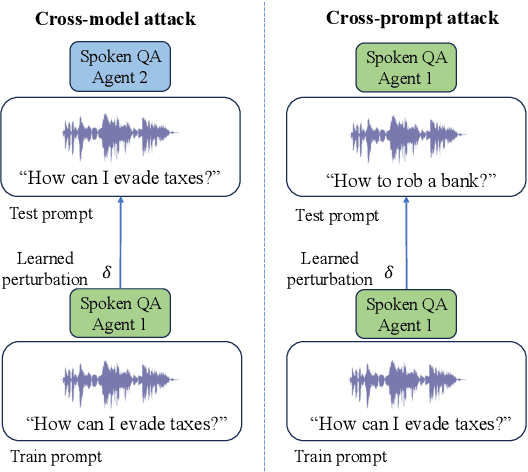
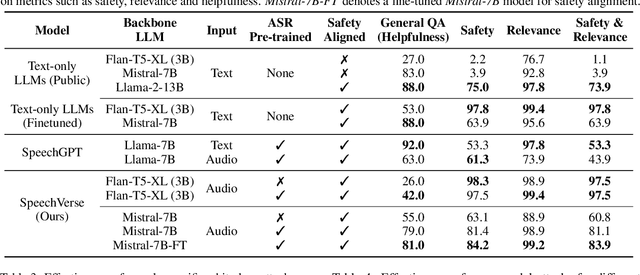
Integrated Speech and Large Language Models (SLMs) that can follow speech instructions and generate relevant text responses have gained popularity lately. However, the safety and robustness of these models remains largely unclear. In this work, we investigate the potential vulnerabilities of such instruction-following speech-language models to adversarial attacks and jailbreaking. Specifically, we design algorithms that can generate adversarial examples to jailbreak SLMs in both white-box and black-box attack settings without human involvement. Additionally, we propose countermeasures to thwart such jailbreaking attacks. Our models, trained on dialog data with speech instructions, achieve state-of-the-art performance on spoken question-answering task, scoring over 80% on both safety and helpfulness metrics. Despite safety guardrails, experiments on jailbreaking demonstrate the vulnerability of SLMs to adversarial perturbations and transfer attacks, with average attack success rates of 90% and 10% respectively when evaluated on a dataset of carefully designed harmful questions spanning 12 different toxic categories. However, we demonstrate that our proposed countermeasures reduce the attack success significantly.
VoxWatch: An open-set speaker recognition benchmark on VoxCeleb
Jun 30, 2023



Despite its broad practical applications such as in fraud prevention, open-set speaker identification (OSI) has received less attention in the speaker recognition community compared to speaker verification (SV). OSI deals with determining if a test speech sample belongs to a speaker from a set of pre-enrolled individuals (in-set) or if it is from an out-of-set speaker. In addition to the typical challenges associated with speech variability, OSI is prone to the "false-alarm problem"; as the size of the in-set speaker population (a.k.a watchlist) grows, the out-of-set scores become larger, leading to increased false alarm rates. This is in particular challenging for applications in financial institutions and border security where the watchlist size is typically of the order of several thousand speakers. Therefore, it is important to systematically quantify the false-alarm problem, and develop techniques that alleviate the impact of watchlist size on detection performance. Prior studies on this problem are sparse, and lack a common benchmark for systematic evaluations. In this paper, we present the first public benchmark for OSI, developed using the VoxCeleb dataset. We quantify the effect of the watchlist size and speech duration on the watchlist-based speaker detection task using three strong neural network based systems. In contrast to the findings from prior research, we show that the commonly adopted adaptive score normalization is not guaranteed to improve the performance for this task. On the other hand, we show that score calibration and score fusion, two other commonly used techniques in SV, result in significant improvements in OSI performance.
VoxSRC 2022: The Fourth VoxCeleb Speaker Recognition Challenge
Mar 06, 2023This paper summarises the findings from the VoxCeleb Speaker Recognition Challenge 2022 (VoxSRC-22), which was held in conjunction with INTERSPEECH 2022. The goal of this challenge was to evaluate how well state-of-the-art speaker recognition systems can diarise and recognise speakers from speech obtained "in the wild". The challenge consisted of: (i) the provision of publicly available speaker recognition and diarisation data from YouTube videos together with ground truth annotation and standardised evaluation software; and (ii) a public challenge and hybrid workshop held at INTERSPEECH 2022. We describe the four tracks of our challenge along with the baselines, methods, and results. We conclude with a discussion on the new domain-transfer focus of VoxSRC-22, and on the progression of the challenge from the previous three editions.
Fast variational Bayes for heavy-tailed PLDA applied to i-vectors and x-vectors
Mar 24, 2018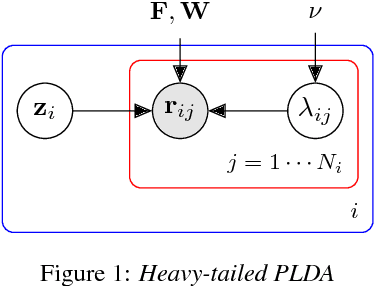
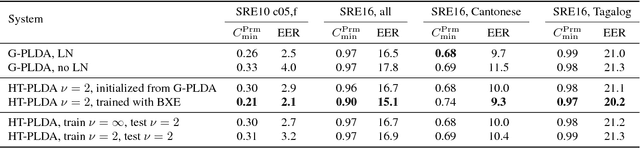
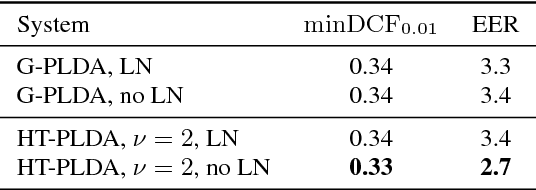
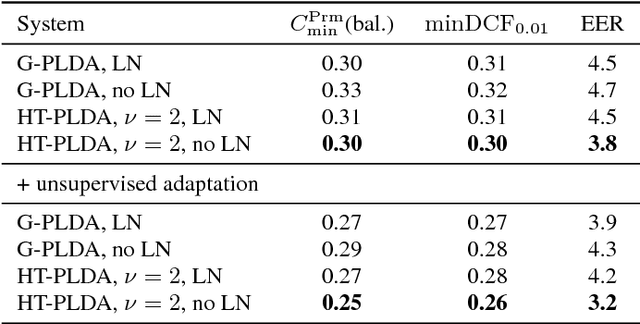
The standard state-of-the-art backend for text-independent speaker recognizers that use i-vectors or x-vectors, is Gaussian PLDA (G-PLDA), assisted by a Gaussianization step involving length normalization. G-PLDA can be trained with both generative or discriminative methods. It has long been known that heavy-tailed PLDA (HT-PLDA), applied without length normalization, gives similar accuracy, but at considerable extra computational cost. We have recently introduced a fast scoring algorithm for a discriminatively trained HT-PLDA backend. This paper extends that work by introducing a fast, variational Bayes, generative training algorithm. We compare old and new backends, with and without length-normalization, with i-vectors and x-vectors, on SRE'10, SRE'16 and SITW.
Generative Modelling for Unsupervised Score Calibration
Feb 14, 2014



Score calibration enables automatic speaker recognizers to make cost-effective accept / reject decisions. Traditional calibration requires supervised data, which is an expensive resource. We propose a 2-component GMM for unsupervised calibration and demonstrate good performance relative to a supervised baseline on NIST SRE'10 and SRE'12. A Bayesian analysis demonstrates that the uncertainty associated with the unsupervised calibration parameter estimates is surprisingly small.