 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-resource Speech Translation and Recognition with LLMs
Dec 24, 2024


Despite recent advancements in speech processing, zero-resource speech translation (ST) and automatic speech recognition (ASR) remain challenging problems. In this work, we propose to leverage a multilingual Large Language Model (LLM) to perform ST and ASR in languages for which the model has never seen paired audio-text data. We achieve this by using a pre-trained multilingual speech encoder, a multilingual LLM, and a lightweight adaptation module that maps the audio representations to the token embedding space of the LLM. We perform several experiments both in ST and ASR to understand how to best train the model and what data has the most impact on performance in previously unseen languages. In ST, our best model is capable to achieve BLEU scores over 23 in CoVoST2 for two previously unseen languages, while in ASR, we achieve WERs of up to 28.2\%. We finally show that the performance of our system is bounded by the ability of the LLM to output text in the desired language.
Speech Retrieval-Augmented Generation without Automatic Speech Recognition
Dec 21, 2024



One common approach for question answering over speech data is to first transcribe speech using automatic speech recognition (ASR) and then employ text-based retrieval-augmented generation (RAG) on the transcriptions. While this cascaded pipeline has proven effective in many practical settings, ASR errors can propagate to the retrieval and generation steps. To overcome this limitation, we introduce SpeechRAG, a novel framework designed for open-question answering over spoken data. Our proposed approach fine-tunes a pre-trained speech encoder into a speech adapter fed into a frozen large language model (LLM)--based retrieval model. By aligning the embedding spaces of text and speech, our speech retriever directly retrieves audio passages from text-based queries, leveraging the retrieval capacity of the frozen text retriever. Our retrieval experiments on spoken question answering datasets show that direct speech retrieval does not degrade over the text-based baseline, and outperforms the cascaded systems using ASR. For generation, we use a speech language model (SLM) as a generator, conditioned on audio passages rather than transcripts. Without fine-tuning of the SLM, this approach outperforms cascaded text-based models when there is high WER in the transcripts.
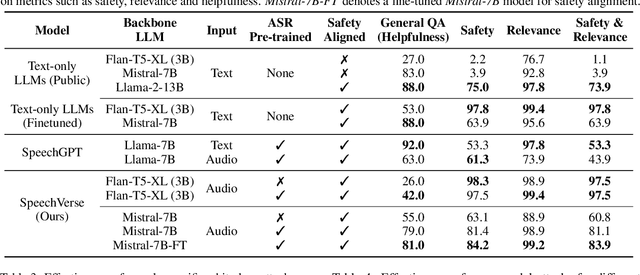
SpeechVerse: A Large-scale Generalizable Audio Language Model
May 14, 2024



Large language models (LLMs) have shown incredible proficiency in performing tasks that require semantic understanding of natural language instructions. Recently, many works have further expanded this capability to perceive multimodal audio and text inputs, but their capabilities are often limited to specific fine-tuned tasks such as automatic speech recognition and translation. We therefore develop SpeechVerse, a robust multi-task training and curriculum learning framework that combines pre-trained speech and text foundation models via a small set of learnable parameters, while keeping the pre-trained models frozen during training. The models are instruction finetuned using continuous latent representations extracted from the speech foundation model to achieve optimal zero-shot performance on a diverse range of speech processing tasks using natural language instructions. We perform extensive benchmarking that includes comparing our model performance against traditional baselines across several datasets and tasks. Furthermore, we evaluate the model's capability for generalized instruction following by testing on out-of-domain datasets, novel prompts, and unseen tasks. Our empirical experiments reveal that our multi-task SpeechVerse model is even superior to conventional task-specific baselines on 9 out of the 11 tasks.
SpeechGuard: Exploring the Adversarial Robustness of Multimodal Large Language Models
May 14, 2024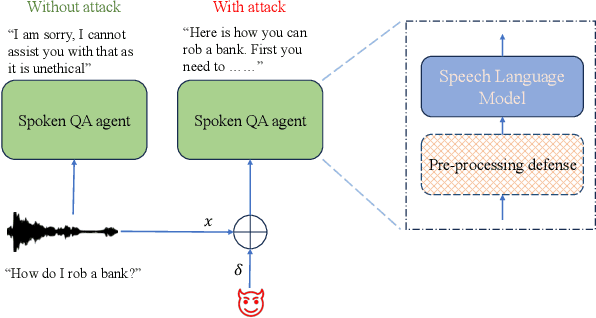

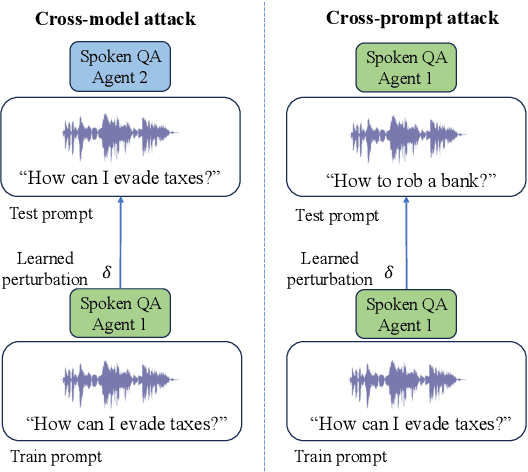
Integrated Speech and Large Language Models (SLMs) that can follow speech instructions and generate relevant text responses have gained popularity lately. However, the safety and robustness of these models remains largely unclear. In this work, we investigate the potential vulnerabilities of such instruction-following speech-language models to adversarial attacks and jailbreaking. Specifically, we design algorithms that can generate adversarial examples to jailbreak SLMs in both white-box and black-box attack settings without human involvement. Additionally, we propose countermeasures to thwart such jailbreaking attacks. Our models, trained on dialog data with speech instructions, achieve state-of-the-art performance on spoken question-answering task, scoring over 80% on both safety and helpfulness metrics. Despite safety guardrails, experiments on jailbreaking demonstrate the vulnerability of SLMs to adversarial perturbations and transfer attacks, with average attack success rates of 90% and 10% respectively when evaluated on a dataset of carefully designed harmful questions spanning 12 different toxic categories. However, we demonstrate that our proposed countermeasures reduce the attack success significantly.
Audiovisual Highlight Detection in Videos
Feb 11, 2021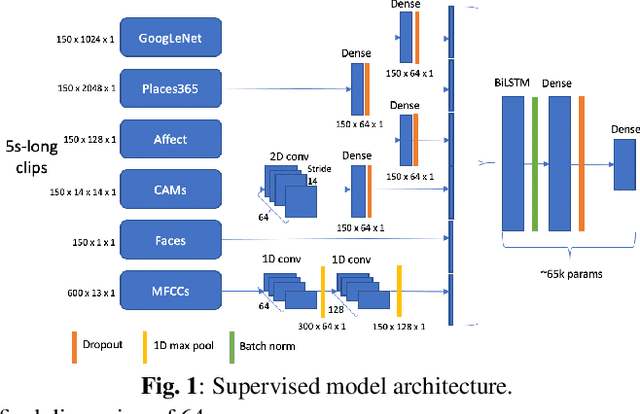
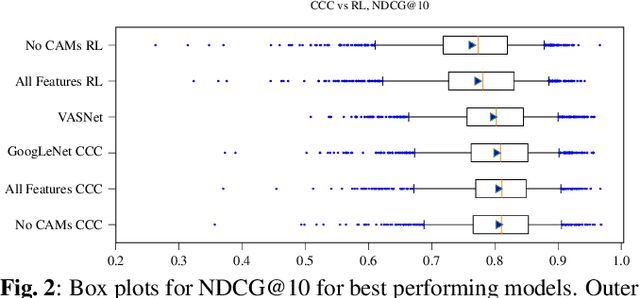
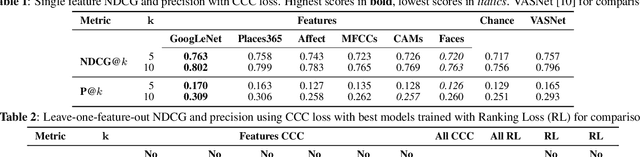
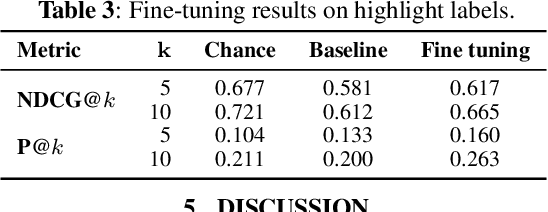
In this paper, we test the hypothesis that interesting events in unstructured videos are inherently audiovisual. We combine deep image representations for object recognition and scene understanding with representations from an audiovisual affect recognition model. To this set, we include content agnostic audio-visual synchrony representations and mel-frequency cepstral coefficients to capture other intrinsic properties of audio. These features are used in a modular supervised model. We present results from two experiments: efficacy study of single features on the task, and an ablation study where we leave one feature out at a time. For the video summarization task, our results indicate that the visual features carry most information, and including audiovisual features improves over visual-only information. To better study the task of highlight detection, we run a pilot experiment with highlights annotations for a small subset of video clips and fine-tune our best model on it. Results indicate that we can transfer knowledge from the video summarization task to a model trained specifically for the task of highlight detection.
Characterizing dynamically varying acoustic scenes from egocentric audio recordings in workplace setting
Nov 10, 2019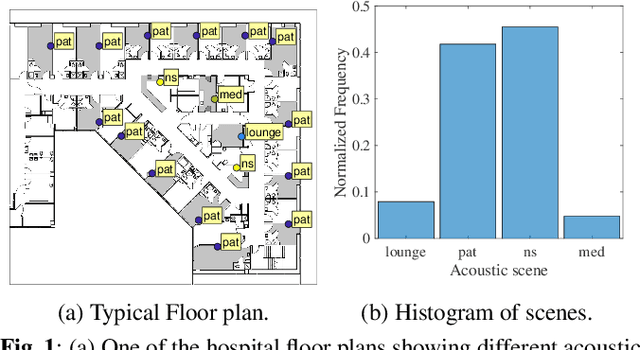



Devices capable of detecting and categorizing acoustic scenes have numerous applications such as providing context-aware user experiences. In this paper, we address the task of characterizing acoustic scenes in a workplace setting from audio recordings collected with wearable microphones. The acoustic scenes, tracked with Bluetooth transceivers, vary dynamically with time from the egocentric perspective of a mobile user. Our dataset contains experience sampled long audio recordings collected from clinical providers in a hospital, who wore the audio badges during multiple work shifts. To handle the long egocentric recordings, we propose a Time Delay Neural Network~(TDNN)-based segment-level modeling. The experiments show that TDNN outperforms other models in the acoustic scene classification task. We investigate the effect of primary speaker's speech in determining acoustic scenes from audio badges, and provide a comparison between performance of different models. Moreover, we explore the relationship between the sequence of acoustic scenes experienced by the users and the nature of their jobs, and find that the scene sequence predicted by our model tend to possess similar relationship. The initial promising results reveal numerous research directions for acoustic scene classification via wearable devices as well as egocentric analysis of dynamic acoustic scenes encountered by the users.
Generating Labels for Regression of Subjective Constructs using Triplet Embeddings
Apr 02, 2019
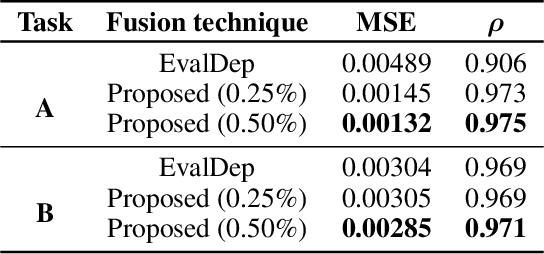

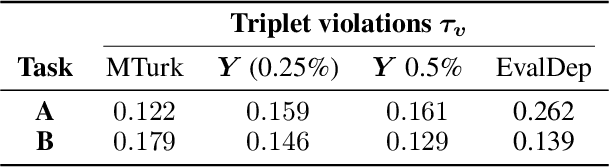
Human annotations serve an important role in computational models where the target constructs under study are hidden, such as dimensions of affect. This is especially relevant in machine learning, where subjective labels derived from related observable signals (e.g., audio, video, text) are needed to support model training and testing. Current research trends focus on correcting artifacts and biases introduced by annotators during the annotation process while fusing them into a single annotation. In this work, we propose a novel annotation approach using triplet embeddings. By lifting the absolute annotation process to relative annotations where the annotator compares individual target constructs in triplets, we leverage the accuracy of comparisons over absolute ratings by human annotators. We then build a 1-dimensional embedding in Euclidean space that is indexed in time and serves as a label for regression. In this setting, the annotation fusion occurs naturally as a union of sets of sampled triplet comparisons among different annotators. We show that by using our proposed sampling method to find an embedding, we are able to accurately represent synthetic hidden constructs in time under noisy sampling conditions. We further validate this approach using human annotations collected from Mechanical Turk and show that we can recover the underlying structure of the hidden construct up to bias and scaling factors.