 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentanglement for audio-visual emotion recognition using multitask setup
Feb 11, 2021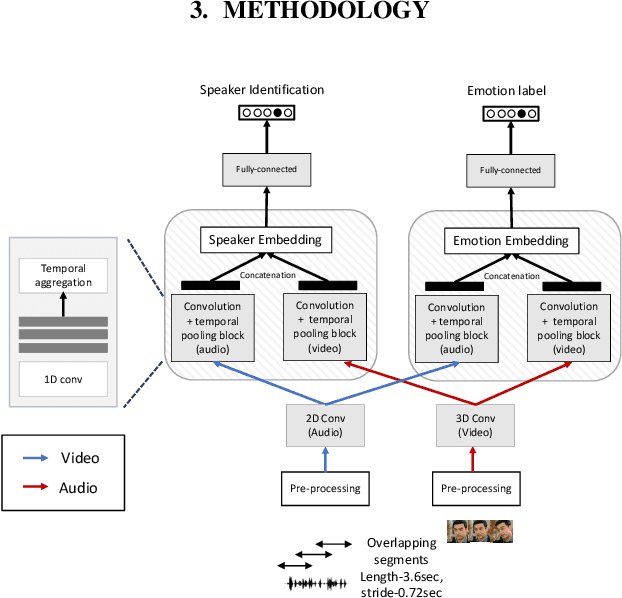
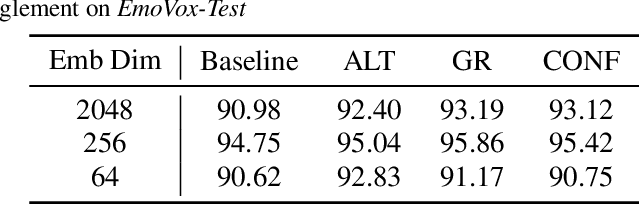
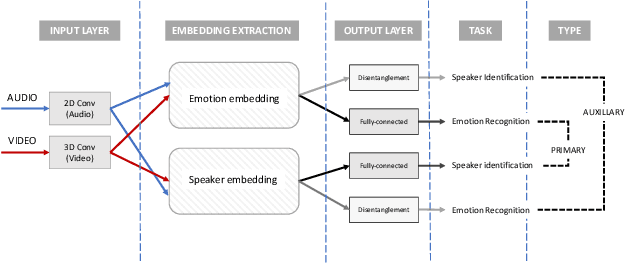
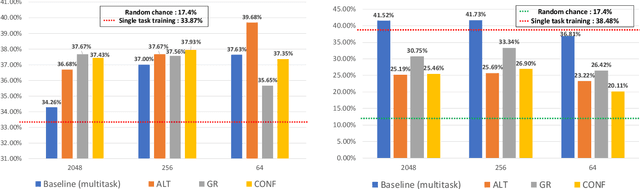
Deep learning models trained on audio-visual data have been successfully used to achieve state-of-the-art performance for emotion recognition. In particular, models trained with multitask learning have shown additional performance improvements. However, such multitask models entangle information between the tasks, encoding the mutual dependencies present in label distributions in the real world data used for training. This work explores the disentanglement of multimodal signal representations for the primary task of emotion recognition and a secondary person identification task. In particular, we developed a multitask framework to extract low-dimensional embeddings that aim to capture emotion specific information, while containing minimal information related to person identity. We evaluate three different techniques for disentanglement and report results of up to 13% disentanglement while maintaining emotion recognition performance.
Audiovisual Highlight Detection in Videos
Feb 11, 2021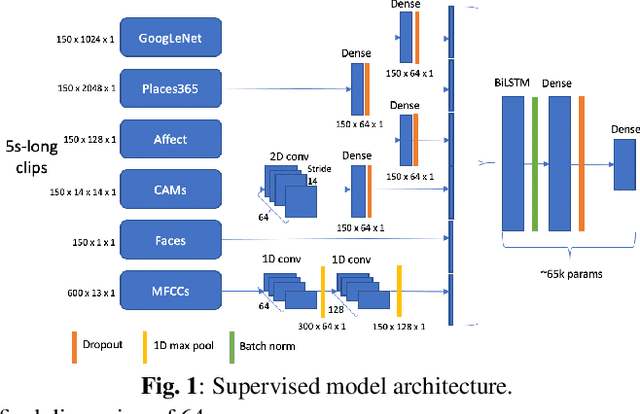
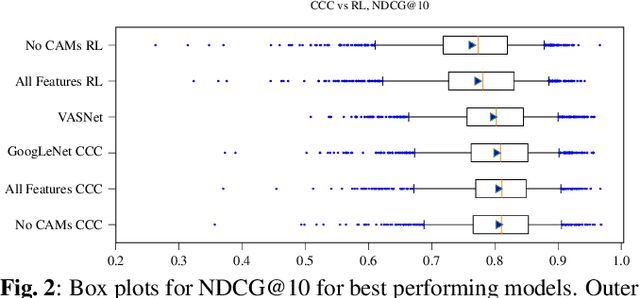
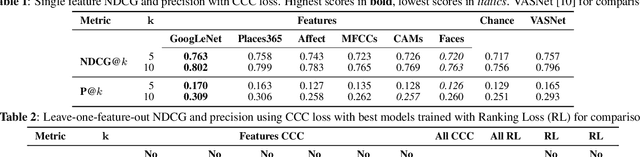
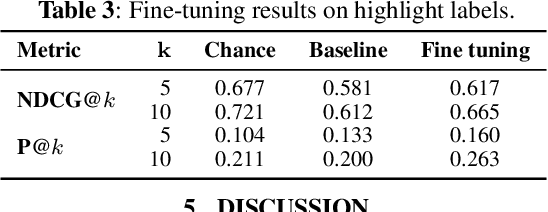
In this paper, we test the hypothesis that interesting events in unstructured videos are inherently audiovisual. We combine deep image representations for object recognition and scene understanding with representations from an audiovisual affect recognition model. To this set, we include content agnostic audio-visual synchrony representations and mel-frequency cepstral coefficients to capture other intrinsic properties of audio. These features are used in a modular supervised model. We present results from two experiments: efficacy study of single features on the task, and an ablation study where we leave one feature out at a time. For the video summarization task, our results indicate that the visual features carry most information, and including audiovisual features improves over visual-only information. To better study the task of highlight detection, we run a pilot experiment with highlights annotations for a small subset of video clips and fine-tune our best model on it. Results indicate that we can transfer knowledge from the video summarization task to a model trained specifically for the task of highlight detection.
Self-Supervised learning with cross-modal transformers for emotion recognition
Nov 20, 2020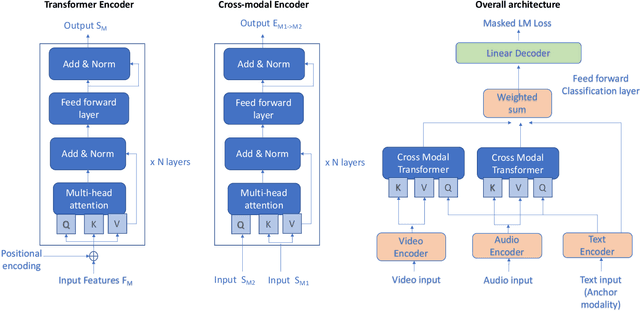
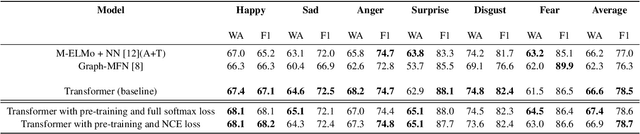
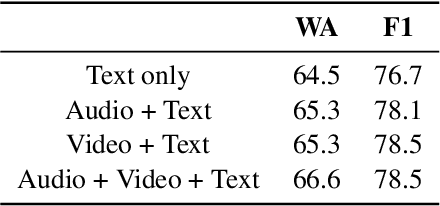
Emotion recognition is a challenging task due to limited availability of in-the-wild labeled datasets. Self-supervised learning has shown improvements on tasks with limited labeled datasets in domains like speech and natural language. Models such as BERT learn to incorporate context in word embeddings, which translates to improved performance in downstream tasks like question answering. In this work, we extend self-supervised training to multi-modal applications. We learn multi-modal representations using a transformer trained on the masked language modeling task with audio, visual and text features. This model is fine-tuned on the downstream task of emotion recognition. Our results on the CMU-MOSEI dataset show that this pre-training technique can improve the emotion recognition performance by up to 3% compared to the baseline.
Multi-modal embeddings using multi-task learning for emotion recognition
Sep 10, 2020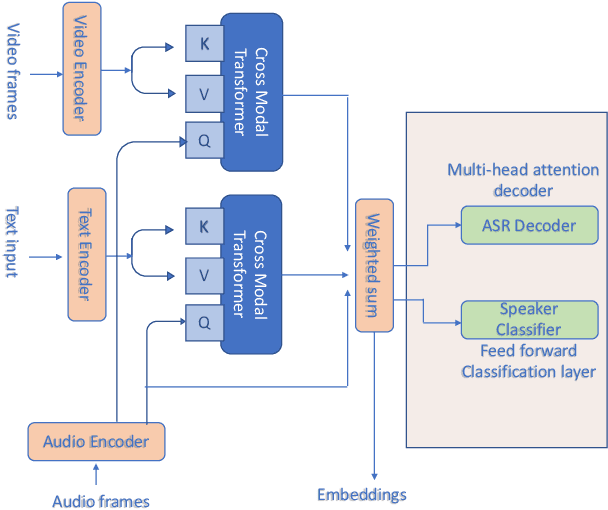
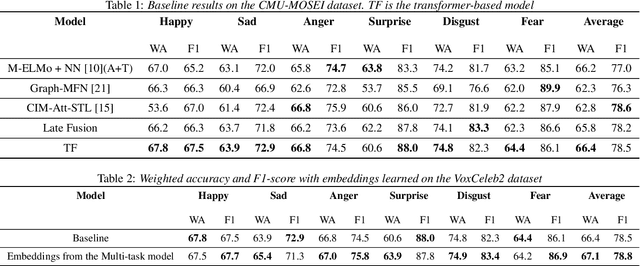
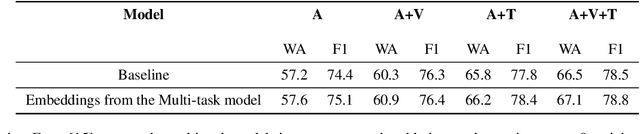
General embeddings like word2vec, GloVe and ELMo have shown a lot of success in natural language tasks. The embeddings are typically extracted from models that are built on general tasks such as skip-gram models and natural language generation. In this paper, we extend the work from natural language understanding to multi-modal architectures that use audio, visual and textual information for machine learning tasks. The embeddings in our network are extracted using the encoder of a transformer model trained using multi-task training. We use person identification and automatic speech recognition as the tasks in our embedding generation framework. We tune and evaluate the embeddings on the downstream task of emotion recognition and demonstrate that on the CMU-MOSEI dataset, the embeddings can be used to improve over previous state of the art results.
Multiresolution and Multimodal Speech Recognition with Transformers
Apr 29, 2020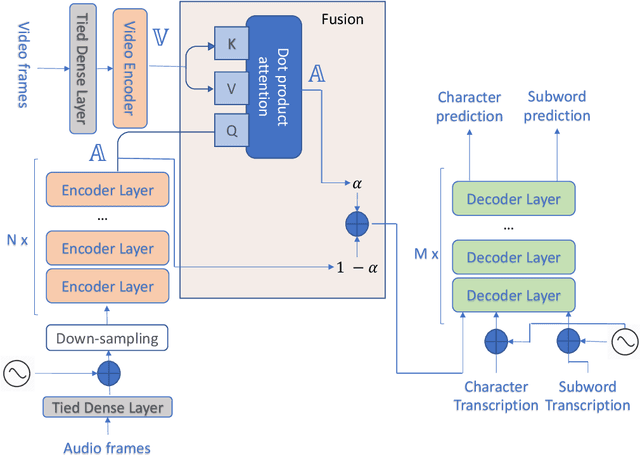
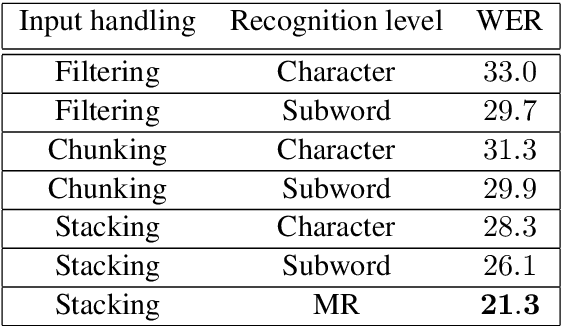
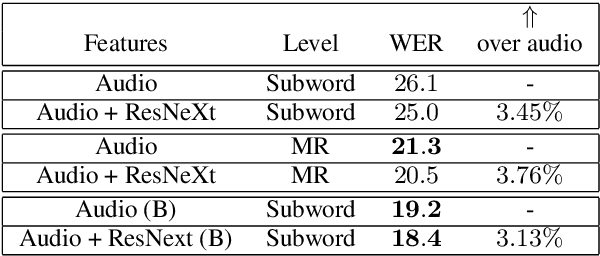

This paper presents an audio visual automatic speech recognition (AV-ASR) system using a Transformer-based architecture. We particularly focus on the scene context provided by the visual information, to ground the ASR. We extract representations for audio features in the encoder layers of the transformer and fuse video features using an additional crossmodal multihead attention layer. Additionally, we incorporate a multitask training criterion for multiresolution ASR, where we train the model to generate both character and subword level transcriptions. Experimental results on the How2 dataset, indicate that multiresolution training can speed up convergence by around 50% and relatively improves word error rate (WER) performance by upto 18% over subword prediction models. Further, incorporating visual information improves performance with relative gains upto 3.76% over audio only models. Our results are comparable to state-of-the-art Listen, Attend and Spell-based architectures.
Robust Multi-channel Speech Recognition using Frequency Aligned Network
Feb 06, 2020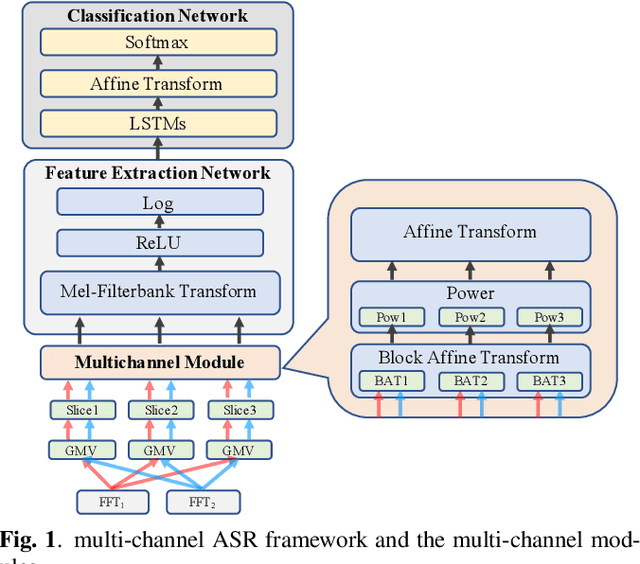
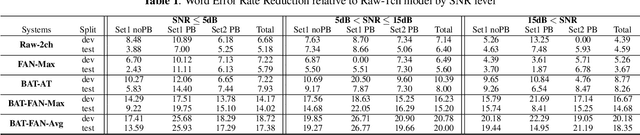
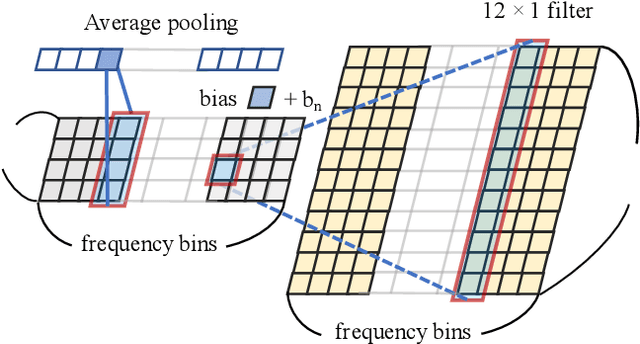

Conventional speech enhancement technique such as beamforming has known benefits for far-field speech recognition. Our own work in frequency-domain multi-channel acoustic modeling has shown additional improvements by training a spatial filtering layer jointly within an acoustic model. In this paper, we further develop this idea and use frequency aligned network for robust multi-channel automatic speech recognition (ASR). Unlike an affine layer in the frequency domain, the proposed frequency aligned component prevents one frequency bin influencing other frequency bins. We show that this modification not only reduces the number of parameters in the model but also significantly and improves the ASR performance. We investigate effects of frequency aligned network through ASR experiments on the real-world far-field data where users are interacting with an ASR system in uncontrolled acoustic environments. We show that our multi-channel acoustic model with a frequency aligned network shows up to 18% relative reduction in word error rate.
Fully Learnable Front-End for Multi-Channel Acoustic Modeling using Semi-Supervised Learning
Feb 01, 2020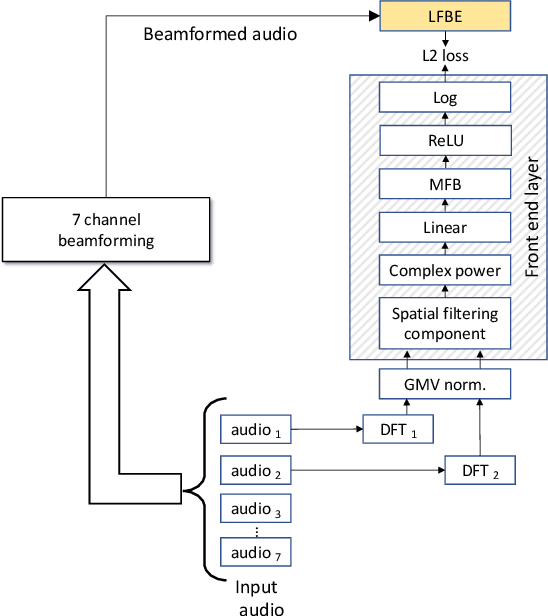
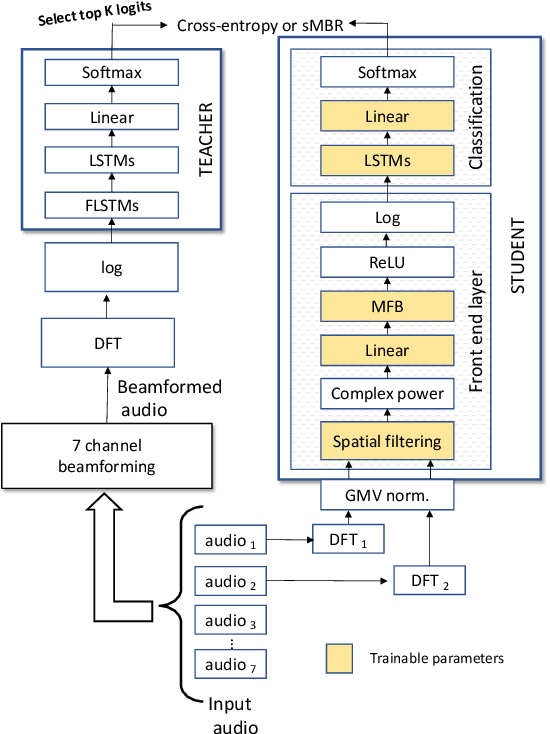

In this work, we investigated the teacher-student training paradigm to train a fully learnable multi-channel acoustic model for far-field automatic speech recognition (ASR). Using a large offline teacher model trained on beamformed audio, we trained a simpler multi-channel student acoustic model used in the speech recognition system. For the student, both multi-channel feature extraction layers and the higher classification layers were jointly trained using the logits from the teacher model. In our experiments, compared to a baseline model trained on about 600 hours of transcribed data, a relative word-error rate (WER) reduction of about 27.3% was achieved when using an additional 1800 hours of untranscribed data. We also investigated the benefit of pre-training the multi-channel front end to output the beamformed log-mel filter bank energies (LFBE) using L2 loss. We find that pre-training improves the word error rate by 10.7% when compared to a multi-channel model directly initialized with a beamformer and mel-filter bank coefficients for the front end. Finally, combining pre-training and teacher-student training produces a WER reduction of 31% compared to our baseline.
Improving noise robustness of automatic speech recognition via parallel data and teacher-student learning
Jan 11, 2019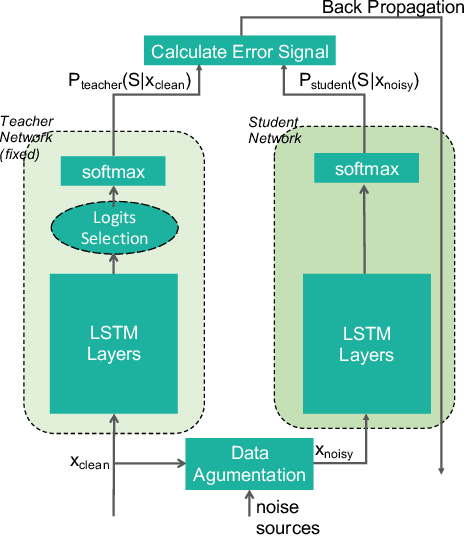
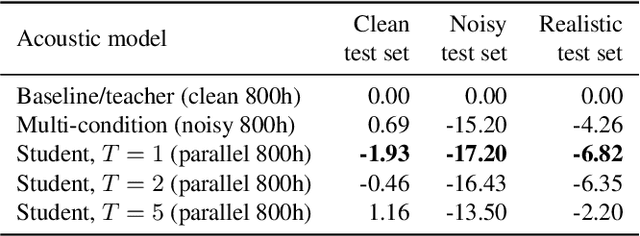
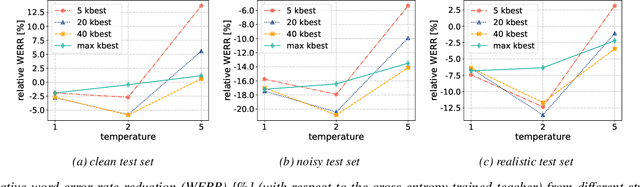
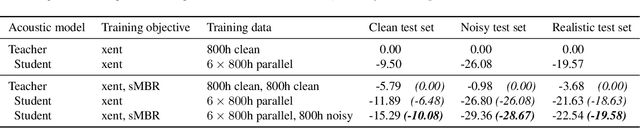
For real-world speech recognition applications, noise robustness is still a challenge. In this work, we adopt the teacher-student (T/S) learning technique using a parallel clean and noisy corpus for improving automatic speech recognition (ASR) performance under multimedia noise. On top of that, we apply a logits selection method which only preserves the k highest values to prevent wrong emphasis of knowledge from the teacher and to reduce bandwidth needed for transferring data. We incorporate up to 8000 hours of untranscribed data for training and present our results on sequence trained models apart from cross entropy trained ones. The best sequence trained student model yields relative word error rate (WER) reductions of approximately 10.1%, 28.7% and 19.6% on our clean, simulated noisy and real test sets respectively comparing to a sequence trained teacher.