 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal2Global query Alignment for Video Instance Segmentation
Jul 27, 2025



Online video segmentation methods excel at handling long sequences and capturing gradual changes, making them ideal for real-world applications. However, achieving temporally consistent predictions remains a challenge, especially with gradual accumulation of noise or drift in on-line propagation, abrupt occlusions and scene transitions. This paper introduces Local2Global, an online framework, for video instance segmentation, exhibiting state-of-the-art performance with simple baseline and training purely in online fashion. Leveraging the DETR-based query propagation framework, we introduce two novel sets of queries:(1) local queries that capture initial object-specific spatial features from each frame and (2) global queries containing past spatio-temporal representations. We propose the L2G-aligner, a novel lightweight transformer decoder, to facilitate an early alignment between local and global queries. This alignment allows our model to effectively utilize current frame information while maintaining temporal consistency, producing a smooth transition between frames. Furthermore, L2G-aligner is integrated within the segmentation model, without relying on additional complex heuristics, or memory mechanisms. Extensive experiments across various challenging VIS and VPS datasets showcase the superiority of our method with simple online training, surpassing current benchmarks without bells and rings. For instance, we achieve 54.3 and 49.4 AP on Youtube-VIS-19/-21 datasets and 37.0 AP on OVIS dataset respectively withthe ResNet-50 backbone.
Disentanglement for audio-visual emotion recognition using multitask setup
Feb 11, 2021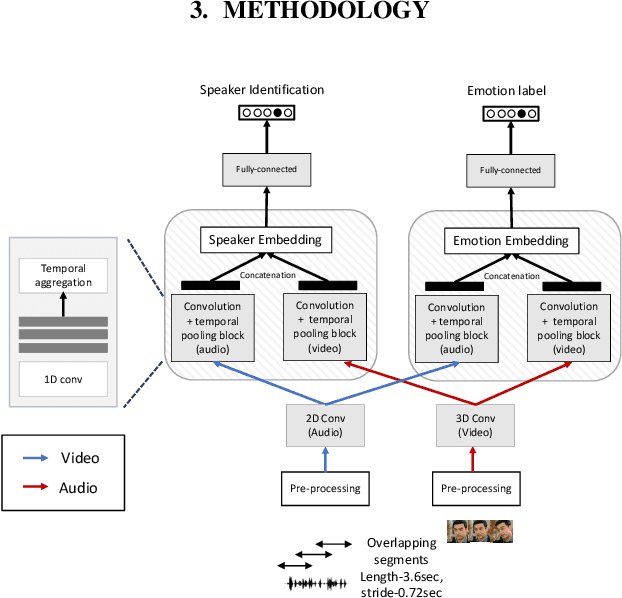
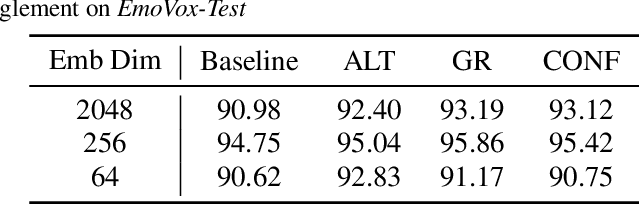
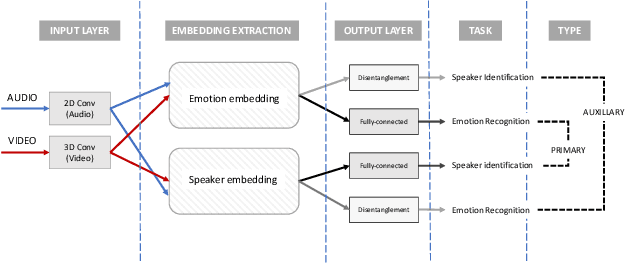
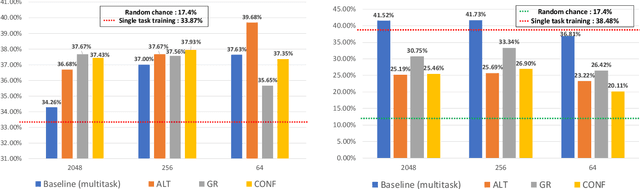
Deep learning models trained on audio-visual data have been successfully used to achieve state-of-the-art performance for emotion recognition. In particular, models trained with multitask learning have shown additional performance improvements. However, such multitask models entangle information between the tasks, encoding the mutual dependencies present in label distributions in the real world data used for training. This work explores the disentanglement of multimodal signal representations for the primary task of emotion recognition and a secondary person identification task. In particular, we developed a multitask framework to extract low-dimensional embeddings that aim to capture emotion specific information, while containing minimal information related to person identity. We evaluate three different techniques for disentanglement and report results of up to 13% disentanglement while maintaining emotion recognition performance.
Self-Supervised learning with cross-modal transformers for emotion recognition
Nov 20, 2020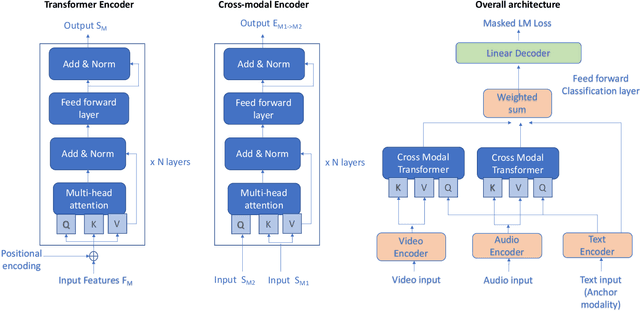
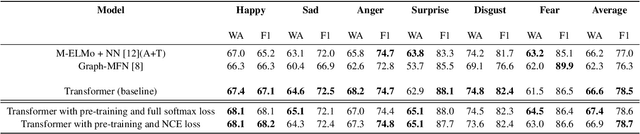
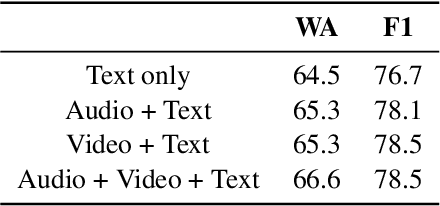
Emotion recognition is a challenging task due to limited availability of in-the-wild labeled datasets. Self-supervised learning has shown improvements on tasks with limited labeled datasets in domains like speech and natural language. Models such as BERT learn to incorporate context in word embeddings, which translates to improved performance in downstream tasks like question answering. In this work, we extend self-supervised training to multi-modal applications. We learn multi-modal representations using a transformer trained on the masked language modeling task with audio, visual and text features. This model is fine-tuned on the downstream task of emotion recognition. Our results on the CMU-MOSEI dataset show that this pre-training technique can improve the emotion recognition performance by up to 3% compared to the baseline.
Multi-modal embeddings using multi-task learning for emotion recognition
Sep 10, 2020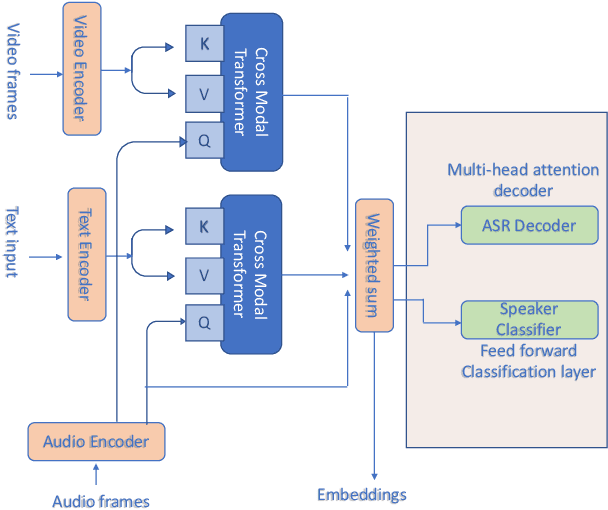
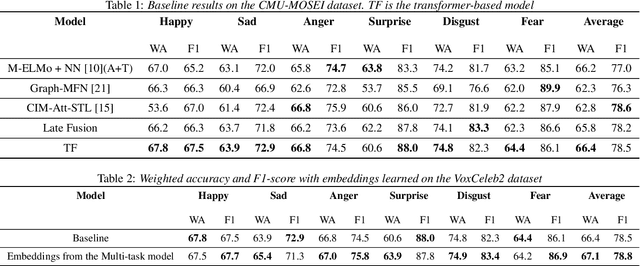
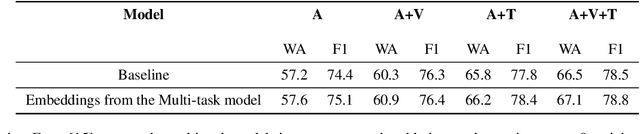
General embeddings like word2vec, GloVe and ELMo have shown a lot of success in natural language tasks. The embeddings are typically extracted from models that are built on general tasks such as skip-gram models and natural language generation. In this paper, we extend the work from natural language understanding to multi-modal architectures that use audio, visual and textual information for machine learning tasks. The embeddings in our network are extracted using the encoder of a transformer model trained using multi-task training. We use person identification and automatic speech recognition as the tasks in our embedding generation framework. We tune and evaluate the embeddings on the downstream task of emotion recognition and demonstrate that on the CMU-MOSEI dataset, the embeddings can be used to improve over previous state of the art results.
Multiresolution and Multimodal Speech Recognition with Transformers
Apr 29, 2020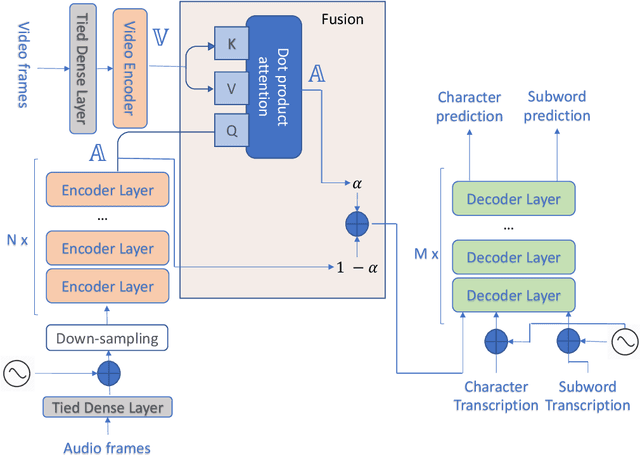
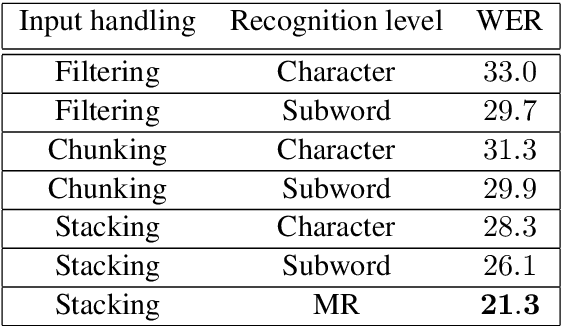
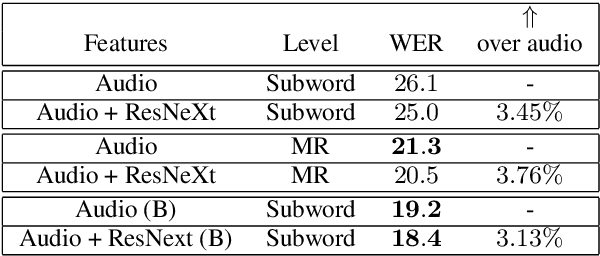

This paper presents an audio visual automatic speech recognition (AV-ASR) system using a Transformer-based architecture. We particularly focus on the scene context provided by the visual information, to ground the ASR. We extract representations for audio features in the encoder layers of the transformer and fuse video features using an additional crossmodal multihead attention layer. Additionally, we incorporate a multitask training criterion for multiresolution ASR, where we train the model to generate both character and subword level transcriptions. Experimental results on the How2 dataset, indicate that multiresolution training can speed up convergence by around 50% and relatively improves word error rate (WER) performance by upto 18% over subword prediction models. Further, incorporating visual information improves performance with relative gains upto 3.76% over audio only models. Our results are comparable to state-of-the-art Listen, Attend and Spell-based architectures.