 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVOX-KRIKRI: Unifying Speech and Language through Continuous Fusion
Sep 19, 2025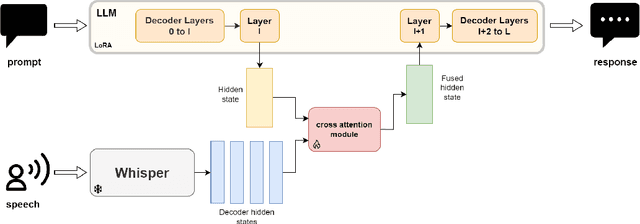
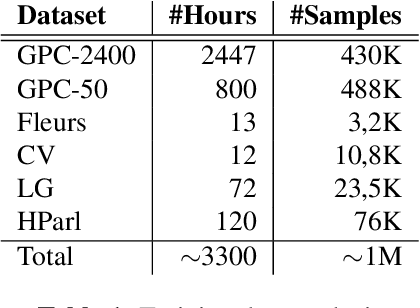
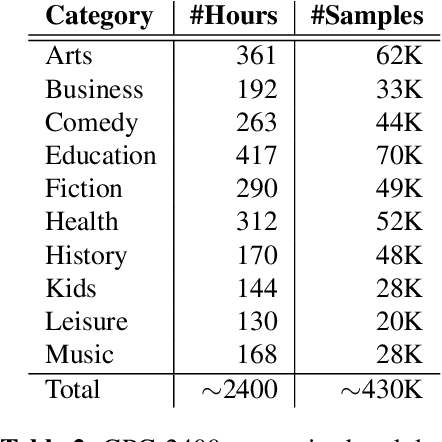
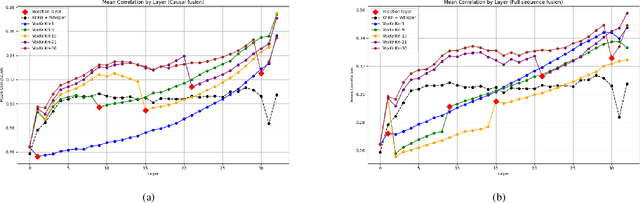
We present a multimodal fusion framework that bridges pre-trained decoder-based large language models (LLM) and acoustic encoder-decoder architectures such as Whisper, with the aim of building speech-enabled LLMs. Instead of directly using audio embeddings, we explore an intermediate audio-conditioned text space as a more effective mechanism for alignment. Our method operates fully in continuous text representation spaces, fusing Whisper's hidden decoder states with those of an LLM through cross-modal attention, and supports both offline and streaming modes. We introduce \textit{VoxKrikri}, the first Greek speech LLM, and show through analysis that our approach effectively aligns representations across modalities. These results highlight continuous space fusion as a promising path for multilingual and low-resource speech LLMs, while achieving state-of-the-art results for Automatic Speech Recognition in Greek, providing an average $\sim20\%$ relative improvement across benchmarks.
Masked Diffusion Language Models with Frequency-Informed Training
Sep 05, 2025We present a masked diffusion language modeling framework for data-efficient training for the BabyLM 2025 Challenge. Our approach applies diffusion training objectives to language modeling under strict data constraints, incorporating frequency-informed masking that prioritizes learning from rare tokens while maintaining theoretical validity. We explore multiple noise scheduling strategies, including two-mode approaches, and investigate different noise weighting schemes within the NELBO objective. We evaluate our method on the BabyLM benchmark suite, measuring linguistic competence, world knowledge, and human-likeness. Results show performance competitive to hybrid autoregressive-masked baselines, demonstrating that diffusion-based training offers a viable alternative for data-restricted language learning.
Auto-Compressing Networks
Jun 11, 2025Deep neural networks with short residual connections have demonstrated remarkable success across domains, but increasing depth often introduces computational redundancy without corresponding improvements in representation quality. In this work, we introduce Auto-Compressing Networks (ACNs), an architectural variant where additive long feedforward connections from each layer to the output replace traditional short residual connections. ACNs showcase a unique property we coin as "auto-compression", the ability of a network to organically compress information during training with gradient descent, through architectural design alone. Through auto-compression, information is dynamically "pushed" into early layers during training, enhancing their representational quality and revealing potential redundancy in deeper ones. We theoretically show that this property emerges from layer-wise training patterns present in ACNs, where layers are dynamically utilized during training based on task requirements. We also find that ACNs exhibit enhanced noise robustness compared to residual networks, superior performance in low-data settings, improved transfer learning capabilities, and mitigate catastrophic forgetting suggesting that they learn representations that generalize better despite using fewer parameters. Our results demonstrate up to 18% reduction in catastrophic forgetting and 30-80% architectural compression while maintaining accuracy across vision transformers, MLP-mixers, and BERT architectures. Furthermore, we demonstrate that coupling ACNs with traditional pruning techniques, enables significantly better sparsity-performance trade-offs compared to conventional architectures. These findings establish ACNs as a practical approach to developing efficient neural architectures that automatically adapt their computational footprint to task complexity, while learning robust representations.
MSDA: Combining Pseudo-labeling and Self-Supervision for Unsupervised Domain Adaptation in ASR
May 30, 2025In this work, we investigate the Meta PL unsupervised domain adaptation framework for Automatic Speech Recognition (ASR). We introduce a Multi-Stage Domain Adaptation pipeline (MSDA), a sample-efficient, two-stage adaptation approach that integrates self-supervised learning with semi-supervised techniques. MSDA is designed to enhance the robustness and generalization of ASR models, making them more adaptable to diverse conditions. It is particularly effective for low-resource languages like Greek and in weakly supervised scenarios where labeled data is scarce or noisy. Through extensive experiments, we demonstrate that Meta PL can be applied effectively to ASR tasks, achieving state-of-the-art results, significantly outperforming state-of-the-art methods, and providing more robust solutions for unsupervised domain adaptation in ASR. Our ablations highlight the necessity of utilizing a cascading approach when combining self-supervision with self-training.
Krikri: Advancing Open Large Language Models for Greek
May 19, 2025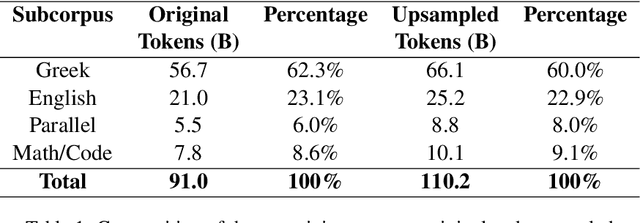
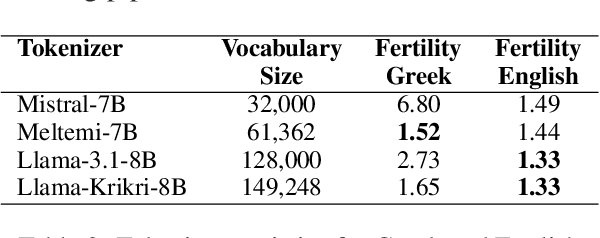
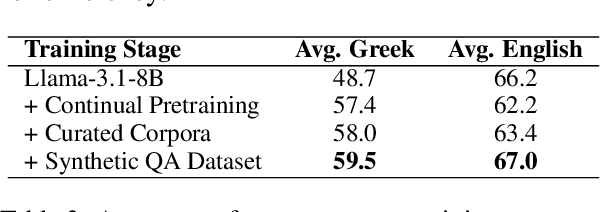

We introduce Llama-Krikri-8B, a cutting-edge Large Language Model tailored for the Greek language, built on Meta's Llama 3.1-8B. Llama-Krikri-8B has been extensively trained on high-quality Greek data to ensure superior adaptation to linguistic nuances. With 8 billion parameters, it offers advanced capabilities while maintaining efficient computational performance. Llama-Krikri-8B supports both Modern Greek and English, and is also equipped to handle polytonic text and Ancient Greek. The chat version of Llama-Krikri-8B features a multi-stage post-training pipeline, utilizing both human and synthetic instruction and preference data, by applying techniques such as MAGPIE. In addition, for evaluation, we propose three novel public benchmarks for Greek. Our evaluation on existing as well as the proposed benchmarks shows notable improvements over comparable Greek and multilingual LLMs in both natural language understanding and generation as well as code generation.
BloomWise: Enhancing Problem-Solving capabilities of Large Language Models using Bloom's-Taxonomy-Inspired Prompts
Oct 05, 2024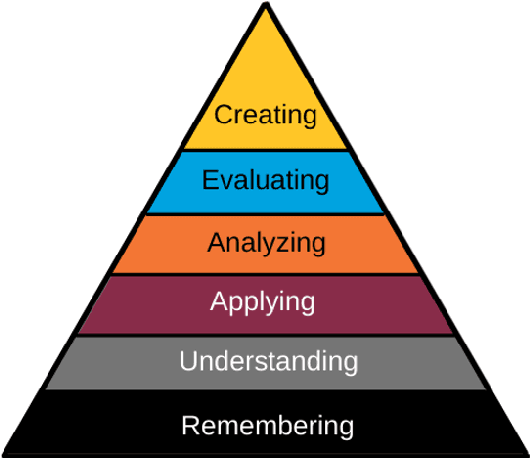


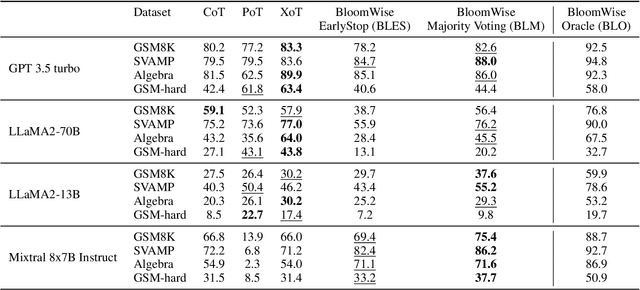
Despite the continuous progress of Large Language Models (LLMs) across various tasks, their performance on mathematical problems and reasoning tasks remains limited. This limitation can be attributed, among other factors, to the inherent difficulty of these problems and the fact that solutions often consist of multiple steps, potentially of varying nature, making it challenging for a single prompting technique to execute all required steps. To address this, we introduce BloomWise, a new prompting technique, inspired by Bloom's Taxonomy, aiming to improve LLMs' performance in solving such problems by encouraging them to approach the problem starting from simple, i.e., remembering, and progressing to higher cognitive skills, i.e., analyzing, until the correct solution is reached. The decision regarding the need to employ more sophisticated cognitive skills is based on self-evaluation performed by the LLM. Thus, we encourage the LLM to deploy the appropriate cognitive processes. In extensive experiments across 4 popular math reasoning datasets, we have demonstrated the effectiveness of our proposed approach. We also present extensive ablations, analyzing the strengths of each module within our system.
Meltemi: The first open Large Language Model for Greek
Jul 30, 2024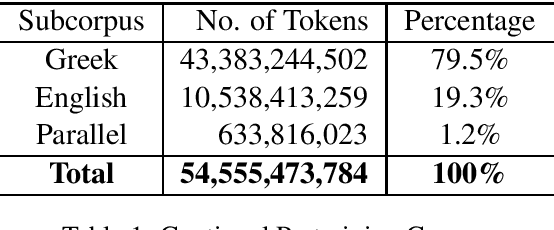
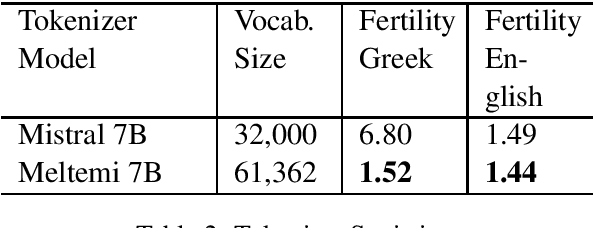
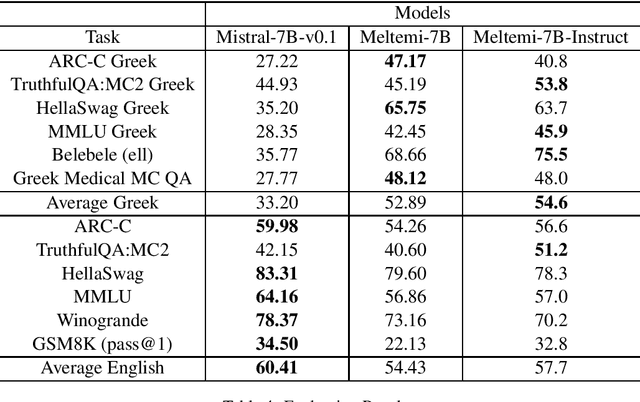
We describe the development and capabilities of Meltemi 7B, the first open Large Language Model for the Greek language. Meltemi 7B has 7 billion parameters and is trained on a 40 billion token Greek corpus. For the development of Meltemi 7B, we adapt Mistral, by continuous pretraining on the Greek Corpus. Meltemi 7B contains up-to-date information up to September 2023. Furthermore, we have translated and curated a Greek instruction corpus, which has been used for the instruction-tuning of a chat model, named Meltemi 7B Instruct. Special care has been given to the alignment and the removal of toxic content for the Meltemi 7B Instruct. The developed models are evaluated on a broad set of collected evaluation corpora, and examples of prompts and responses are presented. Both Meltemi 7B and Meltemi 7B Instruct are available at https://huggingface.co/ilsp under the Apache 2.0 license.
The Greek podcast corpus: Competitive speech models for low-resourced languages with weakly supervised data
Jun 21, 2024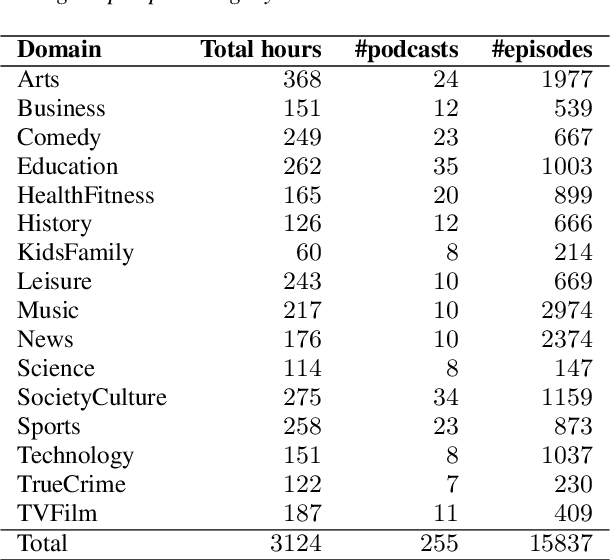
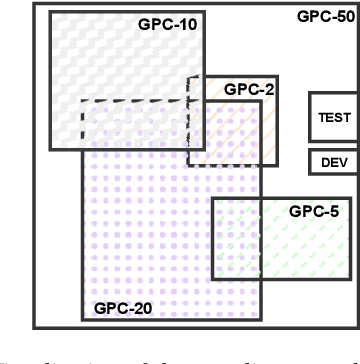
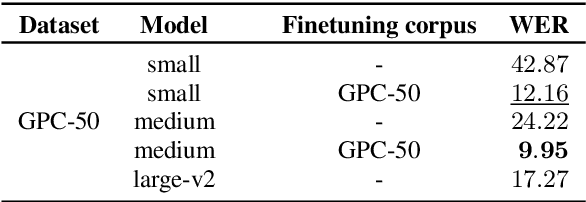
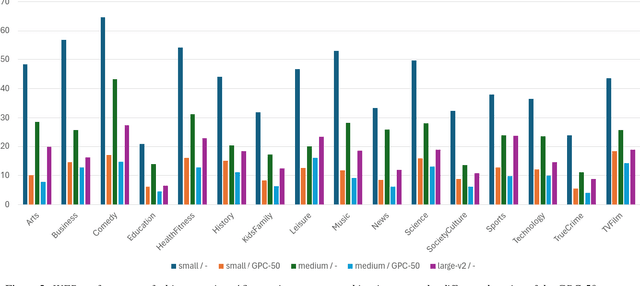
The development of speech technologies for languages with limited digital representation poses significant challenges, primarily due to the scarcity of available data. This issue is exacerbated in the era of large, data-intensive models. Recent research has underscored the potential of leveraging weak supervision to augment the pool of available data. In this study, we compile an 800-hour corpus of Modern Greek from podcasts and employ Whisper large-v3 to generate silver transcriptions. This corpus is utilized to fine-tune our models, aiming to assess the efficacy of this approach in enhancing ASR performance. Our analysis spans 16 distinct podcast domains, alongside evaluations on established datasets for Modern Greek. The findings indicate consistent WER improvements, correlating with increases in both data volume and model size. Our study confirms that assembling large, weakly supervised corpora serves as a cost-effective strategy for advancing speech technologies in under-resourced languages.
Predicting positive transfer for improved low-resource speech recognition using acoustic pseudo-tokens
Feb 03, 2024



While massively multilingual speech models like wav2vec 2.0 XLSR-128 can be directly fine-tuned for automatic speech recognition (ASR), downstream performance can still be relatively poor on languages that are under-represented in the pre-training data. Continued pre-training on 70-200 hours of untranscribed speech in these languages can help -- but what about languages without that much recorded data? For such cases, we show that supplementing the target language with data from a similar, higher-resource 'donor' language can help. For example, continued pre-training on only 10 hours of low-resource Punjabi supplemented with 60 hours of donor Hindi is almost as good as continued pretraining on 70 hours of Punjabi. By contrast, sourcing data from less similar donors like Bengali does not improve ASR performance. To inform donor language selection, we propose a novel similarity metric based on the sequence distribution of induced acoustic units: the Acoustic Token Distribution Similarity (ATDS). Across a set of typologically different target languages (Punjabi, Galician, Iban, Setswana), we show that the ATDS between the target language and its candidate donors precisely predicts target language ASR performance.
Investigating Personalization Methods in Text to Music Generation
Sep 20, 2023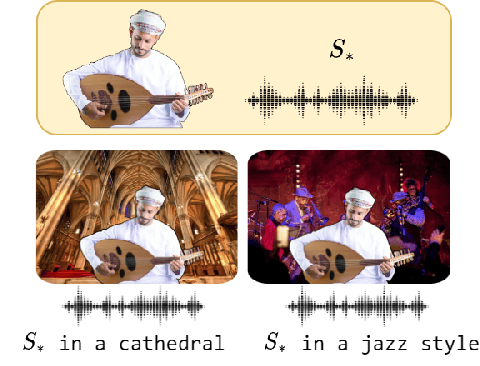
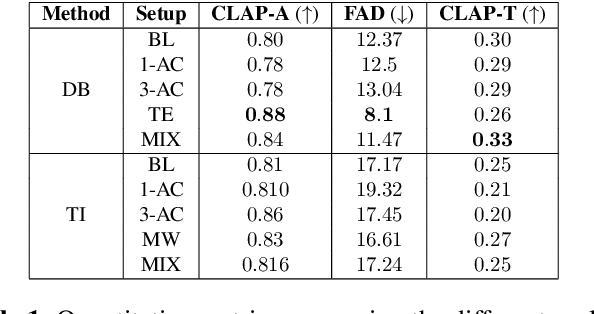
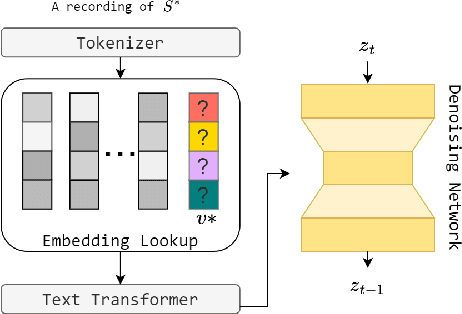
In this work, we investigate the personalization of text-to-music diffusion models in a few-shot setting. Motivated by recent advances in the computer vision domain, we are the first to explore the combination of pre-trained text-to-audio diffusers with two established personalization methods. We experiment with the effect of audio-specific data augmentation on the overall system performance and assess different training strategies. For evaluation, we construct a novel dataset with prompts and music clips. We consider both embedding-based and music-specific metrics for quantitative evaluation, as well as a user study for qualitative evaluation. Our analysis shows that similarity metrics are in accordance with user preferences and that current personalization approaches tend to learn rhythmic music constructs more easily than melody. The code, dataset, and example material of this study are open to the research community.