 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Scientific Discourse: Machine Translation for the Scientific Domain
May 20, 2026The increasing volume of scientific research necessitates effective communication across language barriers. Machine translation (MT) offers a promising solution for accessing international publications. However, the scientific domain presents unique challenges due to its specialized vocabulary and complex sentence structures. In this paper, we present the development of a collection of parallel and monolingual corpora for the scientific domain. The corpora target the language pairs Spanish-English, French-English, and Portuguese-English. For each language pair, we create a large general scientific corpus as well as four smaller corpora focused on the domains of: Cancer Research, Energy Research, Neuroscience, and Transportation research. To evaluate the quality of these corpora, we utilize them for fine-tuning general-purpose neural machine translation (NMT) systems. We provide details regarding the corpus creation process, the fine-tuning strategies employed, and we conclude with the evaluation results.
Ancient Greek to Modern Greek Machine Translation: A Novel Benchmark and Fine-Tuning Experiments on LLMs and NMT Models
May 18, 2026Machine Translation (MT) for Ancient Greek (AG) to Modern Greek (MG) is a low-resource task, constrained by the lack of large-scale, high-quality parallel data. We address this gap by introducing the AG-MG Parallel Corpus, a new resource containing 132,481 sentence-aligned pairs derived from literary, historical, and biblical texts. We present a novel corpus creation pipeline that combines web-scraped, excerpt-level data with a multi-stage sentence-level alignment, and refinement process. Our method uses VecAlign with LaBSE embeddings, which we first fine-tune on a manually-aligned AG-MG subset, followed by an LLM-based error/misalignment correction phase using Gemini 2.5 Flash to ensure high alignment quality. Furthermore, we provide the first comprehensive benchmark of modern MT models on this task, evaluating three fine-tuning strategies across NMT models (NLLB, M2M100) and a Greek LLM (Llama-Krikri-8B). Our experiments show that fine-tuning yields significant improvements over base models, increasing performance by up to +10.3 BLEU points. Specifically, full-parameter fine-tuning of Llama-Krikri-8B achieves the highest overall performance with a BLEU score of 13.16, while the QLoRA-adapted M2M100-1.2B model demonstrates the largest relative gains and highly competitive results. Our dataset and models represent a significant contribution to Greek NLP.
* 14 pages. Accepted for presentation at the 15th Language Resources and Evaluation Conference (LREC 2026), Palma, Mallorca, Spain
Krikri: Advancing Open Large Language Models for Greek
May 19, 2025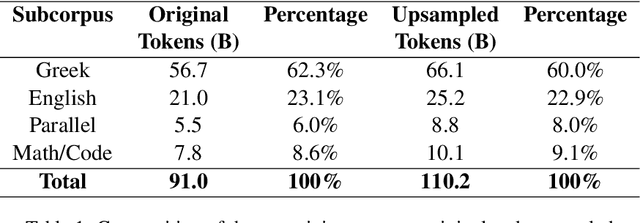
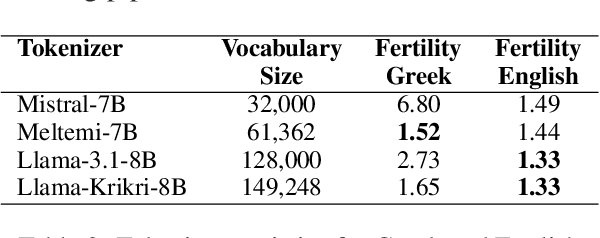
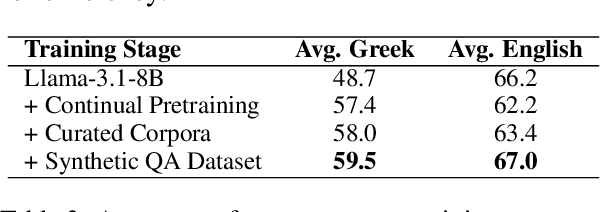

We introduce Llama-Krikri-8B, a cutting-edge Large Language Model tailored for the Greek language, built on Meta's Llama 3.1-8B. Llama-Krikri-8B has been extensively trained on high-quality Greek data to ensure superior adaptation to linguistic nuances. With 8 billion parameters, it offers advanced capabilities while maintaining efficient computational performance. Llama-Krikri-8B supports both Modern Greek and English, and is also equipped to handle polytonic text and Ancient Greek. The chat version of Llama-Krikri-8B features a multi-stage post-training pipeline, utilizing both human and synthetic instruction and preference data, by applying techniques such as MAGPIE. In addition, for evaluation, we propose three novel public benchmarks for Greek. Our evaluation on existing as well as the proposed benchmarks shows notable improvements over comparable Greek and multilingual LLMs in both natural language understanding and generation as well as code generation.
Meltemi: The first open Large Language Model for Greek
Jul 30, 2024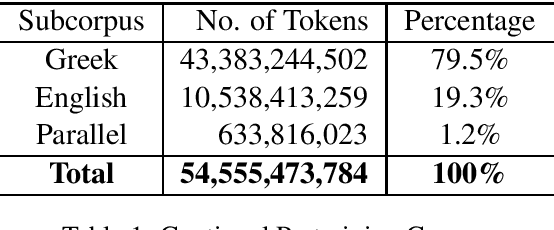
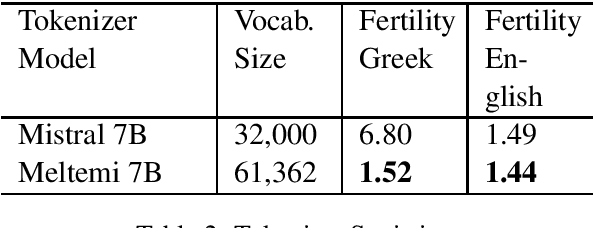
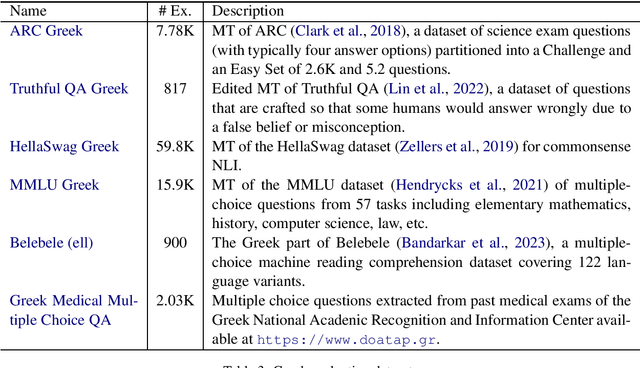
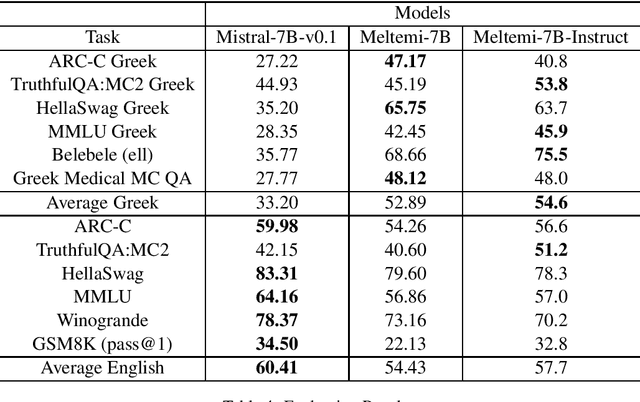
We describe the development and capabilities of Meltemi 7B, the first open Large Language Model for the Greek language. Meltemi 7B has 7 billion parameters and is trained on a 40 billion token Greek corpus. For the development of Meltemi 7B, we adapt Mistral, by continuous pretraining on the Greek Corpus. Meltemi 7B contains up-to-date information up to September 2023. Furthermore, we have translated and curated a Greek instruction corpus, which has been used for the instruction-tuning of a chat model, named Meltemi 7B Instruct. Special care has been given to the alignment and the removal of toxic content for the Meltemi 7B Instruct. The developed models are evaluated on a broad set of collected evaluation corpora, and examples of prompts and responses are presented. Both Meltemi 7B and Meltemi 7B Instruct are available at https://huggingface.co/ilsp under the Apache 2.0 license.