 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKrikri: Advancing Open Large Language Models for Greek
May 19, 2025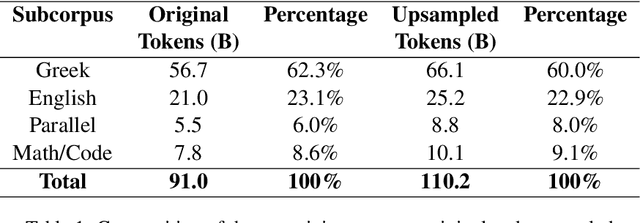
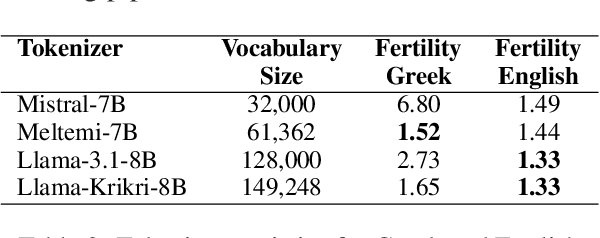
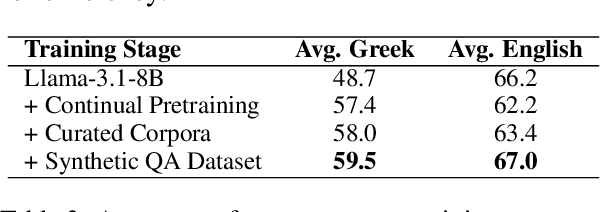

We introduce Llama-Krikri-8B, a cutting-edge Large Language Model tailored for the Greek language, built on Meta's Llama 3.1-8B. Llama-Krikri-8B has been extensively trained on high-quality Greek data to ensure superior adaptation to linguistic nuances. With 8 billion parameters, it offers advanced capabilities while maintaining efficient computational performance. Llama-Krikri-8B supports both Modern Greek and English, and is also equipped to handle polytonic text and Ancient Greek. The chat version of Llama-Krikri-8B features a multi-stage post-training pipeline, utilizing both human and synthetic instruction and preference data, by applying techniques such as MAGPIE. In addition, for evaluation, we propose three novel public benchmarks for Greek. Our evaluation on existing as well as the proposed benchmarks shows notable improvements over comparable Greek and multilingual LLMs in both natural language understanding and generation as well as code generation.
Meltemi: The first open Large Language Model for Greek
Jul 30, 2024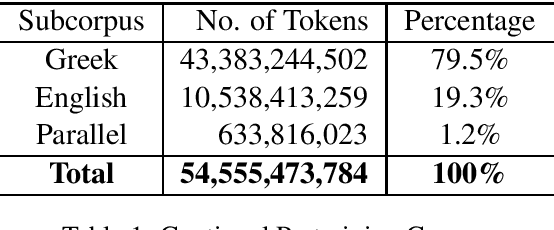
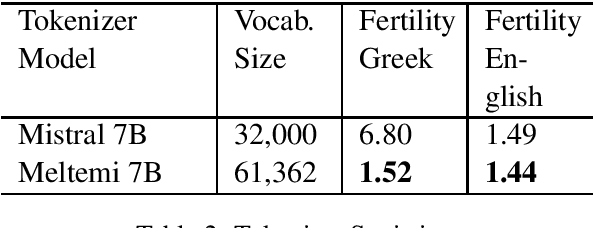
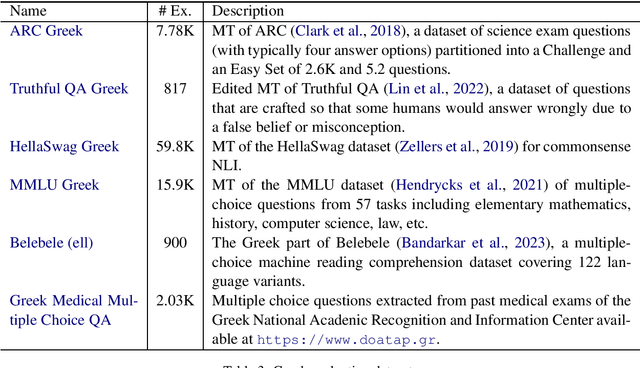
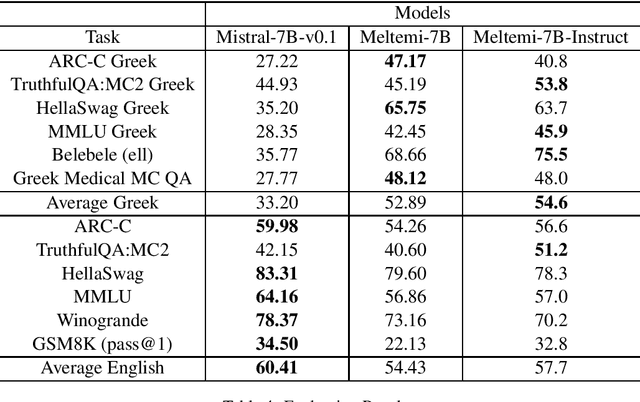
We describe the development and capabilities of Meltemi 7B, the first open Large Language Model for the Greek language. Meltemi 7B has 7 billion parameters and is trained on a 40 billion token Greek corpus. For the development of Meltemi 7B, we adapt Mistral, by continuous pretraining on the Greek Corpus. Meltemi 7B contains up-to-date information up to September 2023. Furthermore, we have translated and curated a Greek instruction corpus, which has been used for the instruction-tuning of a chat model, named Meltemi 7B Instruct. Special care has been given to the alignment and the removal of toxic content for the Meltemi 7B Instruct. The developed models are evaluated on a broad set of collected evaluation corpora, and examples of prompts and responses are presented. Both Meltemi 7B and Meltemi 7B Instruct are available at https://huggingface.co/ilsp under the Apache 2.0 license.
Findings of the Covid-19 MLIA Machine Translation Task
Nov 14, 2022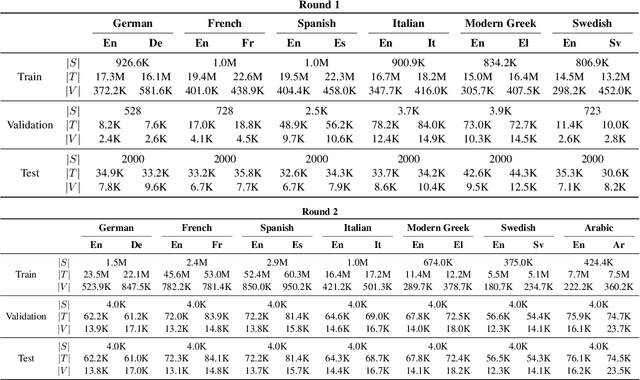
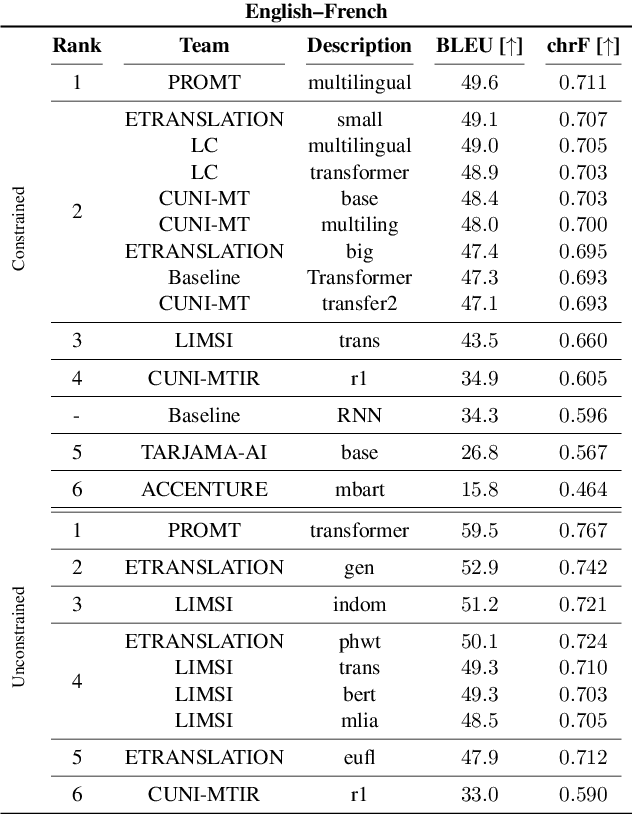
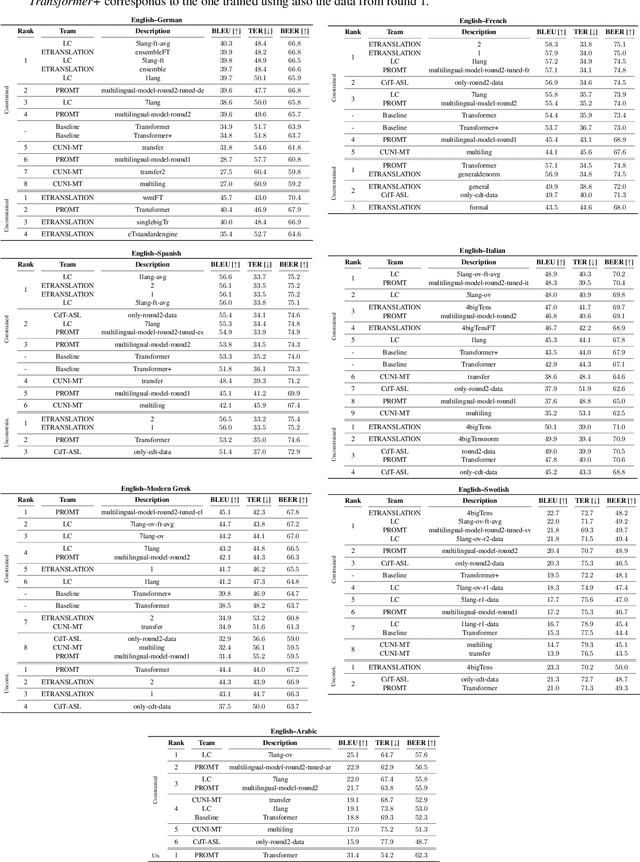
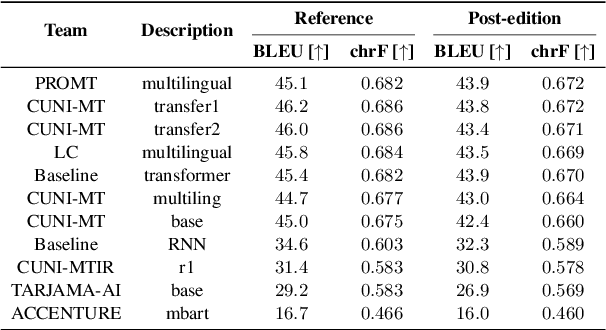
This work presents the results of the machine translation (MT) task from the Covid-19 MLIA @ Eval initiative, a community effort to improve the generation of MT systems focused on the current Covid-19 crisis. Nine teams took part in this event, which was divided in two rounds and involved seven different language pairs. Two different scenarios were considered: one in which only the provided data was allowed, and a second one in which the use of external resources was allowed. Overall, best approaches were based on multilingual models and transfer learning, with an emphasis on the importance of applying a cleaning process to the training data.
Towards an Interoperable Ecosystem of AI and LT Platforms: A Roadmap for the Implementation of Different Levels of Interoperability
Apr 17, 2020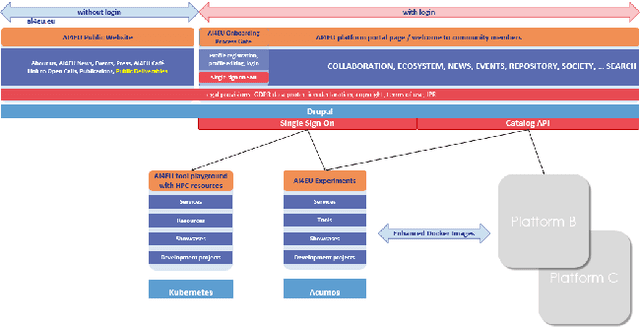
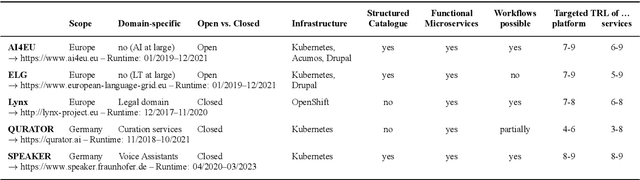

With regard to the wider area of AI/LT platform interoperability, we concentrate on two core aspects: (1) cross-platform search and discovery of resources and services; (2) composition of cross-platform service workflows. We devise five different levels (of increasing complexity) of platform interoperability that we suggest to implement in a wider federation of AI/LT platforms. We illustrate the approach using the five emerging AI/LT platforms AI4EU, ELG, Lynx, QURATOR and SPEAKER.
The European Language Technology Landscape in 2020: Language-Centric and Human-Centric AI for Cross-Cultural Communication in Multilingual Europe
Mar 30, 2020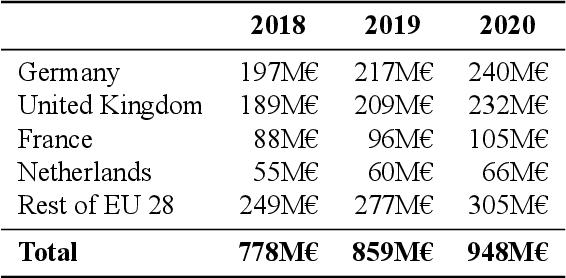
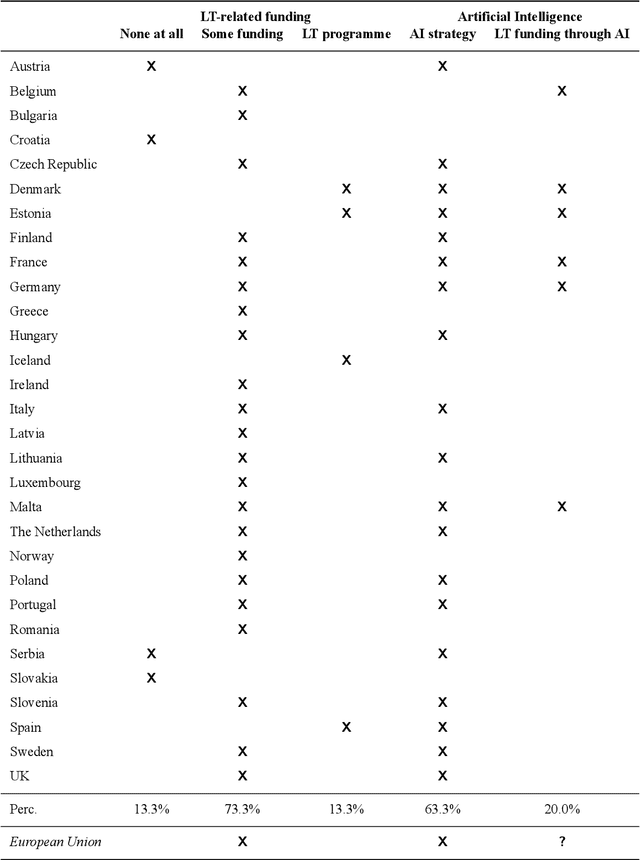
Multilingualism is a cultural cornerstone of Europe and firmly anchored in the European treaties including full language equality. However, language barriers impacting business, cross-lingual and cross-cultural communication are still omnipresent. Language Technologies (LTs) are a powerful means to break down these barriers. While the last decade has seen various initiatives that created a multitude of approaches and technologies tailored to Europe's specific needs, there is still an immense level of fragmentation. At the same time, AI has become an increasingly important concept in the European Information and Communication Technology area. For a few years now, AI, including many opportunities, synergies but also misconceptions, has been overshadowing every other topic. We present an overview of the European LT landscape, describing funding programmes, activities, actions and challenges in the different countries with regard to LT, including the current state of play in industry and the LT market. We present a brief overview of the main LT-related activities on the EU level in the last ten years and develop strategic guidance with regard to four key dimensions.
European Language Grid: An Overview
Mar 30, 2020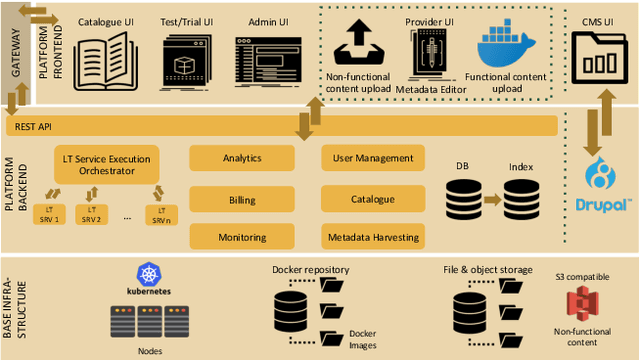

With 24 official EU and many additional languages, multilingualism in Europe and an inclusive Digital Single Market can only be enabled through Language Technologies (LTs). European LT business is dominated by hundreds of SMEs and a few large players. Many are world-class, with technologies that outperform the global players. However, European LT business is also fragmented, by nation states, languages, verticals and sectors, significantly holding back its impact. The European Language Grid (ELG) project addresses this fragmentation by establishing the ELG as the primary platform for LT in Europe. The ELG is a scalable cloud platform, providing, in an easy-to-integrate way, access to hundreds of commercial and non-commercial LTs for all European languages, including running tools and services as well as data sets and resources. Once fully operational, it will enable the commercial and non-commercial European LT community to deposit and upload their technologies and data sets into the ELG, to deploy them through the grid, and to connect with other resources. The ELG will boost the Multilingual Digital Single Market towards a thriving European LT community, creating new jobs and opportunities. Furthermore, the ELG project organises two open calls for up to 20 pilot projects. It also sets up 32 National Competence Centres (NCCs) and the European LT Council (LTC) for outreach and coordination purposes.
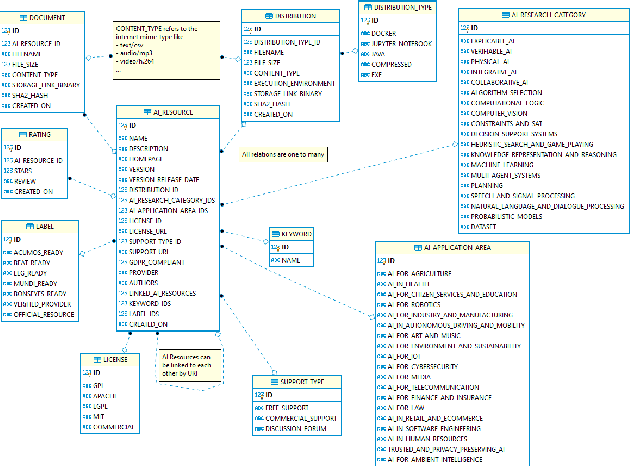
Making Metadata Fit for Next Generation Language Technology Platforms: The Metadata Schema of the European Language Grid
Mar 30, 2020
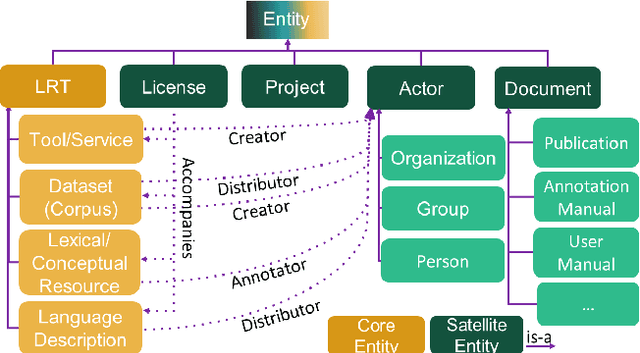
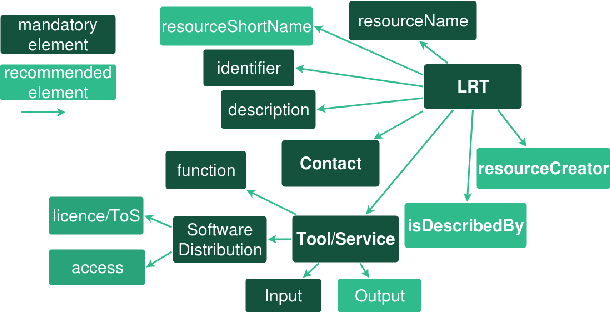

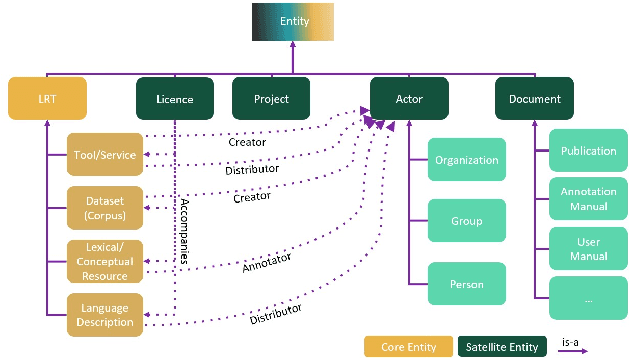
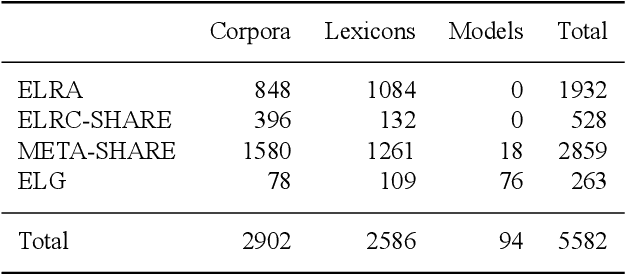
The current scientific and technological landscape is characterised by the increasing availability of data resources and processing tools and services. In this setting, metadata have emerged as a key factor facilitating management, sharing and usage of such digital assets. In this paper we present ELG-SHARE, a rich metadata schema catering for the description of Language Resources and Technologies (processing and generation services and tools, models, corpora, term lists, etc.), as well as related entities (e.g., organizations, projects, supporting documents, etc.). The schema powers the European Language Grid platform that aims to be the primary hub and marketplace for industry-relevant Language Technology in Europe. ELG-SHARE has been based on various metadata schemas, vocabularies, and ontologies, as well as related recommendations and guidelines.
A Matching Technique in Example-Based Machine Translation
Aug 10, 1995
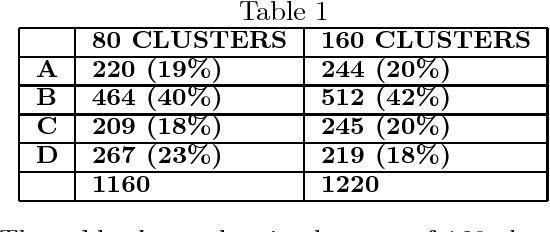
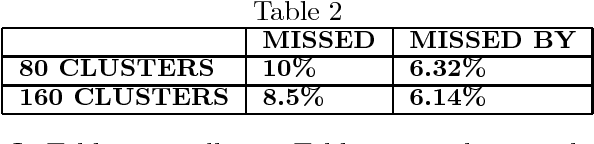
This paper addresses an important problem in Example-Based Machine Translation (EBMT), namely how to measure similarity between a sentence fragment and a set of stored examples. A new method is proposed that measures similarity according to both surface structure and content. A second contribution is the use of clustering to make retrieval of the best matching example from the database more efficient. Results on a large number of test cases from the CELEX database are presented.